Parquet Format
Apache Parquet is an open-source, columnar file format designed specifically for fast data processing and massive storage efficiency in the Hadoop and data lakehouse ecosystems. Created jointly by Twitter and Cloudera in 2013, Parquet has become the undisputed standard for analytical data storage.
If you are using a modern data lakehouse platform—whether it is built on Apache Iceberg, Delta Lake, or Apache Hudi—the vast majority of your raw data is likely stored as Parquet files.
Internal Architecture of a Parquet File
A Parquet file is not just a dumb dump of columnar data; it has a highly structured, self-describing internal architecture.
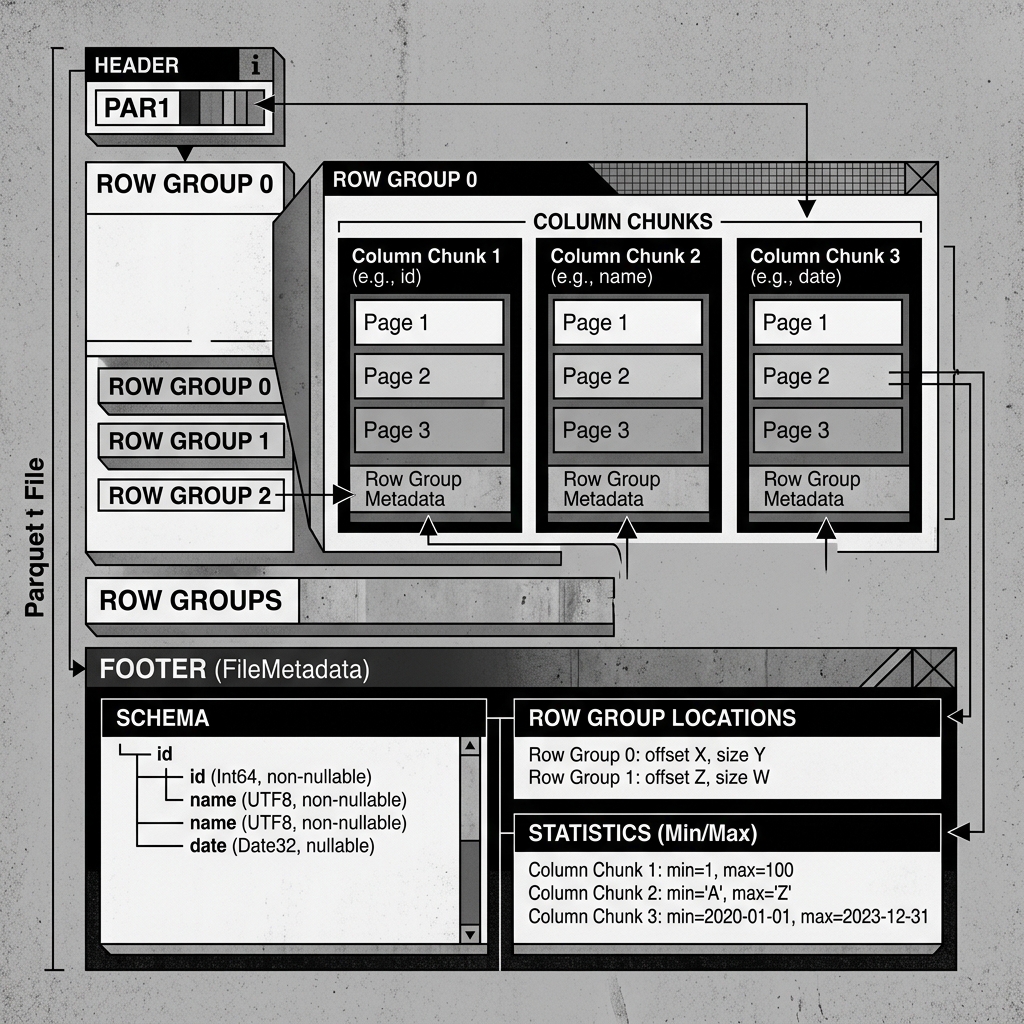
A Parquet file is logically divided into three main sections:
- Header: A tiny magic number (
PAR1) that tells the engine, “Yes, I am a Parquet file.” - Row Groups: The bulk of the file. A Parquet file is horizontally sliced into Row Groups (typically 128MB to 1GB in size). Inside a Row Group, the data is stored vertically in Column Chunks. Each Column Chunk contains all the values for one specific column for that Row Group. The Column Chunks are further divided into Pages, which are the smallest unit of compression and reading.
- Footer: This is the most important part of the file for performance. The Footer contains the File Metadata. It stores the full schema of the data, the exact byte offsets (locations) of every Row Group and Column Chunk, and, crucially, statistics (min/max values and null counts) for every Column Chunk.
Because the Footer contains the schema, Parquet files are self-describing. You do not need an external catalog to figure out what columns exist in a Parquet file; you just read the Footer.
