Metadata Pointer
In an open data lakehouse architecture based on Apache Iceberg, a single table might consist of millions of Parquet data files, thousands of Avro manifest files, and dozens of JSON metadata files scattered across an Amazon S3 bucket. At any given moment, how does a compute engine know which of those JSON metadata files represents the current, active state of the table?
The answer is the Metadata Pointer.
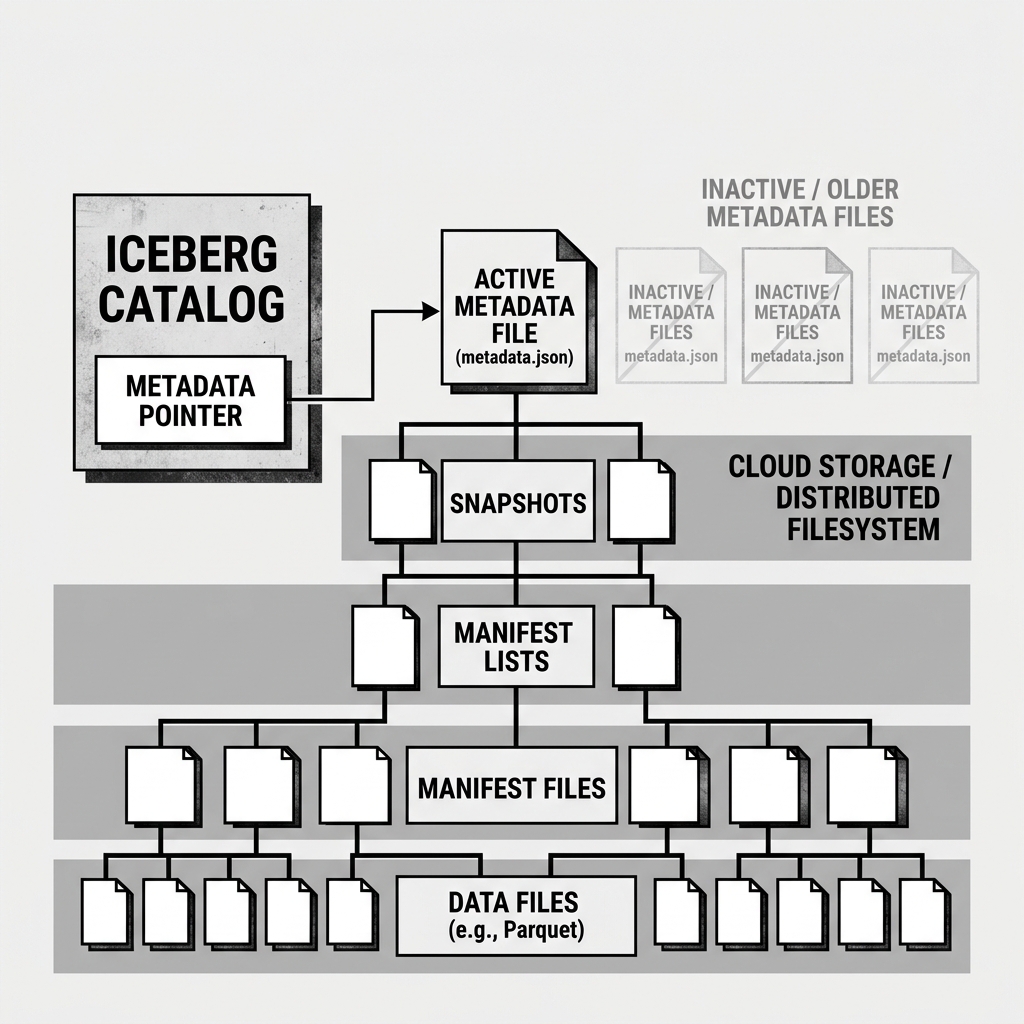
The Metadata Pointer is not a file; it is a reference string (a URI) stored inside the lakehouse Catalog. It serves as the absolute, single source of truth for the table’s state. When an engine like Apache Spark or Trino wants to read an Iceberg table, it must first ask the catalog for the Metadata Pointer. The catalog responds with the URI of a single JSON file (e.g., s3://bucket/table/metadata/v12.metadata.json). That specific JSON file is the root of the metadata tree for the current active snapshot.
The Role of the Pointer in Concurrency
The Metadata Pointer is the lynchpin of ACID transactions in a data lakehouse. Because object storage systems like S3 are highly distributed, they do not inherently provide atomic locking mechanisms. If two different Spark jobs try to overwrite the same metadata file simultaneously, data corruption will occur.
Iceberg solves this by making metadata files immutable. Once a metadata.json file is written, it is never modified. When a transaction changes the table, it writes a completely new metadata file (e.g., v13.metadata.json) containing the updated state.
However, writing the new JSON file to S3 does not actually change the table. The table is only considered changed when the Metadata Pointer inside the Catalog is updated to point to that new v13.metadata.json file.
