Merge-on-Read (MoR)
While Copy-on-Write (CoW) provides blistering read performance, its massive Write Amplification makes it unsuitable for high-frequency updates, such as near-real-time Change Data Capture (CDC) pipelines. If a database stream is constantly updating individual rows every few seconds, forcing the engine to rewrite 500MB Parquet files for every micro-batch will crash the pipeline.
To solve this, Apache Iceberg (starting in the V2 specification) introduced Merge-on-Read (MoR).
The MoR Mechanism
Merge-on-Read flips the architectural trade-off of CoW: It sacrifices read performance to guarantee extremely fast write performance.
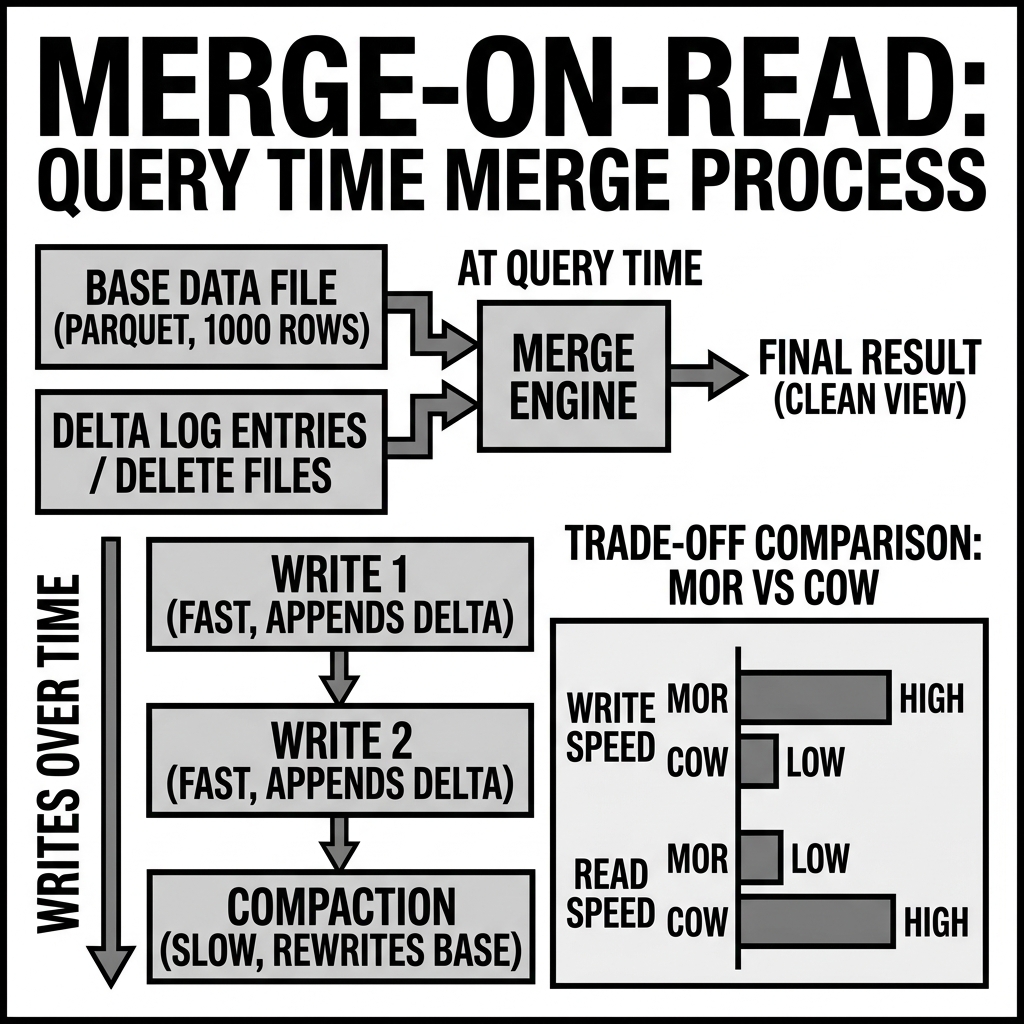
When an UPDATE or DELETE is executed against an Iceberg table configured for MoR, the underlying data files are completely ignored. Instead, the engine simply writes a tiny new file called a Delete File.
If you delete customer ID 12345, Iceberg writes a few bytes to a Delete File noting “Row X in File Y is deleted.” This operation takes milliseconds. There is absolutely zero write amplification because the original 500MB data file is completely untouched.
The Cost at Read Time
The complexity of MoR occurs when an analyst executes a SELECT query.
Because the original data file still contains the deleted row (customer ID 12345), the query engine must perform an on-the-fly reconciliation.
- The engine reads the 500MB data file.
- The engine reads the associated Delete Files.
- The engine mathematically subtracts (merges) the deleted records from the data stream in memory before returning the results to the analyst.
This runtime merging consumes CPU cycles and slows down query performance. Over time, as thousands of Delete Files accumulate, query performance degrades significantly.
The MoR Lifecycle
Because MoR query performance degrades over time, it cannot be run indefinitely without maintenance.
Data engineering teams running MoR must schedule regular Compaction jobs. During off-peak hours, a background Spark job will read the data files and the accumulated Delete Files, perform the heavy CoW-style rewrite to create a perfectly clean new data file, and physically delete the old files.
Merge-on-Read is an elegant mechanism to absorb high-velocity writes, temporarily deferring the heavy compute cost until a scheduled compaction job can handle it efficiently.
(Diagram 1: The Merge-on-Read execution flow - Pending Generation) (Diagram 2: The reconciliation process during a read query - Pending Generation)
Visual Architecture