Open Table Formats
The evolution of modern data architecture is marked by profound paradigm shifts. The transition from monolithic, on-premises relational databases to distributed, cloud-native storage fundamentally altered how enterprises store, process, and extract value from their data. However, this transition was fraught with technical compromises. The creation of the Data Lakehouse—an architecture that promises the scalability of a data lake with the reliability of a data warehouse—was impossible without a critical missing layer. That missing layer is the Open Table Format.
To understand the sheer technical magnitude of Open Table Formats like Apache Iceberg, Delta Lake, and Apache Hudi, it is necessary to examine the architectural crisis that precipitated their creation, the structural limitations of legacy metadata systems, and the granular, transaction-level mechanisms that enable these formats to bring absolute consistency to distributed object storage. This guide provides an exhaustive, highly technical exploration of Open Table Formats, dissecting their origins, their core capabilities, and the architectural nuances that distinguish the major players in the ecosystem.
The Genesis of the Crisis: The Hive Metastore Era
For nearly a decade, the Apache Hive ecosystem defined the standard for big data analytics. Hive was revolutionary because it imposed a SQL-like structure over raw files stored in the Hadoop Distributed File System (HDFS). It allowed analysts to write SQL queries against petabytes of unstructured data. However, the architectural foundation of Hive was fundamentally flawed when applied to modern, cloud-scale object storage (like Amazon S3, Google Cloud Storage, or Azure Blob Storage).
The Directory-Based Abstraction
The core failing of the Hive Metastore (HMS) was its reliance on the file system directory structure to define the boundaries of a table. In Hive, a table was simply a directory, and a partition was a sub-directory.
For example, a table partitioned by year and month would manifest on disk as:
s3://data-lake/sales_table/year=2026/month=05/
When a query engine like Apache Spark or Presto wanted to read data from this partition, it had to ask the object storage to perform a “list” operation on that specific directory. The engine would request a list of all files within year=2026/month=05/, wait for the file system to return the file names, and then begin reading the underlying Parquet or ORC files.
The Scale Ceiling and the O(N) Listing Problem
This directory-listing approach worked acceptably on HDFS, which was designed as a true file system. However, Amazon S3 and other cloud storage providers are object stores, not file systems. They emulate directory structures using key prefixes. Listing thousands of objects sharing a prefix is a highly latency-bound operation.
As enterprises scaled their data lakes to petabyte ranges, tables grew to contain millions of files. When a query engine attempted to plan a query, the O(N) file listing operation became the primary bottleneck. A query that should have taken three seconds to execute would spend five minutes just listing directories to figure out which files to read. This was the famous “Hive problem.”
The Absence of ACID Transactions
Beyond performance, the directory-based abstraction completely lacked atomicity, consistency, isolation, and durability (ACID). Because a table was just a directory, writing data meant dumping files into that directory.
If a Spark job failed halfway through writing 1,000 files to a partition, 500 files would be left behind. There was no concept of a rollback. Any analyst querying the table at that exact moment would read partial, corrupted data. To safely update or delete a single row in a Hive table, the entire partition had to be locked, completely rewritten to a temporary directory, and then swapped using an ALTER TABLE command—a process that was computationally devastating and highly error-prone.
The data lake was a chaotic, unreliable swamp. The industry needed a layer that could provide the transactionality of a PostgreSQL database over the infinite scale of cloud object storage.
The Paradigm Shift: What is an Open Table Format?
An Open Table Format is a specification—a set of rules and protocols—that defines how a massive collection of raw data files (usually Parquet, ORC, or Avro) should be organized, tracked, and managed to present the illusion of a single, highly structured, ACID-compliant database table.
Crucially, Open Table Formats sever the relationship between the logical table and the physical file directory.
Metadata over Directories
In an Open Table Format architecture, the file system is treated as a dumb, flat storage layer. The engine no longer cares about folders or directory structures. Instead, the format introduces an incredibly robust, highly structured metadata layer that sits perfectly between the compute engine and the raw data files.
This metadata layer maintains an exhaustive, explicit list of every single physical file that belongs to the table at any given microsecond. When a query engine wants to read the table, it does not ask the object store to list files. Instead, it reads the metadata. The metadata acts as a centralized brain, instantly telling the query engine exactly which files to read, exactly where they are located, and exactly what data they contain, down to the min/max statistics of individual columns.
The “Open” Designation
The “Open” in Open Table Formats is critical. These formats are not proprietary engines; they are open-source specifications governed by organizations like the Apache Software Foundation or the Linux Foundation. They define standard APIs and file layouts.
