Min-Max Statistics
Min-Max Statistics are per-column metadata stored alongside data in Parquet files and in Iceberg Manifest Files, recording the minimum value, maximum value, and null count for each column within each unit of storage (a Parquet row group, or an Iceberg-tracked data file). These statistics are the primary mechanism through which query engines perform data skipping — the ability to eliminate large volumes of irrelevant data before reading a single data byte.
Min-Max Statistics are the workhorses of lakehouse query performance. They are simpler than Bloom Filters, less sophisticated than multi-dimensional clustering, and less mathematically elegant than space-filling curves. But they are universally present on every Parquet file ever written, require no special configuration, and deliver substantial IO reduction for the most common category of analytical query predicates: range filters on sorted or partitioned columns.
Understanding Min-Max Statistics at a deep technical level — their storage structure, their interaction with data ordering and partitioning, their limitations, and the multiple layers at which they operate in a modern lakehouse — is foundational knowledge for any data engineer responsible for query performance optimization.
The Storage Structure: Where Statistics Live
Parquet Row Group Footer Statistics
A Parquet file is organized into Row Groups — horizontal slices of the table’s rows, each typically 128–512MB in size. Each Row Group contains Column Chunks — the actual compressed, encoded column data. After all the Row Group data is written, the Parquet writer appends a file footer containing a complete index of all Row Groups and their statistics.
For each Column Chunk within each Row Group, the Parquet footer stores:
min_value: The minimum value of any element in this column chunk. For numeric columns, this is the arithmetic minimum (the smallest number). For string columns, this is the lexicographically smallest string. For date/timestamp columns, this is the earliest datetime value.
max_value: The maximum value of any element in this column chunk, using the same comparison semantics as min_value.
null_count: The number of null values in this column chunk. A column chunk where null_count equals the total row count has no non-null values at all.
distinct_count (optional): An estimated count of the number of distinct values in the column chunk. This is less universally supported and less commonly used for skipping decisions, but is valuable for query optimizer cardinality estimation.
These statistics are written in the footer in a compact binary format (as part of the Parquet Thrift metadata schema). The footer itself is typically a few kilobytes to a few hundred kilobytes for a large file with many columns — a tiny fraction of the actual data size.
Iceberg Manifest File Statistics
Apache Iceberg stores an additional layer of Min-Max Statistics at the Manifest File level. Each entry in an Iceberg Manifest File corresponds to one physical data file and stores:
lower_bounds: A map from column field ID to the minimum value of that column across all rows in the data file (equivalent to the Parquet file’s aggregate min across all row groups).
upper_bounds: A map from column field ID to the maximum value of that column across all rows in the data file.
null_value_counts: A map from column field ID to the number of null values across all rows.
nan_value_counts (for floating-point columns): A map from column field ID to the number of NaN (not-a-number) values.
value_counts: A map from column field ID to the total count of values (null + non-null) in the data file.
These Manifest-level statistics allow query engines to perform file-level skipping at the metadata planning stage, before any data file is opened. If the Manifest entry for a file shows that the file’s sale_date max value is 2026-04-30, the file is completely irrelevant for a query filtering WHERE sale_date >= '2026-05-01' — and the engine will never read the file’s Parquet footer, never decompress any column data, and never consume any network bandwidth or compute cycles on that file.
The Manifest List Level
Iceberg stores an additional layer of aggregate statistics at the Manifest List level. The Manifest List (the Avro file tracking all Manifest Files for a given Snapshot) stores per-manifest aggregate statistics: the min and max values of each column across all data files tracked in that manifest. This allows query engines to skip entire Manifests (which track thousands of files) in a single metadata read operation, before even loading the Manifest Files themselves.
This three-tier statistics hierarchy (Manifest List → Manifest Files → Parquet Row Groups) is one of Iceberg’s primary architectural advantages over Delta Lake’s flat transaction log approach. An Iceberg query engine can prune irrelevant data at three successively granular levels:
- Manifest-level pruning (skip entire manifests).
- File-level pruning (skip individual data files within the surviving manifests).
- Row group-level pruning (skip row groups within the surviving data files, using Parquet footer statistics).
Delta Lake uses column statistics embedded in each add action in the transaction log, providing file-level skipping. For row-group-level skipping within surviving files, Delta also relies on the embedded Parquet footer statistics.
The Skipping Mechanism: Predicate Evaluation Against Statistics
When a query engine plans a query with filter predicates, it evaluates each predicate against the Min-Max Statistics at each level to determine which storage units (manifests, files, row groups) can be definitively skipped.
