Partition Spec
Partitioning is a fundamental technique in data engineering. By dividing a massive table into smaller, logical directories (e.g., grouping data by year, month, or region), query engines can drastically reduce the amount of data they need to scan. If an analyst queries data for “December 2026”, the engine only reads the files in the month=2026-12 partition and completely ignores the rest of the petabyte-scale table.
In legacy systems like Apache Hive, partitioning was brittle and manual. It was strictly tied to the physical directory structure on disk. Apache Iceberg revolutionizes this by introducing the Partition Spec.
The Partition Spec is a piece of metadata stored in the table’s JSON metadata file. It tells the query engine exactly how the data is logically grouped, completely divorcing the logical partitioning rules from the physical directory structure.
Hidden Partitioning
In older systems, to partition by date, data engineers had to create a brand new column (e.g., a string column called date_string) alongside their existing timestamp column. When inserting data, they had to manually extract the date and insert it into this new column. If they forgot, the query engine wouldn’t know how to partition the data.
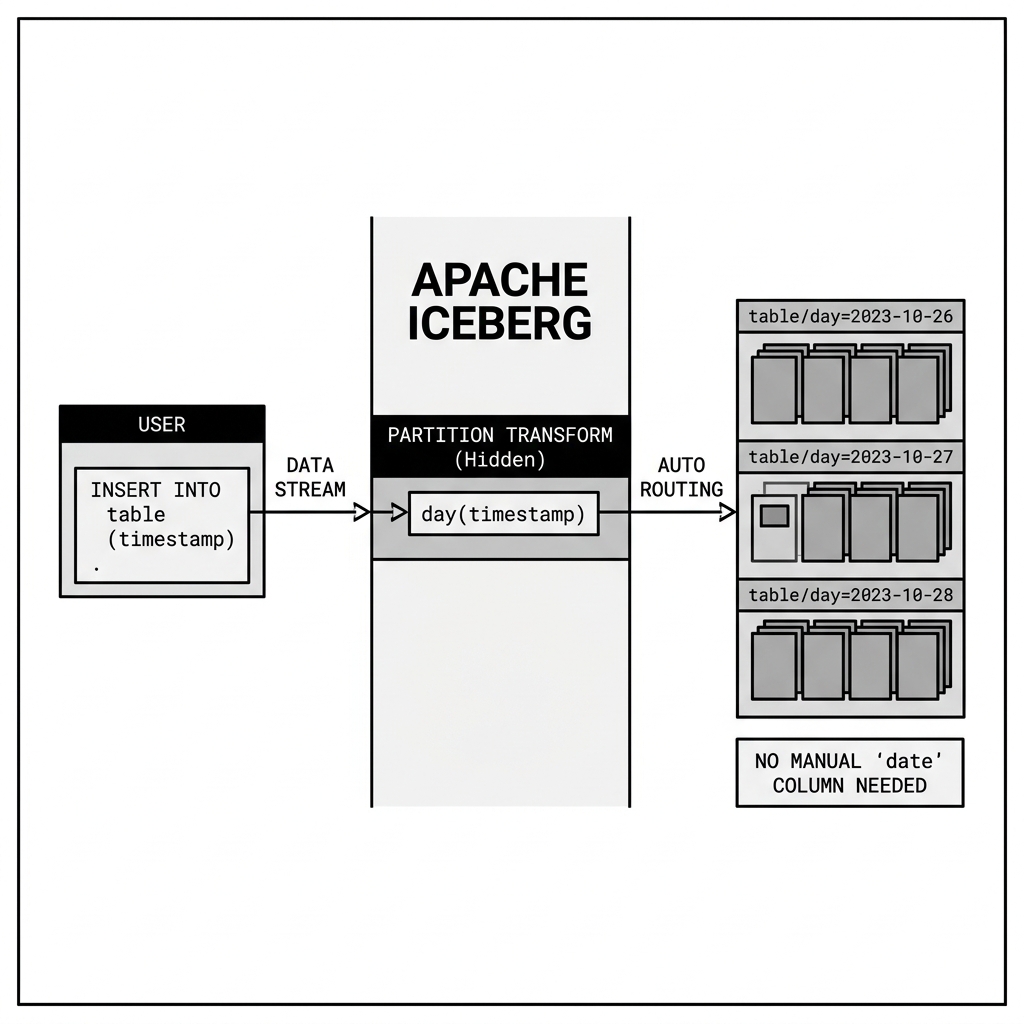
Iceberg solves this with Hidden Partitioning. The Partition Spec supports transform functions. You can configure the spec to automatically derive the partition value from an existing column.
