MPP (Massively Parallel Processing)
Massively Parallel Processing (MPP) is an architectural design paradigm for distributed computing and databases. In an MPP system, a massive computational task (such as executing a complex SQL aggregation over billions of rows) is divided into smaller, independent chunks of work. These chunks are then distributed across a vast network of independent processing nodes, which execute the work simultaneously. MPP is the foundational architecture powering almost all modern enterprise data warehouses and high-performance query engines in the open data lakehouse ecosystem.
Core Definition
The core philosophy of MPP is “divide and conquer.” As data volumes exploded in the early 2000s, traditional Symmetric Multiprocessing (SMP) systems—where multiple processors share a single memory space and operating system—reached their physical and financial limits. SMP systems simply could not scale up efficiently to handle petabytes of data.
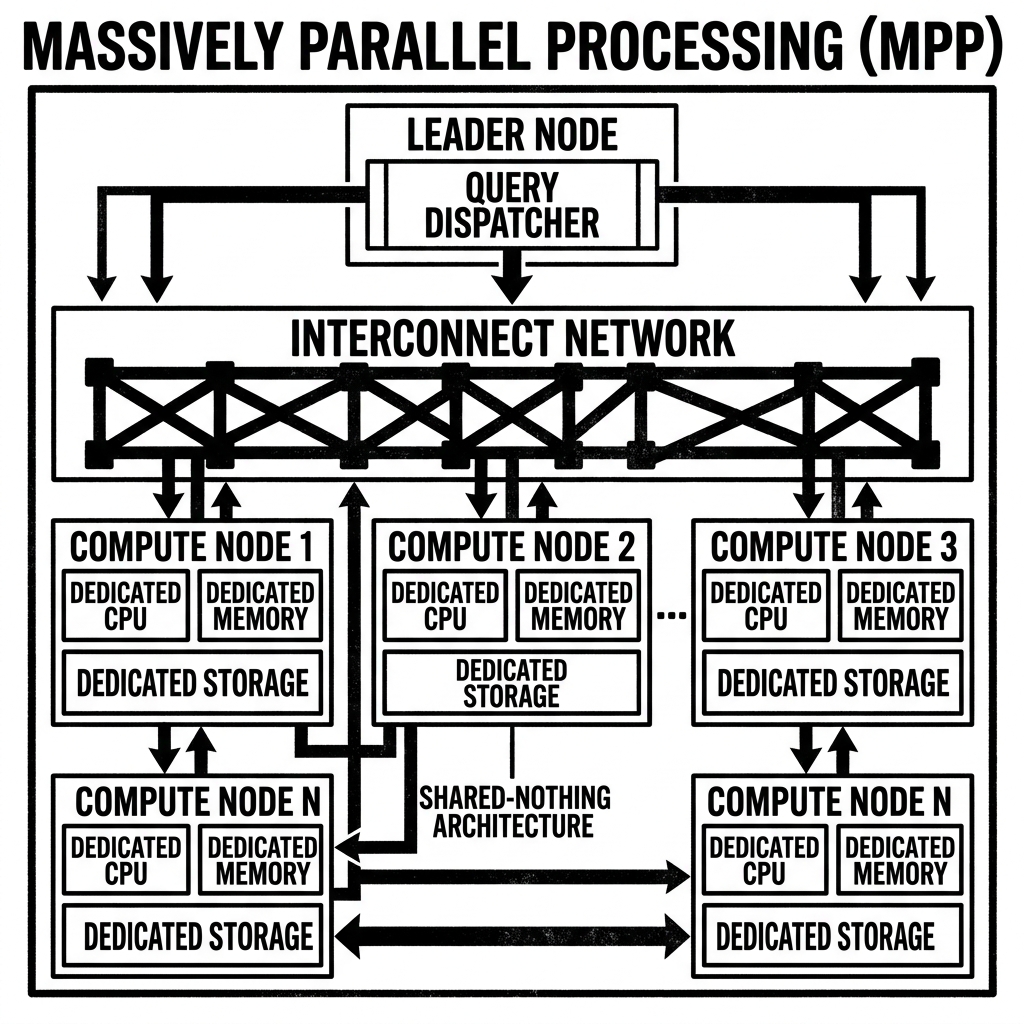
MPP emerged as the solution by employing a “Shared-Nothing” architecture. In a pure MPP database, the cluster consists of a coordinator node and hundreds or thousands of worker nodes. Each worker node is a self-contained unit with its own dedicated CPU, its own private memory (RAM), and its own local disk storage.
