Medallion Architecture
When organizations first started building data lakehouses, they faced a structuring problem. Raw data arrived in all kinds of shapes: nested JSON from APIs, CSV exports from legacy systems, binary Avro records from event streams, and compressed log files from servers. All of it ended up in the same object storage bucket, alongside the cleansed, curated tables that analysts actually wanted to query. Without a clear organizational structure, the lake quickly became impossible to navigate.
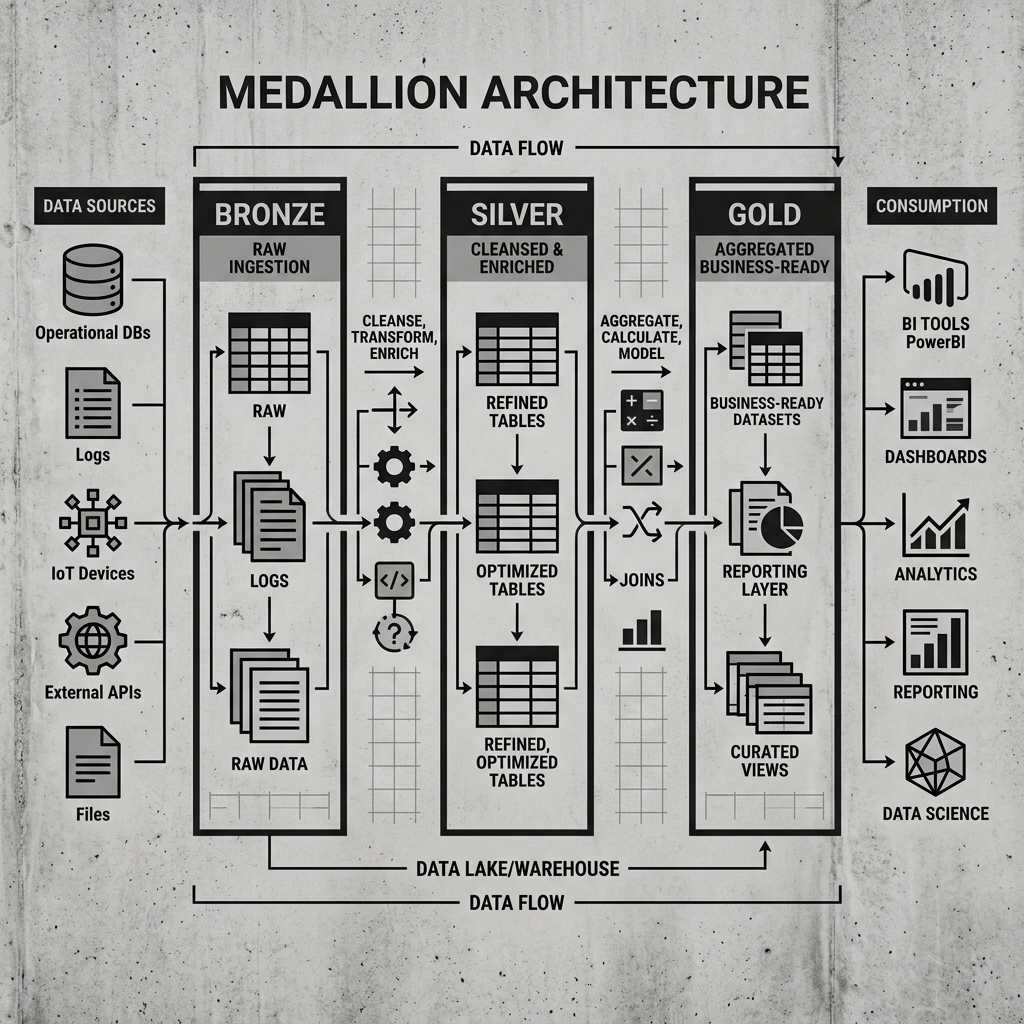
The Medallion Architecture, popularized by Databricks as part of their lakehouse platform design, is a data design pattern that organizes data within a lakehouse into three distinct layers, each representing a progressively higher level of data quality and refinement. These layers are called Bronze, Silver, and Gold, representing the progression from raw and unprocessed to fully curated and business-ready.
