Metadata Layer
If data files (like Parquet or ORC) are the muscle of a data lakehouse, and compute engines (like Spark or Dremio) are the brain, the Metadata Layer is the central nervous system connecting the two. It is the defining architectural component that transforms a disorganized “data swamp” into a highly structured, transactional data lakehouse.
In computer science, metadata is simply “data about data.” In the context of a lakehouse, the Metadata Layer is a structured, versioned collection of files that definitively describes the state, schema, and physical location of the data files that make up a table. When a compute engine interacts with a lakehouse table, it never touches the raw data files directly without first consulting the Metadata Layer.
To understand why the Metadata Layer is so critical, it helps to understand the historical problem it was designed to solve: the performance penalty of directory listing on object storage.
The Problem with Directory Listing
Early data lakes, built on the Apache Hive model, defined tables using a directory structure. A sales table was a directory. If the table was partitioned by date, there were subdirectories like date=2026-05-18.
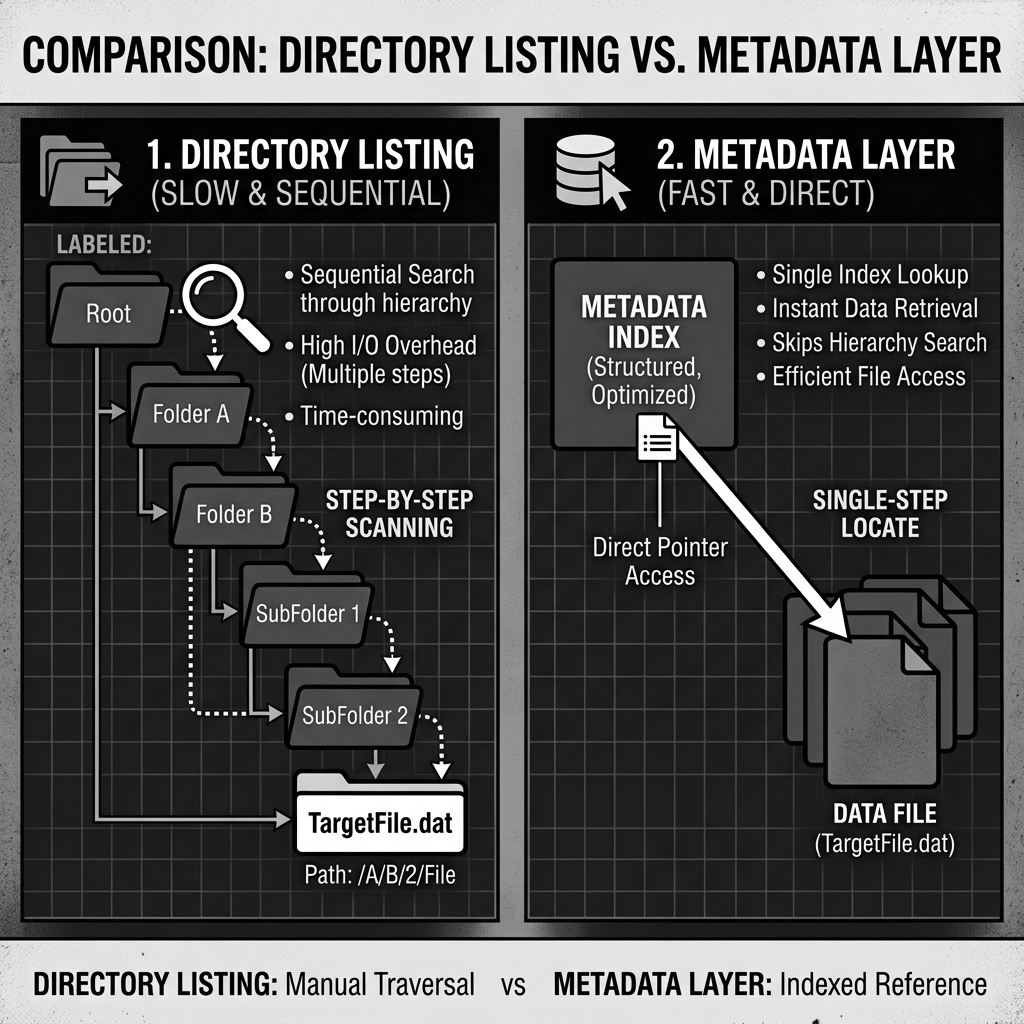
When an analyst ran a query for yesterday’s sales, the query engine had to make an API call to the cloud object storage (like Amazon S3) asking for a list of all files inside the date=2026-05-18 directory. Cloud object stores are incredibly scalable for reading and writing individual files, but they are notoriously slow at listing the contents of directories. If a directory contained fifty thousand small files, the listing operation alone could take minutes before a single byte of actual data was read.
Worse, this directory-based approach provided no transaction isolation. If a writer was in the middle of uploading files to that directory when a reader requested a list, the reader might see half the new files and half the old files, resulting in a corrupted, inaccurate query result.
Diagram 1: Directory Listing vs Metadata Layer
The Solution: Explicit File Tracking
The Metadata Layer solves this by abandoning implicit directory structures in favor of explicit file tracking. Instead of relying on the file system to define the table, the table is defined by a specific metadata file.