For example, you can define a partition spec as day(event_timestamp). When a user runs an INSERT statement, they only provide the raw timestamp. Iceberg automatically applies the transform function, calculates the correct day, and routes the new Parquet files into the correct logical partition. The user doesn’t need to know the table is partitioned, and they don’t need to manually supply a redundant partition column.
Diagram 1: Hidden Partitioning
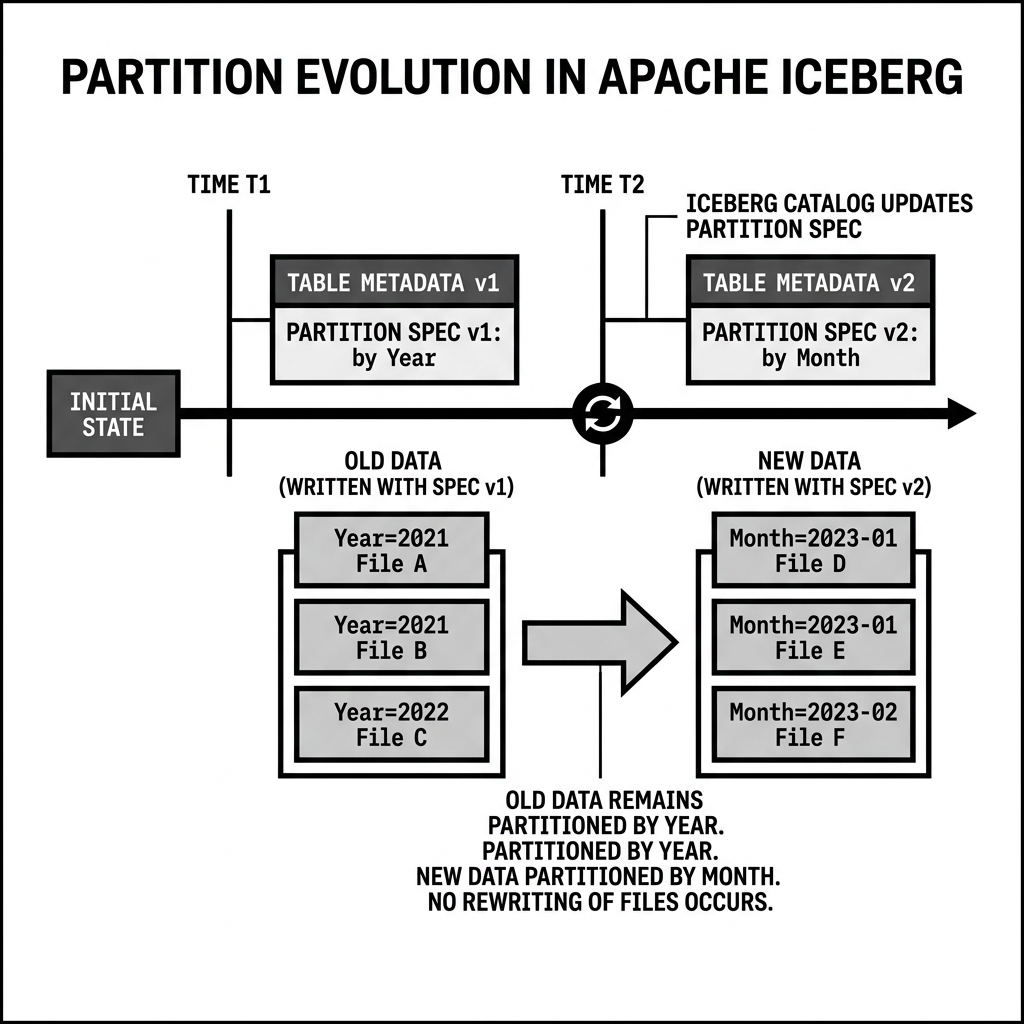
Partition Evolution
What happens if your data volume explodes? Originally, partitioning by year made sense. But two years later, you have so much data that a single year’s partition contains 100 terabytes, making queries unacceptably slow. You need to change the partitioning to month.
In legacy systems, this was a nightmare. You had to create a brand new table with the new monthly partition scheme, and then run a massive, expensive ETL job to copy and rewrite every single historical file from the old table to the new one.
In Iceberg, the Partition Spec is versioned. You simply execute an ALTER TABLE command to change the partition scheme from year(timestamp) to month(timestamp).
Iceberg creates a new metadata file with Partition Spec v2. From that moment forward, any new data written to the table will be partitioned by month. The historical data remains untouched, partitioned by year under Partition Spec v1.
Because the Iceberg metadata tree understands both specs simultaneously, a query engine can seamlessly read across the entire table, applying the correct partition pruning logic to the old files (by year) and the new files (by month), all without ever rewriting a single byte of historical data.
Diagram 2: Partition Evolution