Partition Evolution
Partition Evolution
In the lifecycle of a data lakehouse, data volume rarely remains static. A startup might launch a new application and decide to partition their user event table by year. For the first two years, this works perfectly.
However, in year three, the application goes viral. The data volume explodes. A single year’s partition now contains 50 terabytes of Parquet files. When an analyst queries data for a specific day, the engine is forced to scan a massive, unmanageable directory. The engineering team realizes they must increase the partition granularity to month or day.
In legacy Hive architectures, changing a partition scheme was an engineering nightmare. It required creating a brand new table with the new partitioning scheme and running a massive, expensive Spark job to copy and rewrite every single byte of historical data into the new directory structure.
Apache Iceberg solves this completely with Partition Evolution.
Updating the Spec, Not the Data
Because Iceberg abstracts the physical layout of the files away from the logical table definition using the Partition Spec, evolving the partition scheme is a pure metadata operation.
An engineer simply runs an ALTER TABLE command (e.g., ALTER TABLE events REPLACE PARTITION FIELD year(ts) WITH month(ts)).
Iceberg creates a new metadata file containing Partition Spec v2.
From the exact millisecond that command executes, any new data written to the table will be partitioned by month. However, the historical data written in years one and two remains completely untouched, sitting exactly where it is, partitioned by year under Partition Spec v1.
There is zero data rewriting, zero downtime, and zero cost.
Diagram 1: Partition Evolution Over Time

Unified Query Execution
The brilliance of Partition Evolution is how Iceberg handles queries across these mixed-granularity boundaries.
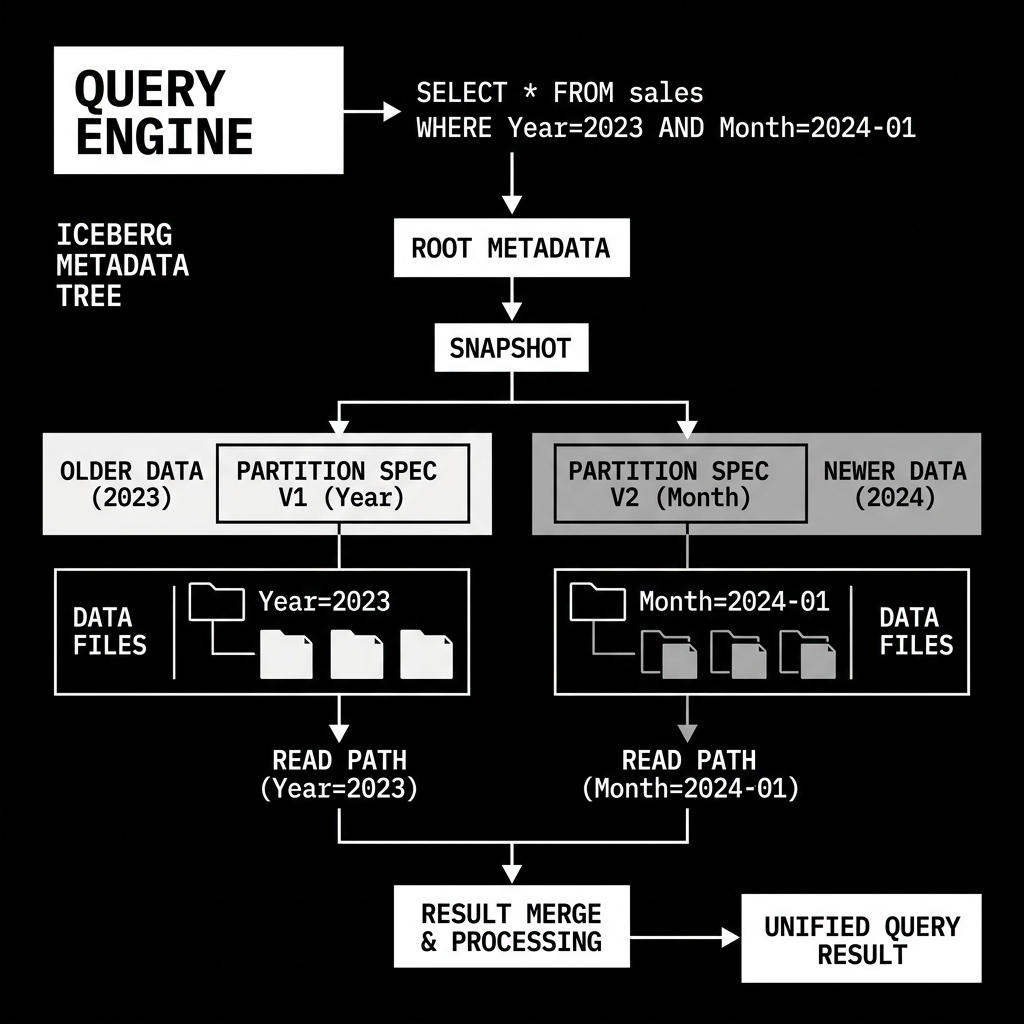
If an analyst runs a query spanning historical and new data (e.g., SELECT * FROM events WHERE ts >= '2023-01-01' AND ts < '2024-03-01'), they do not need to know that the partition scheme changed halfway through that time period.
The query engine reads the Iceberg metadata tree. The tree explicitly maps which Parquet files belong to Partition Spec v1 (Year) and which belong to Partition Spec v2 (Month).
The engine uses Spec v1 to quickly isolate the year=2023 folder, and it uses Spec v2 to isolate the month=2024-01 and month=2024-02 folders. It seamlessly reads across both physical layouts and merges the results, providing the analyst with a unified, perfectly accurate response.
Diagram 2: Querying Evolved Partitions