Manifest List
In the hierarchical metadata tree of Apache Iceberg, the Snapshot defines the state of the table, but it does not directly list the millions of data files. Instead, the Snapshot points to a single file called the Manifest List.
The Manifest List is an Avro-formatted file that acts as an index of indexes. Its primary job is to track a collection of lower-level files (Manifest Files) that contain the actual pointers to the Parquet data files. However, if the Manifest List were merely a list of file paths, query engines would still have to open and read every single Manifest File to figure out where the relevant data lives.
What makes the Manifest List a critical piece of the Iceberg architecture is that it stores summary statistics for every Manifest File it points to. This design transforms the query planning phase from an exhaustive search into a highly optimized, targeted lookup.
The Structure of a Manifest List
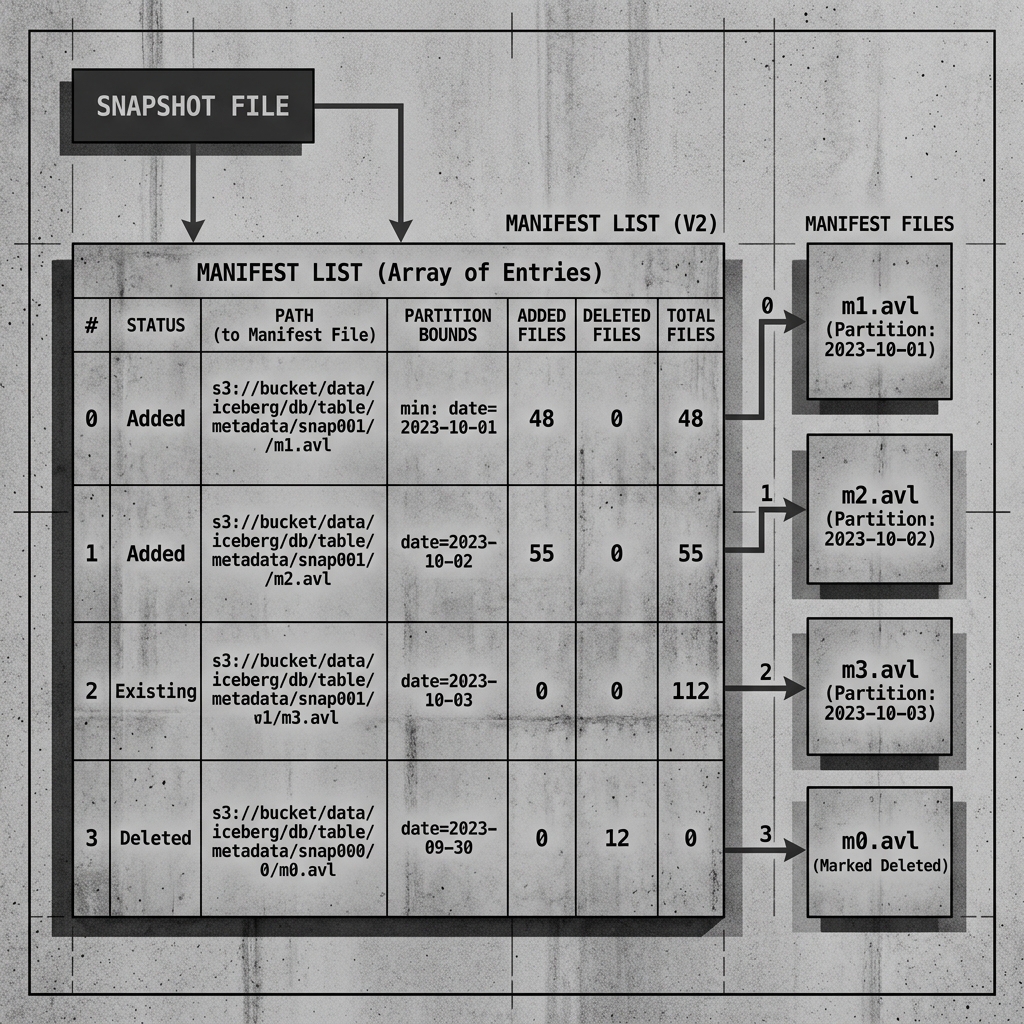
A Manifest List contains an array of rows, where each row represents one Manifest File. For every Manifest File, the Manifest List tracks several crucial pieces of information:
- File Path: The absolute URI of the Manifest File in object storage.
- Status: Whether the Manifest File was added, existing, or deleted in this specific Snapshot.
- File Counts: The number of added, existing, and deleted data files contained within that specific Manifest File.
- Partition Bounds: The minimum and maximum values for the partition columns of all the data files tracked by that Manifest File.
Diagram 1: Manifest List Architecture
The Mechanics of Data Skipping (Pruning)
The inclusion of Partition Bounds (min/max stats) directly inside the Manifest List is the key to Iceberg’s query performance.