Diagram 1: Parquet File Architecture
Predicate Pushdown
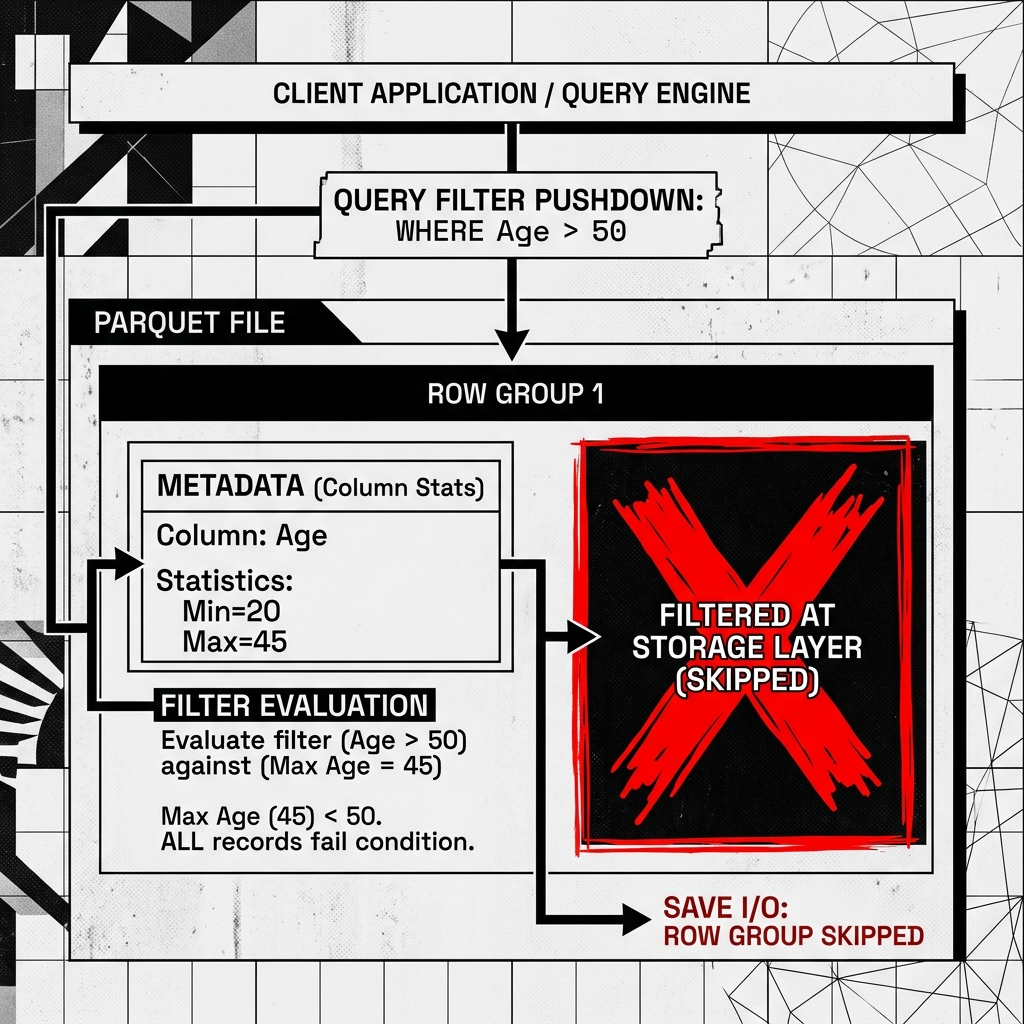
The rich statistics stored in the Parquet Footer enable one of the most powerful performance optimizations in data engineering: Predicate Pushdown (also known as Filter Pushdown).
In older Big Data systems, if you ran SELECT * FROM users WHERE age > 50, the query engine had to load the entire multi-gigabyte file from disk into RAM, and then filter out the rows where the age was 50 or below. This wasted massive amounts of network bandwidth, memory, and CPU.
With Parquet, the engine “pushes” the predicate (WHERE age > 50) down to the storage layer.
- The engine reads only the tiny Footer at the end of the Parquet file.
- It looks at the statistics for Row Group 1’s
agecolumn. The stats saymin: 18, max: 45. - The engine immediately knows that absolutely no data in Row Group 1 satisfies the
age > 50condition. - The engine completely bypasses Row Group 1, saving a massive amount of disk I/O.
Diagram 2: Predicate Pushdown
Why Parquet Won the Lakehouse
Parquet became the standard for the modern data lakehouse for three primary reasons:
1. Extreme Compression: Because Parquet stores identical data types contiguously (e.g., a million integers in a row), it can use advanced, type-specific encoding (like Dictionary Encoding or Run-Length Encoding) before applying standard compression (like Snappy or Zstd). This often results in files that are 75-90% smaller than their CSV equivalents.
2. Complex Nested Data: Unlike some older columnar formats, Parquet was designed from the ground up to support complex nested data structures (like arrays and maps) using the Dremel encoding model. This makes it perfect for storing highly structured JSON-like telemetry or application logs.
3. Open Ecosystem: Parquet is an Apache Software Foundation project. It is not owned by any single vendor. Every major query engine—Spark, Trino, Dremio, Flink, Snowflake, BigQuery—has heavily optimized Parquet readers, ensuring total interoperability across the data stack.