The Core Skipping Logic
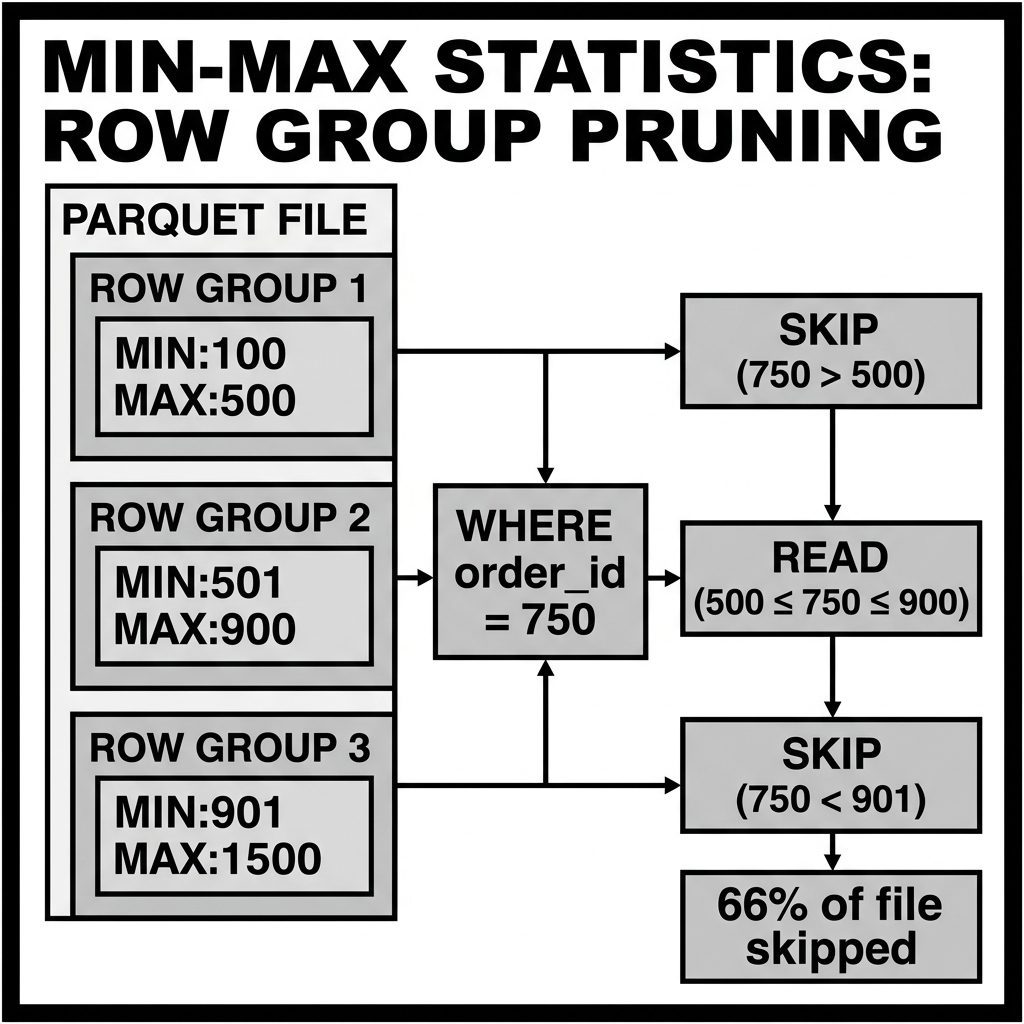
For a predicate WHERE column_A op value:
-
column_A = value(equality): Skip ifmax(column_A) < valueORmin(column_A) > value. The storage unit cannot contain the value if it falls outside the [min, max] range. -
column_A > value(greater-than): Skip ifmax(column_A) <= value. The storage unit’s maximum value is not greater than the threshold. -
column_A < value(less-than): Skip ifmin(column_A) >= value. The storage unit’s minimum value is not less than the threshold. -
column_A BETWEEN value1 AND value2(range): Skip ifmax(column_A) < value1ORmin(column_A) > value2. The storage unit’s entire range is outside the query range. -
column_A IS NOT NULL: Skip ifnull_count = total_row_count. Every value in the storage unit is null. -
column_A IS NULL: Skip ifnull_count = 0. No nulls exist in the storage unit.
For compound predicates (WHERE A > 10 AND B = 'EU'), the skipping logic is applied to each predicate independently. A storage unit is skipped if any single predicate can definitively exclude it.
The Limitation: False Positives Are Unavoidable
Min-Max Statistics suffer from the same fundamental limitation as any range-based skipping mechanism: false positives. A storage unit is only skipped if the statistics definitively prove no matching rows exist. But statistics can only prove non-existence through range exclusion.
If a row group contains values from 1 to 10,000 for column user_id, and the query asks for WHERE user_id = 5,500, the statistics cannot exclude this row group — 5,500 falls within [1, 10,000]. The row group must be read and scanned. Even if user_id 5,500 does not actually appear in the row group (the actual values might be 1, 2, 3, …, 4,999, 5,001, …, 10,000 — missing 5,500), the statistics cannot detect this absence. This is precisely the gap that Bloom Filters fill.
The false positive rate for equality predicates on high-cardinality unordered data approaches 100% — every row group’s min-max range will include the target value, so no row groups are skipped. Min-Max Statistics provide essentially no skipping benefit for point lookups on high-cardinality columns in unordered data.