The architecture solves three problems simultaneously. It gives data engineers a predictable, reproducible structure for their pipelines. It gives data consumers a clear understanding of what to expect from data at each layer. And it preserves the raw historical record permanently in the Bronze layer, which allows any downstream processing error to be corrected by reprocessing from the source rather than requiring a re-extraction from the origin system.
Bronze: The Raw Ingestion Layer
The Bronze layer is the entry point for all data entering the lakehouse. Data lands here exactly as it arrived from the source system: no transformations, no schema enforcement, no deduplication. If the source system sends a JSON object with nested arrays and inconsistently named fields, that JSON object is stored as-is in the Bronze table.
The Bronze layer is intentionally append-only. Data engineering teams configure ingestion pipelines, whether streaming via Apache Flink or batch via Apache Spark, to write records to Bronze without modifying them. The only operations permitted in the Bronze layer are appends and metadata updates.
Because Bronze is stored using an open table format like Apache Iceberg, it benefits from ACID transactions and time travel even though the data itself is raw. This means concurrent streaming and batch jobs can safely append to the same Bronze table without corrupting each other’s writes. It also means that if a downstream pipeline produces incorrect results because of a data quality issue, data engineers can use Iceberg’s time travel to query the Bronze table as it existed at any point in the past to isolate exactly when and how the bad data entered the system.
The Bronze layer is typically not queryable by business analysts. Access is restricted to data engineers who use it as the input for Bronze-to-Silver transformation jobs.
Silver: The Cleansed and Enriched Layer
The Silver layer is where data quality enforcement happens. Automated transformation pipelines read incrementally from Bronze, apply a series of cleaning and enrichment operations, and write the results to Silver tables.
At the Silver layer, data engineers apply schema enforcement. Records that do not conform to the expected schema are either rejected into a separate quarantine table for investigation or remediated according to predefined rules. Duplicate records are identified and removed. Date and timestamp columns are standardized. Personally identifiable information is masked or replaced with tokenized identifiers according to the organization’s data privacy policy.
Silver tables also bring together data from multiple Bronze sources through joins and lookups. A Silver customer_orders table might join Bronze order records with Bronze customer profiles, enriching each order with the customer’s segment, region, and account status at the time of the order. This enrichment produces a dataset that is richer and more analytically useful than either source alone.
Silver data represents the enterprise’s single source of truth. It is the layer that multiple downstream teams and Gold-layer pipelines read from. Because all Gold tables ultimately derive from Silver, ensuring Silver data quality is the highest-leverage investment a data engineering team can make.
Diagram 1: Medallion Architecture Overview
Gold: The Business-Ready Layer
The Gold layer contains data that has been modeled specifically for consumption by business analysts, dashboards, and machine learning systems. Pipelines read from Silver and apply business-level aggregations, dimensional modeling, and performance optimizations to produce highly denormalized, pre-aggregated tables.
A Gold table might contain the daily sales total by region and product category, pre-computed to enable sub-second query response times in a BI tool. Another Gold table might contain the monthly churn rate calculated according to the finance department’s approved definition. Because these calculations are baked into the Gold table itself rather than computed at query time, business consumers get consistent, fast results without needing to understand the underlying calculation logic.
Gold tables are often organized by subject area or business domain: a sales_analytics Gold schema, a finance_reporting Gold schema, a product_metrics Gold schema. This domain organization makes it easy for business teams to discover the data relevant to their work.
