ORC Format
Apache ORC (Optimized Row Columnar) is the second major columnar file format found in modern data lakehouses. It was created by Hortonworks in 2013, roughly around the same time Twitter and Cloudera were creating Apache Parquet.
While Parquet was designed as a general-purpose format heavily optimized for complex nested data structures and Apache Spark, ORC was designed with a very specific, ruthless focus: making Apache Hive queries run as fast as possible on flat, highly structured relational data.
Like Parquet, ORC is a columnar format. It stores data column by column, enabling massive compression ratios and predicate pushdown (allowing query engines to skip irrelevant data at the storage layer).
Internal Architecture of an ORC File
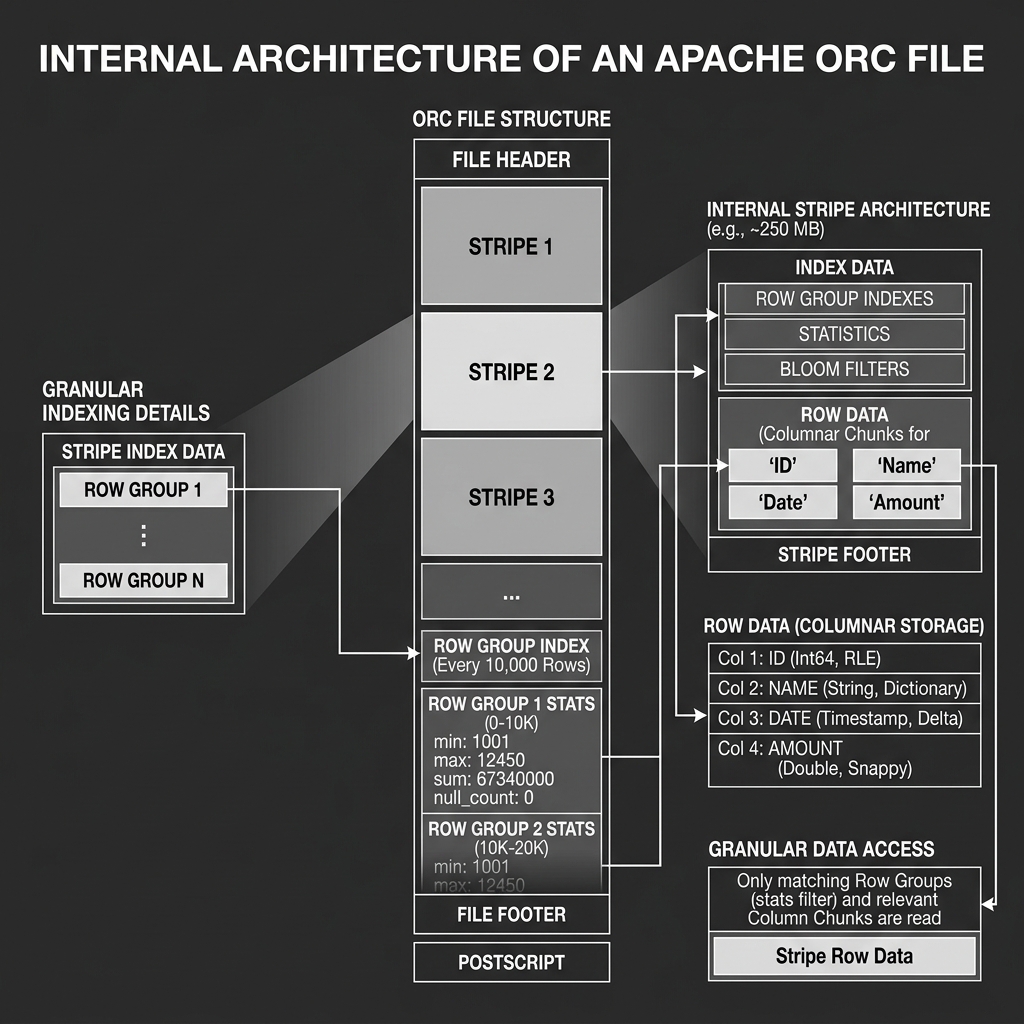
The internal architecture of an ORC file is conceptually similar to Parquet, but uses different terminology and internal structures.
Instead of Parquet’s “Row Groups,” an ORC file is divided into Stripes. A Stripe is a large chunk of columnar data, typically 250MB in size.
Inside an ORC file, you will find:
- File Header: Contains the magic word
ORC. - Stripes: The core data. Each Stripe contains:
- Index Data: Extremely granular statistics (min, max, sum) for every 10,000 rows within the Stripe.
- Row Data: The actual compressed columnar data chunks.
- Stripe Footer: Metadata about the specific layout of the chunks in this Stripe.
- File Footer: Contains the schema, a list of all the Stripes in the file, and file-level statistics.
- Postscript: A tiny block at the very end of the file containing compression parameters and the length of the File Footer.