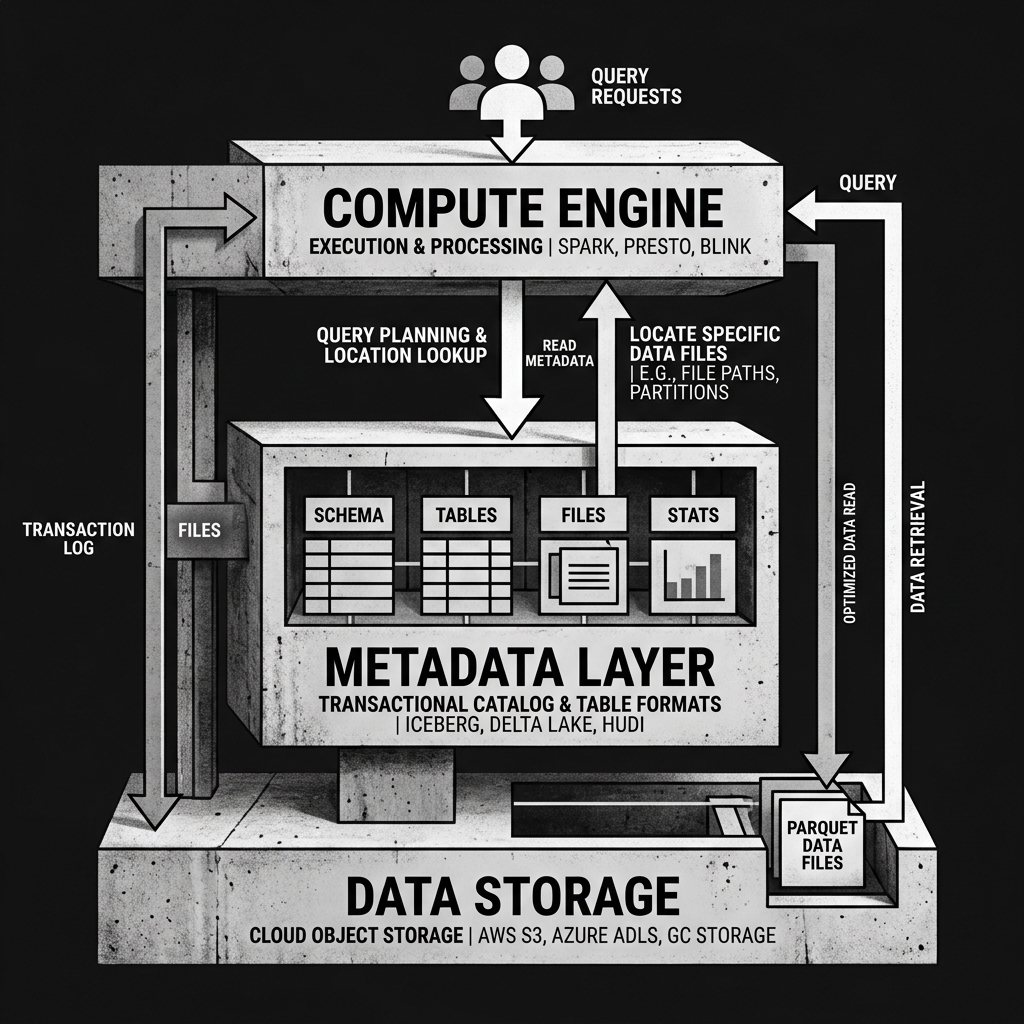
When a query engine wants to read the sales table, it does not ask S3 to list directories. Instead, it reads the current metadata file. This metadata file contains an exact, explicit list of the URIs of every valid data file that currently belongs to the table. The query engine reads this list, bypasses the directory listing entirely, and directly requests the specific data files it needs from object storage.
This shift from O(N) directory listing to O(1) explicit pointer lookup is what allows data lakehouses to query petabyte-scale tables with millions of files in milliseconds.
Diagram 2: Metadata Layer Architecture
What the Metadata Layer Contains
While different table formats (Apache Iceberg, Delta Lake, Apache Hudi) implement their metadata layers differently, they all store similar categories of information:
Schema Definition: The Metadata Layer acts as the ultimate source of truth for the table’s schema. It tracks the names, data types, and unique IDs of every column. When a user executes an ALTER TABLE command to add or drop a column, the engine simply updates the schema definition in the Metadata Layer.
Partitioning Configuration: The Metadata Layer defines how the data is logically grouped. In advanced formats like Iceberg, it tracks “hidden partitioning” rules, allowing the engine to understand that a date partition is derived from an event_timestamp column without requiring the user to explicitly query the partition column.
File-Level Statistics: This is perhaps the most powerful optimization the Metadata Layer provides. For every data file it tracks, the metadata also stores statistics: the total record count, the number of nulls, and the minimum and maximum values for key columns. When a query includes a filter (e.g., WHERE customer_id = 999), the engine checks the min/max statistics in the metadata first. If a file’s min customer_id is 1000 and max is 2000, the engine knows it doesn’t need to read that file. This “data skipping” dramatically reduces I/O.
Snapshot History: The Metadata Layer does not just track the current state of the table; it tracks a history of previous states, known as snapshots. Each snapshot represents a committed transaction. Because the metadata retains pointers to the files that belonged to previous snapshots, users can “Time Travel” by querying the metadata as it looked at a specific point in the past.
By centralizing schema management, enabling ACID transactions, and providing aggressive performance optimizations through file-level tracking, the Metadata Layer is the indispensable core of the modern data lakehouse architecture.