Optimistic Concurrency Control (OCC)
When multiple systems attempt to write data to the same table at the exact same time, a database must have a mechanism to resolve the conflict. If it doesn’t, data corruption is inevitable. Historically, databases solved this using Pessimistic Concurrency Control.
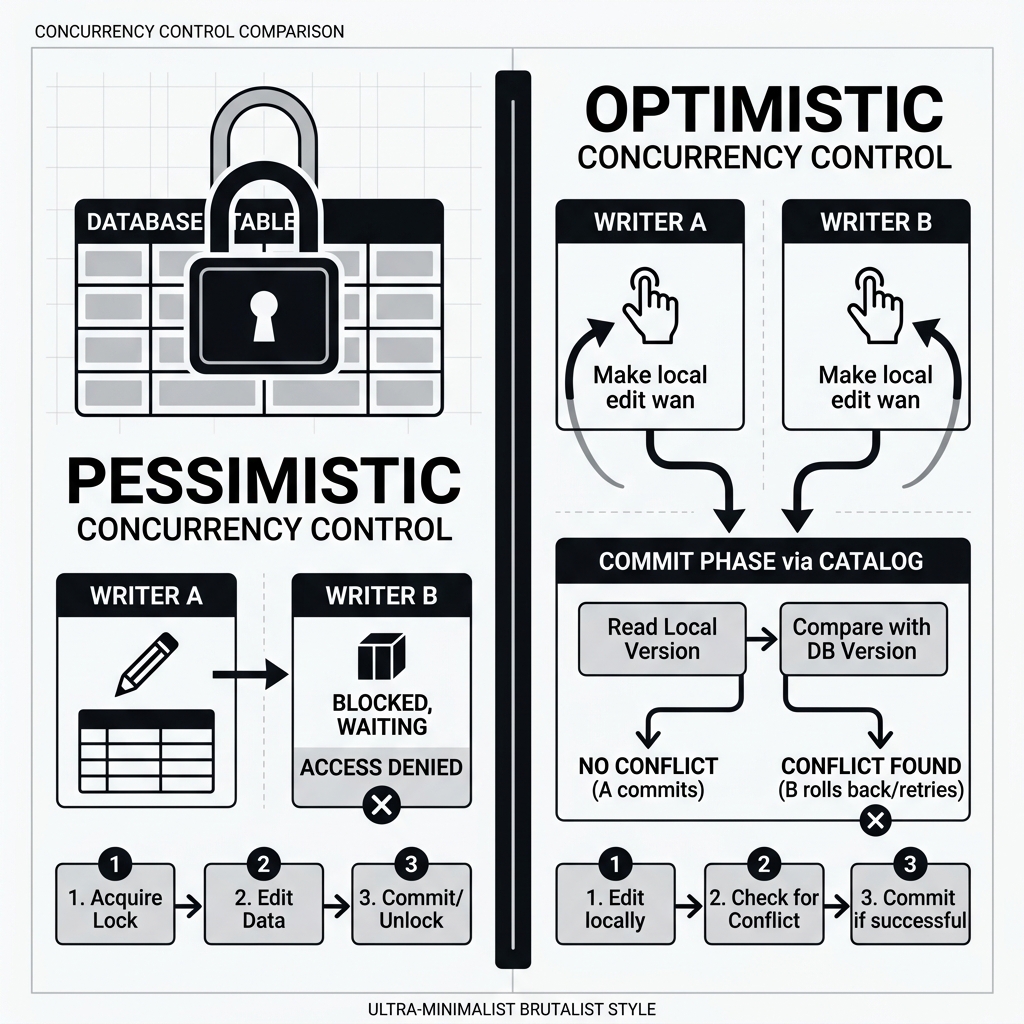
Pessimistic systems assume that conflicts will happen frequently. To prevent them, the database uses locks. If Writer A wants to update a table, the database places a lock on the table (or the specific rows). If Writer B arrives a millisecond later, Writer B is blocked. It must sit idle, wasting expensive compute resources, until Writer A finishes and releases the lock.
In a massive, distributed data lakehouse environment where ETL jobs can take hours, pessimistic locking is a catastrophic bottleneck. The solution is Optimistic Concurrency Control (OCC).
How OCC Works
Optimistic Concurrency Control assumes that conflicts are rare. Therefore, it does not use upfront locks. Writers are free to read the current state of the table and begin processing their heavy data transformations simultaneously.