The defining feature of ORC is its Index Data. While Parquet maintains statistics at the Row Group/Page level, ORC maintains a strict, lightweight index for every 10,000 rows. If an engine is searching for ID = 500, it doesn’t just skip the whole Stripe; it can use the index to jump directly to the specific 10,000-row block containing the target, skipping the rest of the Stripe entirely.
Diagram 1: ORC File Architecture
ORC vs. Parquet
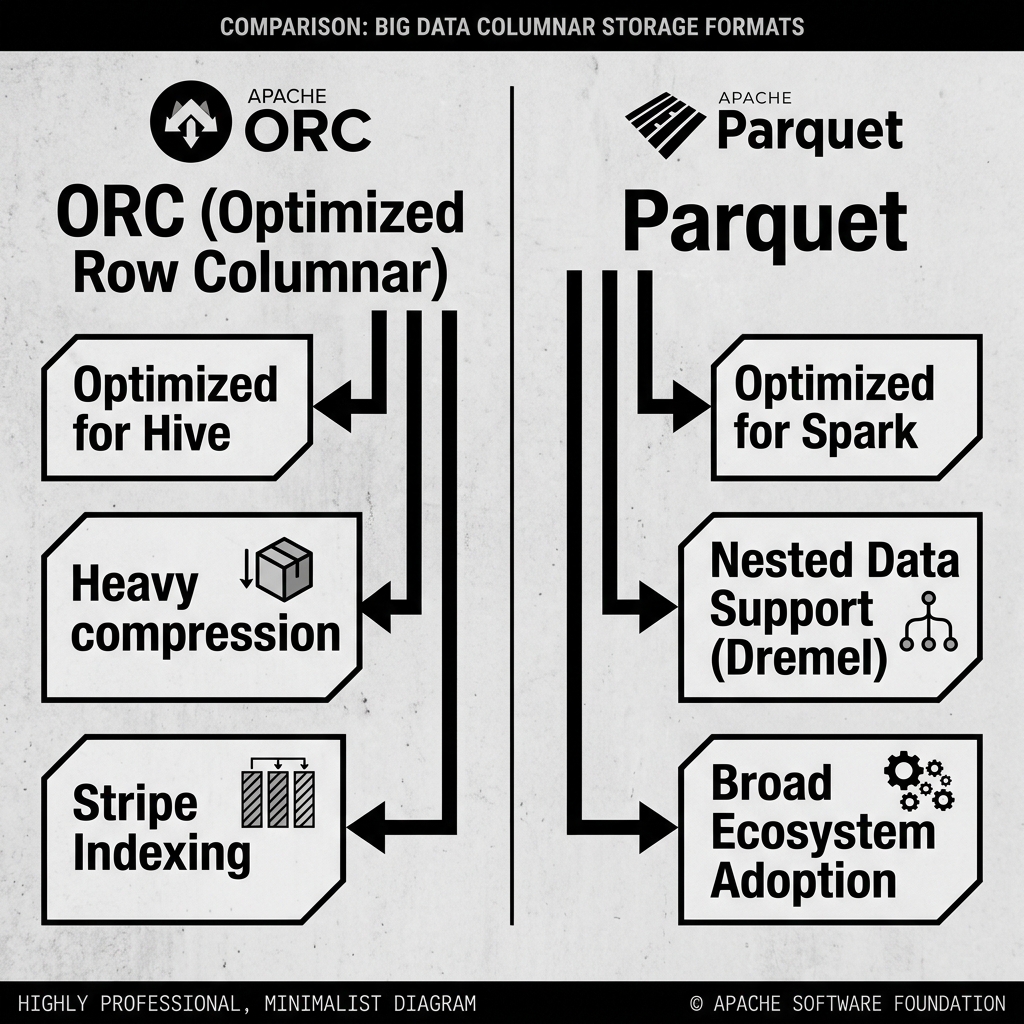
Both ORC and Parquet are fully supported by open table formats like Apache Iceberg. Deciding which one to use usually comes down to your existing ecosystem and data types.
Compression and Flat Data: If you are storing massive amounts of flat, tabular data (like traditional relational database exports) and storage cost is your primary concern, ORC historically edges out Parquet in raw compression ratios. It creates slightly smaller files.
Nested Data and Ecosystem: If your data contains complex nested arrays, structs, and maps (like raw JSON logs), Parquet is vastly superior due to its Dremel encoding model. Furthermore, Parquet has achieved broader industry adoption. If you are using Apache Spark, Pandas, or modern cloud data warehouses (like Snowflake or BigQuery), Parquet is the native, heavily optimized standard.
The Hive Legacy: ORC was built for Apache Hive. If your organization relies heavily on legacy Hive infrastructure, ORC is the natural choice.
Diagram 2: ORC vs Parquet
Summary
In the modern data lakehouse, Parquet is the default standard for physical data storage. However, ORC remains a powerful, fully supported alternative for organizations that prioritize extreme compression on flat schemas or are migrating from legacy Hadoop/Hive architectures.