Diagram 2: Streaming and Batch in a Medallion Pipeline
Streaming and Batch in the Medallion Architecture
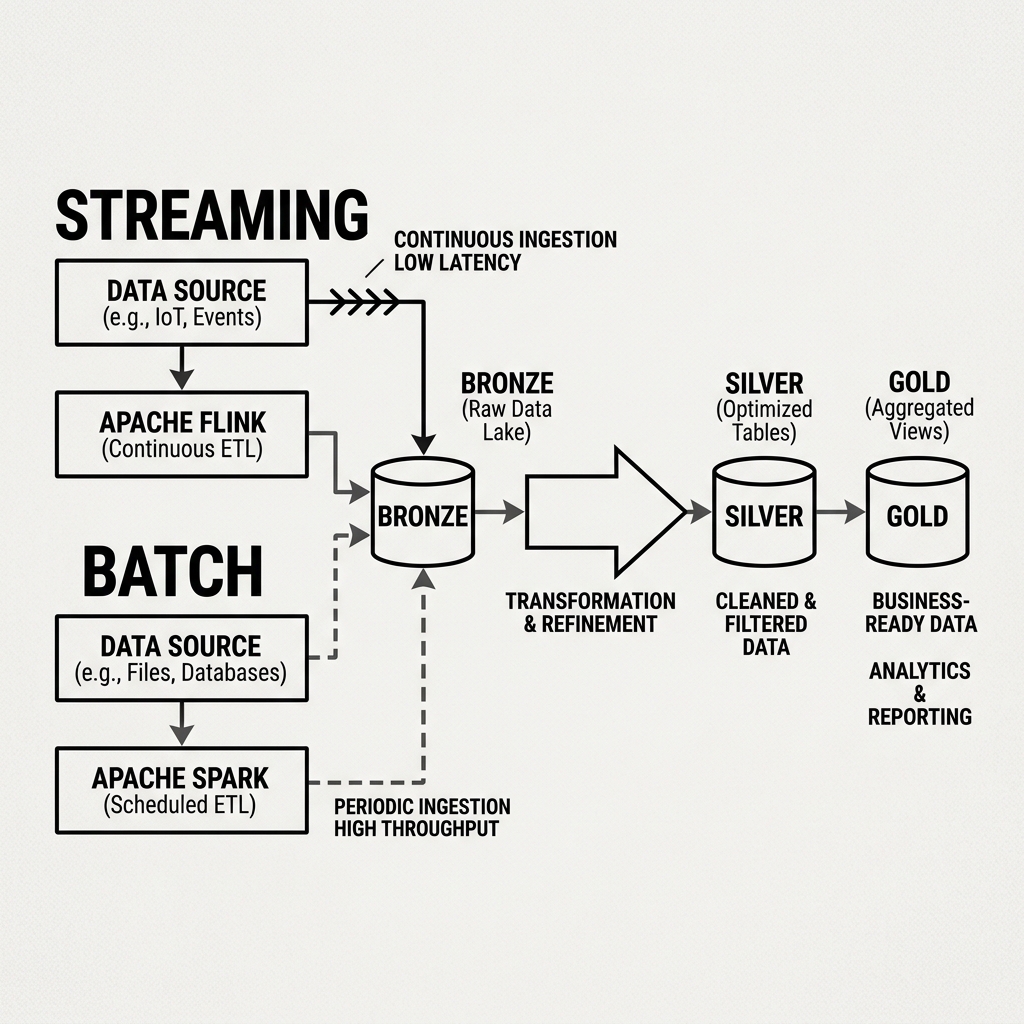
One of the most powerful operational properties of the Medallion Architecture is its ability to accommodate both streaming and batch ingestion patterns simultaneously, feeding into the same layered structure.
Streaming pipelines, typically built on Apache Flink or Spark Structured Streaming, continuously append micro-batches or individual events to Bronze tables as they arrive. This provides near-real-time data availability for time-sensitive use cases.
Batch pipelines, typically built on Apache Spark, run on a schedule (hourly, daily, or weekly) and process large volumes of historical data at once. They are more efficient for bulk backfills and large-scale historical reprocessing.
Because both streaming and batch pipelines write to the same Bronze Iceberg table using ACID transactions, there is no risk of conflict or data corruption. The Silver and Gold transformation jobs that read from Bronze do not need to know or care whether the data they are processing was written by a streaming job or a batch job. They simply query the latest snapshot of the Bronze table and process whatever incremental records have arrived since their last run.
This unified batch-and-stream architecture is one of the primary reasons the Medallion Architecture has become the dominant organizational pattern for data lakehouses built on Apache Iceberg or Delta Lake.