Imagine a massive sales table partitioned by transaction_date. The table contains ten years of data, spread across 1,000 Manifest Files. An analyst executes the following query:
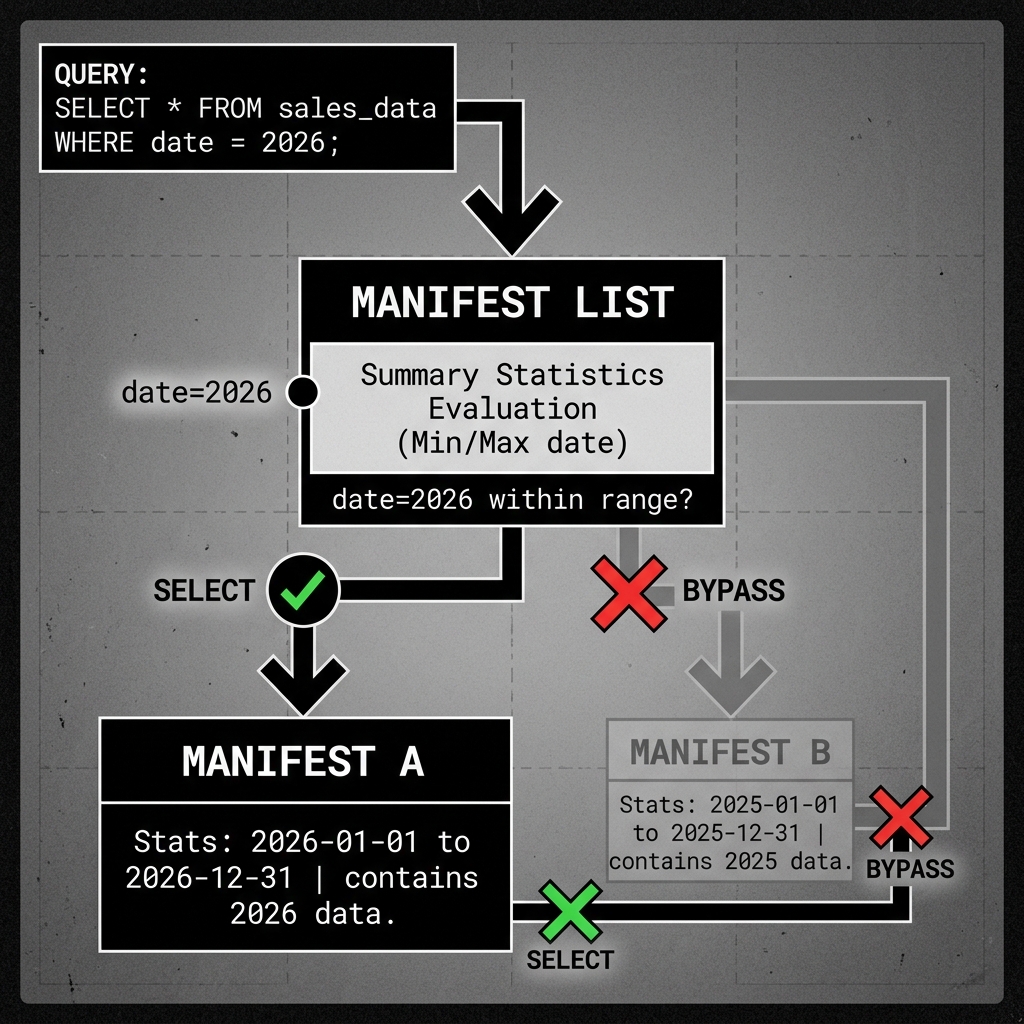
SELECT sum(revenue) FROM sales WHERE transaction_date = '2026-05-18';Without the summary statistics in the Manifest List, the query engine would have to download and read all 1,000 Manifest Files to figure out which ones contain data for May 18, 2026. This would require 1,000 separate I/O operations to Amazon S3 just for the query planning phase.
With Apache Iceberg, the engine downloads only the single Manifest List. It reads the array of entries in memory. It looks at the Partition Bounds for the first Manifest File: min: 2018-01-01, max: 2018-12-31. Because 2026-05-18 does not fall within that range, the engine instantly skips that Manifest File. It repeats this check in memory for all 1,000 entries.
In a fraction of a second, the engine might determine that 998 Manifest Files can be completely ignored. It only needs to download and read the 2 specific Manifest Files that actually contain data for May 2026.
This process—using high-level statistics to safely ignore massive swaths of metadata—is called Metadata Pruning.
Diagram 2: Manifest List Pruning
Efficiency in Write Operations
The Manifest List also optimizes write operations. When an ingestion job appends new data to an Iceberg table, it does not need to rewrite the entire metadata tree.
The job creates a new Manifest File containing pointers to the newly uploaded Parquet files. It then creates a new Manifest List. This new Manifest List simply copies the pointers to the 1,000 existing Manifest Files from the previous snapshot, and appends one new row pointing to the newly created Manifest File.
Because Avro files are immutable, the old Manifest Files are completely reused. The engine only had to write one new Manifest File and one new Manifest List to commit the transaction, regardless of how massive the table is. This structural reuse keeps commit times extremely fast and prevents metadata bloat, ensuring the lakehouse can scale to exabytes of data seamlessly.