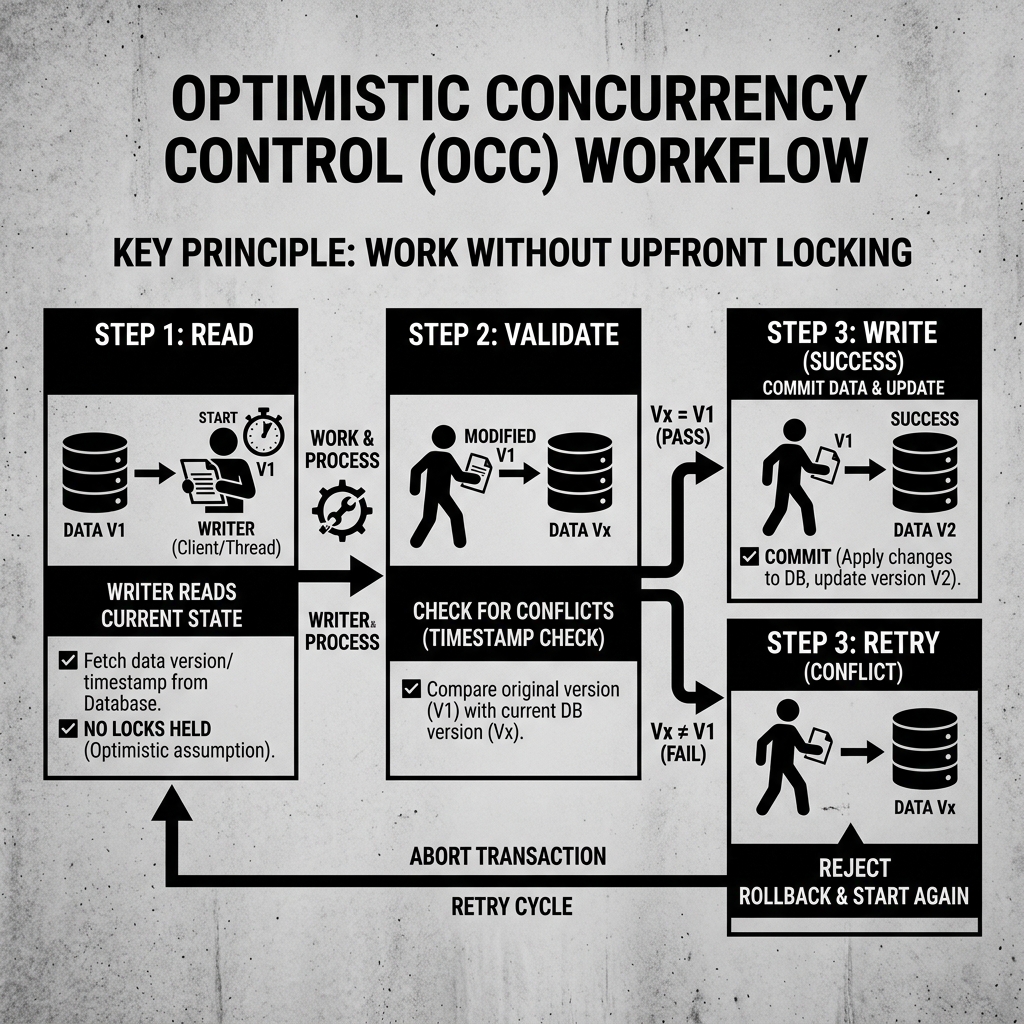
The OCC workflow consists of three distinct phases:
- Read Phase: The writer reads the current state (e.g., Snapshot V1) and performs its data transformations locally without acquiring any locks on the table.
- Validate Phase: When the writer is ready to commit, it checks the catalog. It asks, “Is the current state still V1?”
- Commit/Retry Phase: If the state is still V1, the validation passes, and the writer atomically commits its changes (creating V2). If the state is now V2 (meaning another writer committed while the first was working), the validation fails. The writer aborts the transaction, catches the exception, and starts over from the new V2 state.
Diagram 1: The OCC Workflow
The Benefit of Being Optimistic
Because OCC eliminates the need for distributed locking, it allows a data lakehouse to scale massive concurrent write operations seamlessly.
If ten different Spark clusters are appending data to ten different partitions of the same Iceberg table, they can all process their data simultaneously. The only point of contention is the microsecond it takes to perform the atomic Compare-and-Swap (CAS) on the catalog’s metadata pointer during the Commit phase.
Even when conflicts do occur (e.g., Writer B fails validation because Writer A committed first), Iceberg is intelligent enough to optimize the retry. Writer B does not necessarily have to re-process all its data. It simply downloads the new V2 metadata, verifies that Writer A’s changes do not logically conflict with its own (e.g., they wrote to different partitions), rebuilds its metadata tree on top of V2, and retries the commit.
Diagram 2: Pessimistic vs Optimistic Control
The Core of Open Standard Lakehouses
OCC is the engine that makes true decoupled compute and storage possible. By relying on atomic catalog operations rather than rigid file-system locks or dedicated database servers, open table formats like Apache Iceberg, Delta Lake, and Apache Hudi can support a thriving ecosystem where Spark, Flink, Trino, and Dremio can all read and write to the same data at the same time, safely and reliably.