Object Storage
Object Storage is a data storage architecture designed to manage massive amounts of unstructured and structured data. Unlike traditional file systems that manage data as a hierarchy of folders and files, or block storage that manages data as fixed-sized blocks on a hard drive, object storage manages data as discrete, self-contained units called “objects.” Pioneered commercially by Amazon S3, object storage provides infinite scalability, extreme durability, and cost-effectiveness, making it the bedrock foundation upon which all modern open data lakehouses are built.
Core Definition
To understand object storage, one must understand its predecessors: Block Storage and File Storage.
Block storage (like a traditional hard drive or an AWS EBS volume) breaks data into raw, fixed-size chunks. It is incredibly fast and highly mutable, making it perfect for the underlying storage of operational relational databases (OLTP) or operating systems. However, it is tied to a specific compute instance and is very expensive to scale.
File storage (like a Network Attached Storage or NFS) organizes data into a hierarchical tree of directories, folders, and files. While easier for humans to navigate, file systems struggle at massive scale. When a file system accumulates millions of files, the central directory index becomes a massive bottleneck. Simply listing the contents of a directory containing a million files can take several minutes.
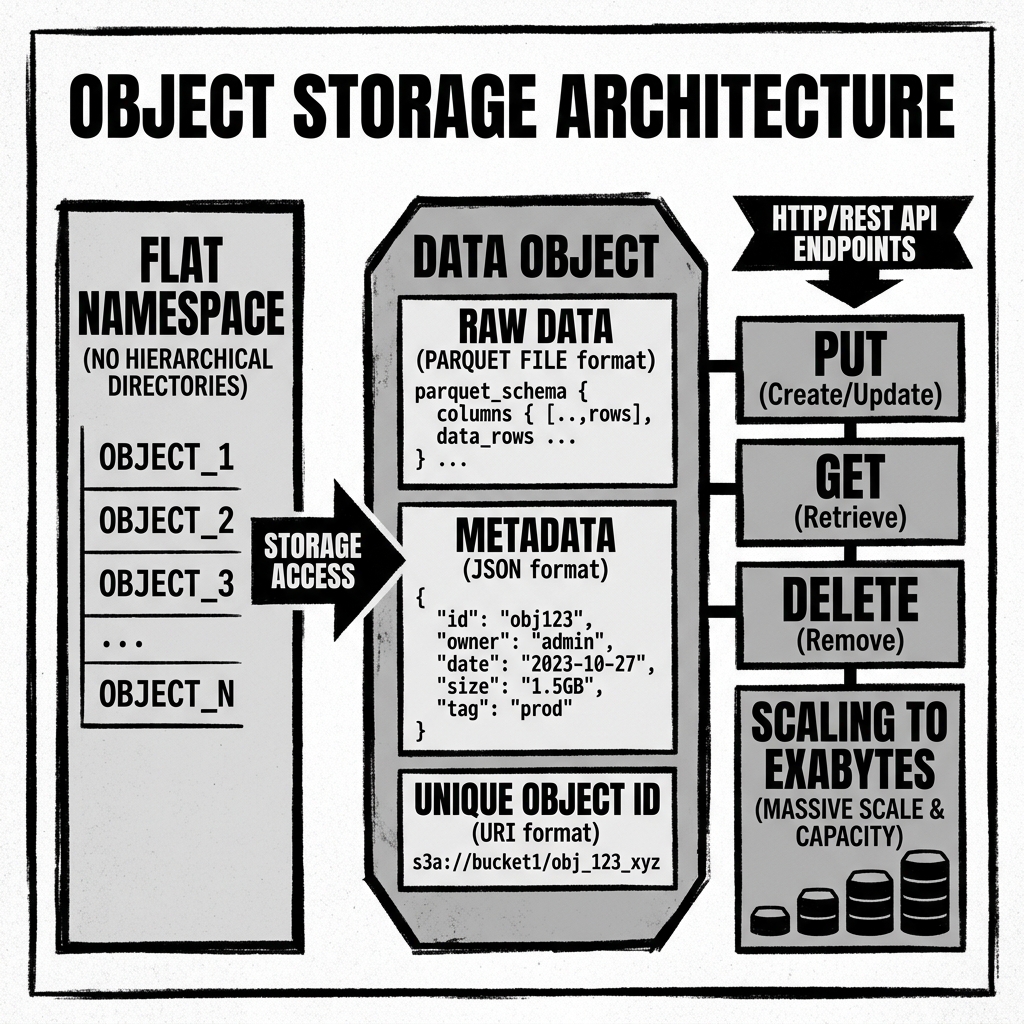
Object storage abandons the hierarchy entirely. It utilizes a flat, infinitely wide namespace. Every piece of data is encapsulated as an “object.”