Diagram 1: Metadata Pointer Architecture
The Atomic Swap (Compare-and-Swap)
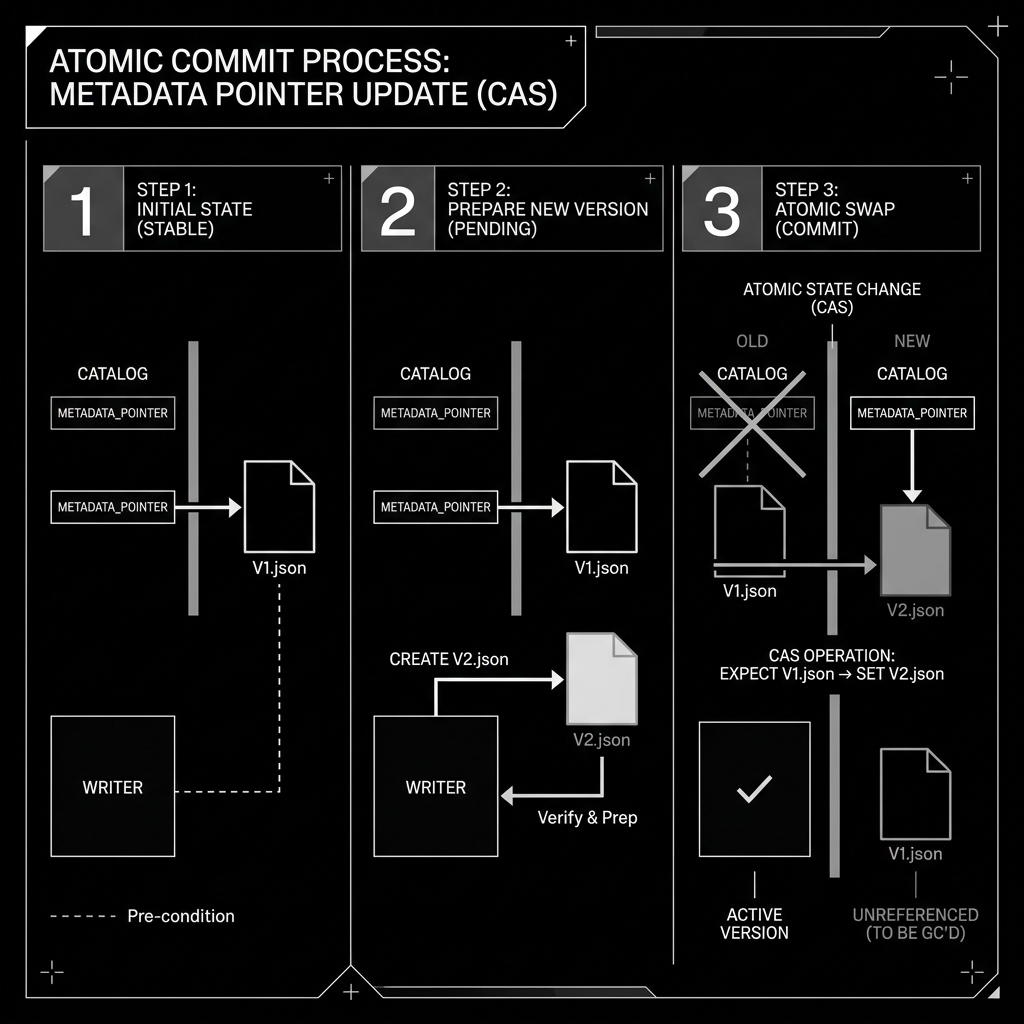
To ensure transaction isolation when multiple writers are operating concurrently, the update of the Metadata Pointer must be an atomic operation. This is almost always implemented via a mechanism called Compare-and-Swap (CAS).
Consider a scenario where two writers, Job A and Job B, are both attempting to append data to the table at the exact same time.
- Both jobs ask the catalog for the current pointer. The catalog says the current pointer is
v12.json. - Job A prepares its new data files, builds its new metadata tree, and writes
v13_A.jsonto storage. - Job B simultaneously prepares its new data files, builds its new metadata tree, and writes
v13_B.jsonto storage.
Now, both jobs attempt to commit their changes by asking the Catalog to update the Metadata Pointer. They do not just say “update the pointer to my new file.” They issue a CAS request: “Update the pointer to my new file, but only if the current pointer is still v12.json.”
If Job A’s request reaches the Catalog milliseconds before Job B’s:
- The Catalog processes Job A’s request. The current pointer is
v12.json, which matches Job A’s expectation. The Catalog atomically updates the pointer tov13_A.json. Job A succeeds. - The Catalog processes Job B’s request. Job B expects the pointer to be
v12.json. However, the pointer is nowv13_A.json. The CAS operation fails.
Job B is rejected. It knows its transaction failed. Job B must now read the new v13_A.json file, reconcile its changes against the new state, generate a new v14_B.json file, and retry the CAS operation.
This atomic pointer swap guarantees that readers always see a consistent state (they either see the state before the pointer swap, or the state after) and writers never silently overwrite each other.
Diagram 2: Atomic Commit Process
Catalog Implementations
Because the Metadata Pointer is the root of the transactional system, the Catalog holding that pointer must support atomic operations.
If you use a simple file system as a catalog (where the pointer is just a text file called version-hint.txt), you do not get true atomic guarantees on many object stores, making it unsafe for concurrent writers.
This is why production lakehouses use robust catalogs to store the Metadata Pointer. Systems like the open-source Polaris Catalog, Project Nessie, AWS Glue, and the Iceberg REST Catalog API all provide the necessary locking and atomic CAS operations required to safely manage the Metadata Pointer, ensuring the structural integrity of the entire data lakehouse.