This means that data written by Apache Spark into an Iceberg format can be seamlessly read by Trino, Dremio, Snowflake, or DuckDB without moving, copying, or translating a single byte of data. The storage layer becomes entirely decoupled from the compute engine, preventing vendor lock-in and allowing organizations to route different analytical workloads to the most cost-effective compute engine.
Core Capabilities of Open Table Formats
By abstracting the table definition into a strict metadata layer, Open Table Formats unlock a suite of enterprise-grade capabilities that were previously exclusive to monolithic data warehouses.
1. ACID Transactions and Snapshot Isolation
The most fundamental capability is the enforcement of ACID transactions. Open Table Formats achieve this through Optimistic Concurrency Control (OCC) and atomic pointer swaps.
Every time data is inserted, updated, or deleted, the format creates a completely new, immutable metadata state, referred to as a Snapshot. The underlying data files are immutable. When the write operation is finished, the catalog performs an atomic swap, moving the active pointer from Snapshot N to Snapshot N+1.
Because this swap is atomic, readers are perfectly isolated. An analyst querying the table will read the state of Snapshot N until the exact millisecond the swap occurs, at which point new queries will instantly read Snapshot N+1. There are no dirty reads, no partial data exposures, and no locking mechanisms that block analysts from querying the table while an ETL job is running.
2. Time Travel and Rollback
Because every transaction creates a new, immutable Snapshot, the table’s history is preserved. The metadata tracks a chronological log of these snapshots.
This enables Time Travel. Analysts can append AS OF SYSTEM_TIME to their SQL queries to read the table exactly as it existed last Tuesday at 4:00 PM. The query engine simply traverses the metadata log backward, finds the snapshot active at that timestamp, and reads the files mapped to that state.
This capability is revolutionary for auditing, compliance, machine learning reproducibility, and disaster recovery. If a pipeline accidentally deletes a million rows, an engineer can issue a Rollback command, atomically swapping the catalog pointer back to the previous snapshot, restoring the data in milliseconds without copying any files.
3. Safe Schema Evolution
In legacy Hive tables, columns were often tracked by their physical position. Dropping a column in the middle of a schema would cause all downstream data to shift, corrupting analytical queries.
Open Table Formats solve this by assigning immutable, unique IDs to every column. The metadata maps the logical column name to this internal ID. If a user renames a column from user_id to account_id, the underlying ID remains the same, and the query engine continues to read the correct physical data without rewriting any files. Columns can be added, dropped, renamed, or widened safely and instantaneously via pure metadata operations.
4. Partition Evolution and Hidden Partitioning
Partitioning is crucial for skipping data during query execution. However, business needs change. A table partitioned by year might grow so large that it needs to be partitioned by month or day.
Open Table Formats support Partition Evolution. The partition scheme is defined in the metadata, not the physical directory structure. An engineer can update the partition specification on the fly. Old data remains partitioned by year, while new data is partitioned by month. The query engine intelligently reads across both layouts and merges the results seamlessly.
Furthermore, formats like Apache Iceberg support Hidden Partitioning, where the system automatically derives the partition value from the raw data (e.g., extracting the month from a timestamp) without requiring the user to manually create and manage redundant partition columns.
5. Row-Level Mutations (Upserts and Deletes)
Before Open Table Formats, data lakes were append-only. Handling Change Data Capture (CDC) streams or compliance requests (like GDPR “Right to Be Forgotten”) was an engineering nightmare.
Open Table Formats support granular row-level mutations via two primary architectures:
- Copy-on-Write (CoW): To delete a row, the engine reads the entire Parquet file, filters out the deleted row, and writes a completely new file. This guarantees blistering read performance but suffers from massive write amplification.
- Merge-on-Read (MoR): To delete a row, the engine writes a tiny “Delete File” (a logical tombstone) noting which row was deleted. At read time, the query engine merges the data file and the delete file in memory. This allows for extremely fast, high-velocity streaming inserts, but requires periodic background compaction to maintain read performance.