Crucially, the worker nodes do not share memory or disks. This shared-nothing design eliminates the severe contention and locking bottlenecks that plagued SMP systems. When a query is executed, the coordinator assigns a specific subset of the data to each worker node. The worker processes its local data independently of the others. Because the nodes operate autonomously, an MPP system can scale out linearly: to process twice as much data in the same amount of time, simply add twice as many worker nodes.
How MPP Executes Queries
The life cycle of a query in an MPP system highlights its parallel nature.
When an analyst submits a query like SELECT region, SUM(revenue) FROM global_sales GROUP BY region, the query hits the Coordinator Node (also known as the Leader or Frontend node).
- Parsing and Planning: The Coordinator parses the SQL and generates a distributed execution plan. It knows exactly how the
global_salestable is partitioned across the various worker nodes. - Distribution: The Coordinator dispatches the query instructions to all the Worker Nodes that hold a piece of the
global_salestable. - Local Execution: Every Worker Node begins reading its local slice of the data simultaneously. Each node performs a local
GROUP BYoperation, calculating the total revenue for each region based purely on the data it possesses. - Shuffling (Data Exchange): Because the query requires a global sum, the local results are not enough. The nodes must exchange data. They shuffle the intermediate results across the network so that all partial sums for “North America” end up on one specific node, and all partial sums for “Europe” end up on another.
- Final Aggregation: The designated nodes perform the final addition.
- Return: The final results are sent back to the Coordinator, which presents them to the user.
This highly orchestrated parallelism allows MPP databases like Teradata, Amazon Redshift, and Apache Doris to return results on massive datasets in seconds.
MPP in the Modern Data Lakehouse
Historically, MPP systems tightly coupled compute and storage. The data physically lived on the spinning disks inside the worker nodes. This made scaling complex; if you needed more storage, you had to buy more expensive compute nodes, and adding a node required rebalancing massive amounts of data across the network.
The modern data lakehouse relies on decoupled MPP architectures. Systems like Trino, StarRocks, and Snowflake utilize the MPP execution model (coordinators and massively parallel workers performing localized, in-memory computations and shuffles), but they do not store the permanent data on the workers’ local disks.
Instead, the persistent data lives in a shared Object Storage layer (like Amazon S3) in open formats like Apache Iceberg. The MPP worker nodes act as stateless compute engines. When a query arrives, the workers fetch the specific Parquet files they need from S3 over the network, perform the MPP execution in memory, and return the result.
To mitigate the latency of reading from network storage, modern MPP engines aggressively utilize local NVMe SSDs on the worker nodes as a temporary data cache. This hybrid approach combines the infinite, cheap storage scaling of the data lake with the blistering execution speed of traditional shared-nothing MPP databases.
Summary and Tradeoffs
Massively Parallel Processing revolutionized analytics by proving that a network of coordinated, shared-nothing nodes could tackle workloads impossible for a single supercomputer. It remains the dominant execution paradigm for fast SQL analytics.
The primary tradeoff with MPP systems, particularly those that maintain state (tightly coupled compute and storage), is operational complexity and rigidity. Handling node failures in a pure shared-nothing system can be difficult, as the loss of a node means the temporary loss of the specific data slice residing on its disk. Rebalancing data when scaling the cluster up or down is often a slow, network-intensive operation.
By decoupling storage to the data lakehouse, modern architectures have mitigated many of these drawbacks. They retain the parallel execution brilliance of MPP while offloading the storage management to infinitely scalable, highly durable object stores, creating the flexible, high-performance data platforms we use today.
Visual Architecture