An object consists of three distinct components:
- The Data: The actual bytes of the file (e.g., a massive Parquet file containing log data, or a high-resolution video).
- The Metadata: A robust set of customizable key-value pairs associated with the data (e.g.,
creator: alex,content_type: application/parquet,retention_policy: 3_years). - The Unique Identifier: A globally unique URI (Uniform Resource Identifier).
Because there is no hierarchical directory tree to navigate, retrieving an object is instantaneous, regardless of whether the system holds ten objects or ten trillion objects. The application simply provides the exact URI to the object storage API, and the system retrieves the data directly.
The Foundation of the Data Lakehouse
The open data lakehouse paradigm simply would not exist without object storage. The architecture of a lakehouse relies on the physical separation of compute and storage.
Object storage platforms like Amazon S3, Google Cloud Storage (GCS), and Azure Blob Storage provide the ultimate storage layer. They are inherently decoupled from any specific compute engine. A data engineering team can write petabytes of Parquet files to an S3 bucket using Apache Spark. An entirely different team of analysts can then query those exact same files using Trino or Amazon Athena. The object storage acts as the single, vendor-neutral source of truth.
Furthermore, object storage is built for extreme durability. When an object is written to AWS S3, the system automatically replicates that object across multiple physical facilities (Availability Zones). AWS advertises 99.999999999% (11 nines) of durability, meaning data loss is practically mathematically impossible. This eliminates the need for data engineering teams to manage complex, costly backup and replication infrastructure.
Interaction via APIs
Object storage is interacted with purely over the network, primarily using HTTP-based REST APIs. The most fundamental operations are PUT (to write an object), GET (to retrieve an object), and DELETE (to remove an object).
This API-driven design presents unique challenges and capabilities for analytical workloads. Unlike a local file system where an application can open a file and modify a single byte in the middle of it, object storage is generally immutable. You cannot UPDATE an object. If you need to change a single row in a 1GB Parquet file stored on S3, you must download the entire object, make the change in memory, and PUT a completely new version of the object back to the storage, overwriting the old one.
This immutability is why open table formats like Apache Iceberg are strictly necessary. Because the underlying objects cannot be modified, Iceberg manages updates by writing completely new data objects and writing new metadata objects that point to the new files, ignoring the old ones (which are later swept away during compaction processes).
However, object storage APIs offer a powerful capability critical for database engines: HTTP Range Requests. If an engine like DuckDB only needs to read the footer of a 1GB Parquet object to access its metadata, it does not need to download the entire gigabyte. It issues a GET request specifying a byte range (e.g., the last 64KB). The object storage returns only those specific bytes over the network, saving massive amounts of bandwidth and time.
Summary and Tradeoffs
Object storage is the unsung hero of modern big data. By abandoning hierarchical file systems in favor of a flat, API-driven namespace with rich metadata, it solved the scaling problems that plagued early data architectures. Its low cost, infinite capacity, and high durability make it the undisputed home for enterprise data lakes.
The primary tradeoff with object storage is latency. Because every interaction happens over HTTP network protocols, fetching an object from S3 will always have higher latency (often tens of milliseconds) compared to reading from a local NVMe SSD (microseconds).
Furthermore, object storage lacks native transactionality. You cannot inherently guarantee atomic commits across multiple objects. This is precisely why the industry developed layers like Apache Iceberg, Delta Lake, and Apache Hudi. These open table formats are software layers built specifically to sit on top of object storage, masking its high latency through aggressive caching and providing the ACID transactions that object storage natively lacks.
Visual Architecture