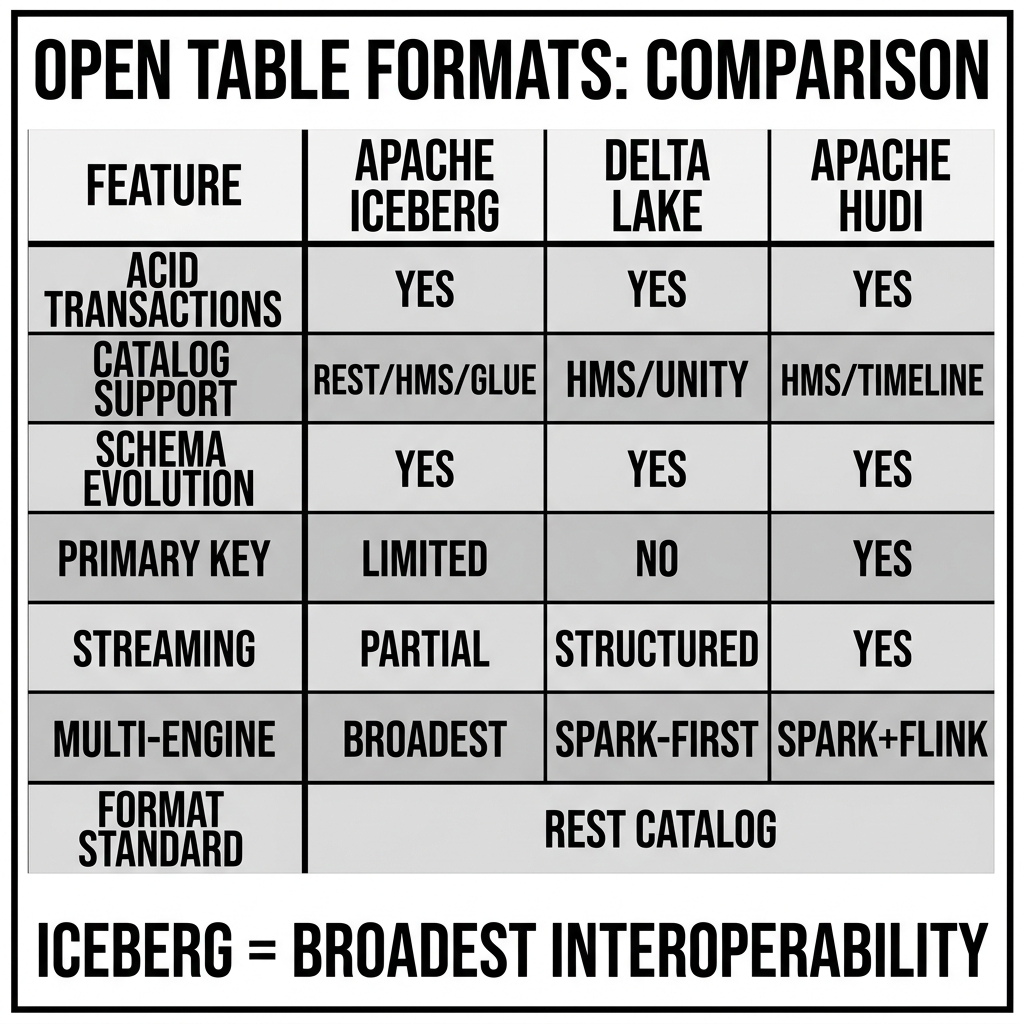
The Big Three: Iceberg, Delta, and Hudi
While they all solve the same fundamental problems, the three dominant Open Table Formats emerged from different engineering cultures and employ slightly different architectural philosophies.
Apache Hudi: The Streaming Heavyweight
Apache Hudi (Hadoop Upserts Deletes and Incrementals) was created by Uber in 2016. Uber’s core engineering challenge was dealing with massive, high-velocity streaming data and continuous row-level updates (e.g., tracking a driver’s GPS location every few seconds).
Consequently, Hudi was explicitly designed from day one to treat the data lake like a transactional database. It pioneered the Merge-on-Read architecture to absorb high-frequency upserts without buckling under write amplification.
Hudi’s architecture is characterized by its robust, built-in table services. Unlike Iceberg, which often relies on external engines to trigger maintenance, Hudi has deeply integrated mechanisms for asynchronous compaction, clustering, and index management. It provides powerful primitives for incremental processing, allowing downstream pipelines to easily pull only the records that have changed since the last checkpoint. If your architecture is heavily biased toward continuous streaming ingestion and near-real-time updates, Hudi offers the most mature tooling out of the box.
Delta Lake: The Log-Structured Lakehouse
Delta Lake was created by Databricks in 2017 and open-sourced in 2019. Databricks needed a way to bring reliability to the Apache Spark ecosystem, unifying batch and streaming workloads over cloud object storage.
Delta Lake’s architecture is conceptually simpler than Iceberg’s. It is built around a centralized Transaction Log (the _delta_log directory). Every transaction writes a JSON file to this directory detailing exactly which Parquet files were added and which were removed.