The Critical Dependency: Data Ordering
The effectiveness of Min-Max Statistics is overwhelmingly determined by how the data is ordered. This is the single most important practical insight for data engineers seeking to improve query performance through statistics-based skipping.
Ordered Data: Maximum Statistics Effectiveness
Consider a table ordered by event_timestamp (ascending). Each Parquet row group will contain a contiguous range of timestamps — row group 1 might span 2026-01-01 00:00:00 to 2026-01-05 23:59:59, row group 2 spans 2026-01-06 00:00:00 to 2026-01-12 23:59:59, and so on.
For a query filtering WHERE event_timestamp BETWEEN '2026-03-01' AND '2026-03-31':
- All row groups from January and February: definitively skipped (max_value < 2026-03-01).
- All row groups from April onward: definitively skipped (min_value > 2026-03-31).
- Only March row groups are scanned.
In a well-partitioned, date-sorted table, this can mean scanning 1/12 of the data for a monthly query. The min-max ranges are perfectly tight (zero overlap between row groups for the sort column), and skipping efficiency approaches 100% for perfectly selective range predicates.
Unordered Data: Degraded Statistics Effectiveness
Consider the same table, but data was ingested in random order — events from all time periods are randomly distributed across all row groups. Each row group might contain timestamps from January, April, September, and December all mixed together. The min-max range for event_timestamp in each row group might span 2026-01-01 to 2026-12-31.
For the same query filtering WHERE event_timestamp BETWEEN '2026-03-01' AND '2026-03-31':
- Every row group has a min-max range that overlaps with March.
- No row groups can be skipped.
- The engine must scan the entire table.
This is the worst case: statistics exist but provide zero skipping benefit because the data ordering produces maximally wide, overlapping min-max ranges.
The Practical Optimization: Physical Ordering and Partitioning
The prescriptive advice for maximizing Min-Max Statistics effectiveness is straightforward:
Partition by the primary temporal or categorical filter column: Partitioning by date means all data for date=2026-03-15 is physically segregated into a partition-specific directory. The query engine skips entire partition directories for non-March queries, without even consulting the Parquet-level min-max statistics.
Sort within partitions by the secondary filter column: Within each date partition, sorting by user_segment or region creates tight min-max ranges within row groups for those columns, enabling within-partition row group skipping.
Apply Z-Ordering or Hilbert Clustering for multi-column predicates: As discussed in the Z-Ordering and Hilbert Curves articles, multi-dimensional clustering tightens the min-max ranges for multiple columns simultaneously, enabling skipping for compound multi-predicate queries.
Statistics Accuracy and Truncation
Parquet’s min-max statistics have a subtle limitation for string and binary data types: very long string values can cause the statistics to be truncated. If min_value or max_value for a string column exceeds the Parquet writer’s maximum statistics length (configurable, typically 128 bytes), the writer may truncate the stored statistics to the first 128 characters and adjust the truncation direction (truncate min values toward a shorter value that is still ≤ the actual minimum; truncate max values toward a longer value that is still ≥ the actual maximum).
This truncation is safe — the statistics are still valid bounds — but it widens the effective range, reducing the ability to skip based on those statistics. For columns with very long string values (e.g., full URL paths, long text fields), min-max statistics may provide less precise skipping than for columns with compact values.
Similarly, for floating-point columns, NaN (not-a-number) values do not participate in min-max comparisons, and their presence in the data must be tracked separately through nan_value_counts to avoid incorrect range analysis.
Statistics Collection Performance Impact
Writing Min-Max Statistics at write time requires the Parquet writer to track the minimum and maximum value seen for each column during the row group write. For numeric and date types, this is simple in-memory comparison: maintain a running min and running max, update both for each value encountered. For string types, it requires comparing byte sequences — slightly more expensive but still very fast.
The performance impact of statistics collection on write throughput is typically less than 1% — the statistics tracking overhead is completely dominated by the cost of encoding, compressing, and writing the actual column data. Disabling statistics collection for write performance is almost never justified and should be avoided, as the resulting files will be invisible to the query engine’s skipping optimization.
Conclusion
Min-Max Statistics are the foundational, universal data skipping mechanism of the modern data lakehouse. Their effectiveness depends critically on data ordering — when data is sorted or partitioned by the predicate columns, they deliver dramatic IO reductions; when data is unordered, they provide minimal benefit. Their storage overhead is negligible relative to the data they describe. Their interaction with Iceberg’s three-tier metadata hierarchy (Manifest List → Manifest File → Parquet Row Group) allows query engines to skip irrelevant data at multiple granularity levels, from skipping entire manifest groups down to skipping individual row groups within a file. For range predicates on ordered data, they are unmatched in their combination of effectiveness and simplicity. For equality predicates on high-cardinality unordered data, they must be supplemented by Bloom Filters. For multi-column compound predicates, their effectiveness is maximized by Z-Ordering or Hilbert Clustering. Understanding this interplay — which statistics mechanism to apply, at which granularity, for which predicate types — is the essence of lakehouse query performance engineering.
Visual Architecture