To plan a query, the engine reads the JSON logs in chronological order to reconstruct the active state of the table. To prevent the engine from having to read thousands of JSON files, Delta Lake periodically creates Parquet “checkpoints” that summarize the entire log up to that point.
Because Delta Lake was born at Databricks, it enjoys unparalleled, deep integration with Apache Spark. It is widely considered the easiest format to implement if your organization is already heavily invested in the Spark ecosystem. It enforces strict schema validation on write and provides out-of-the-box features like OPTIMIZE and Z-ORDER clustering for aggressive read optimization.
Apache Iceberg: The Metadata-Driven Standard
Apache Iceberg was created by Netflix in 2017 and donated to the Apache Software Foundation. Netflix was dealing with petabyte-scale tables that utterly broke the Hive Metastore’s directory listing capabilities. They didn’t just need row-level updates; they needed a fundamental architectural rebuild of how metadata scales.
Iceberg’s defining characteristic is its aggressive, hierarchical metadata tree. Instead of a linear transaction log, Iceberg uses a tree of files:
- Metadata JSON: The absolute root, tracking schema, partitioning, and the active Snapshot.
- Manifest List: A file that tracks multiple Manifest Files, storing min/max statistics for entire partitions.
- Manifest File: A file that tracks individual Parquet data files, storing granular column-level statistics.
This tree structure allows query engines to perform massive predicate pushdown at the metadata level. If an analyst queries a year of data, Iceberg can read the Manifest List, instantly eliminate 90% of the underlying Manifest Files based on their partition statistics, and completely skip reading the file paths of irrelevant data.
Iceberg is widely considered the most scalable and rigorously specified of the three formats. It was designed from the ground up to be completely engine-agnostic. While Delta is heavily tied to Spark, and Hudi is heavily tied to its own internal services, Iceberg acts as a neutral Switzerland. It is supported as a first-class citizen by Trino, Dremio, Snowflake, BigQuery, Athena, and Flink. Its strict specification ensures that every engine interprets the metadata identically, making it the de facto standard for organizations building multi-engine, polyglot lakehouse architectures.
The Storage and Compute Separation Paradigm
The widespread adoption of Open Table Formats marks the final realization of the separation of storage and compute.
In legacy architectures like Teradata or early Hadoop distributions, compute and storage were tightly coupled on the same physical hardware. To add more storage, you had to buy more compute processors.
Cloud object storage separated the hardware, but the metadata remained tightly coupled to specific processing engines. If you stored your data in a proprietary Snowflake format, only Snowflake compute clusters could read it. If you wanted to use a specialized machine learning framework, you had to export the data, duplicating storage costs and creating synchronization nightmares.
Open Table Formats sever this final tie. The data and the metadata live entirely in cheap, durable cloud object storage. The compute engine becomes a stateless, ephemeral commodity. An organization can spin up a massive Apache Spark cluster at 2:00 AM to perform heavy ETL, shut it down completely, and then spin up a Trino or Dremio cluster at 8:00 AM to serve sub-second interactive dashboards—both hitting the exact same Iceberg table without moving a single byte of data.
This paradigm forces compute engines to compete purely on price and performance, rather than holding the underlying data hostage.
The Future: Convergence and Interoperability
As the lakehouse ecosystem matures, the feature gaps between Iceberg, Delta, and Hudi are rapidly closing. All three now support advanced features like Deletion Vectors, Change Data Feed (CDF), and Z-Ordering.
The new frontier is interoperability. Large enterprises often find themselves with fragmented environments—one team adopted Delta Lake because they use Databricks, while another team adopted Apache Iceberg because they use Trino.
To prevent siloization, the industry is investing heavily in metadata translation layers. Projects like Apache XTable (formerly OneTable) and Delta UniForm (Universal Format) are designed to allow a table written in one format to be instantly readable as another.
These interoperability layers work by reading the metadata of the source format (e.g., Delta’s transaction log) and asynchronously generating the metadata tree for the target format (e.g., Iceberg’s manifests) pointing to the exact same physical Parquet files. This allows organizations to write data once and expose it universally to any engine, regardless of which format that engine prefers.
Conclusion
Open Table Formats are not merely a new file type; they are the operating system of the modern data lakehouse. By imposing strict, transactional metadata over distributed object storage, Apache Iceberg, Delta Lake, and Apache Hudi have solved the scale and reliability crises of the Hadoop era. They enable safe schema evolution, instant time travel, high-velocity row-level mutations, and absolute engine independence. As interoperability standards continue to evolve, Open Table Formats will remain the definitive architectural foundation for any organization building a scalable, future-proof data ecosystem.
Visual Architecture