Polaris Catalog
Apache Polaris is the premier open-source implementation of the Apache Iceberg REST Catalog specification — a production-grade, vendor-neutral catalog service that provides hierarchical Role-Based Access Control (RBAC), dynamic credential vending, multi-cloud storage support, and federated catalog management for data lakehouse environments. Originally developed by Snowflake and donated to the Apache Software Foundation in June 2024 (where it became a top-level project), Polaris represents the most complete, standards-compliant, and governance-rich reference implementation of the Iceberg catalog concept available in the open-source ecosystem.
Polaris serves as the architectural “catalog of record” for organizations that need a single, authoritative governance plane across a heterogeneous compute environment — Snowflake native queries, Apache Spark ETL pipelines, Trino analytical workloads, Apache Flink streaming jobs, and Dremio federated queries all accessing the same Iceberg tables through the same REST Catalog API, all governed by the same RBAC policies, and all receiving dynamically vended, scoped storage credentials that enforce table-level access control at the storage layer.
Origins and Governance
Polaris’s origin reflects the broader industry trajectory toward open interoperability in the lakehouse ecosystem. Snowflake created Polaris as an internal catalog service for their Iceberg-compatible external table feature, then open-sourced it in 2024 to establish a vendor-neutral governance standard that the entire industry could adopt. The ASF donation ensures that Polaris development is governed by community consensus rather than any single vendor’s roadmap — a critical requirement for a catalog standard that multiple competing vendors need to trust and implement against.
The project’s Apache governance structure means that Snowflake, Dremio, Tabular, AWS, Microsoft, and other organizations all participate in defining Polaris’s feature roadmap and specification through the standard ASF contribution process. This multi-vendor participation is the institutional guarantee of Polaris’s vendor neutrality.
Snowflake also offers Snowflake Open Catalog — a fully managed, hosted version of Polaris running as a Snowflake product. Open Catalog provides the same REST API, RBAC, and credential vending capabilities as open-source Polaris, but with Snowflake-managed infrastructure, integrated billing, and native Snowflake identity integration. Organizations can use open-source Polaris (self-hosted) or Snowflake Open Catalog (managed), with identical API compatibility between the two.
Architecture Overview
Polaris is a stateless REST API service backed by a persistence store for catalog metadata (table registrations, RBAC policies, service principal credentials). The service is designed for horizontal scalability — multiple Polaris instances can run behind a load balancer, with all catalog state in the shared persistence layer.
Persistence Backends
Polaris supports pluggable persistence backends for its catalog metadata:
In-memory (development/testing only): All catalog state is stored in-memory and lost when the service restarts.
Eclipse Link JPA with RDBMS: Production deployments use JPA (Java Persistence API) against a relational database. Polaris officially supports PostgreSQL and EclipseLink’s in-memory H2 (for testing). PostgreSQL is the recommended production backend.
Cloud-native backends (roadmap): The Polaris community is actively developing native support for DynamoDB and other cloud-native persistence backends to simplify cloud deployments.
Service Components
REST API Layer: The HTTP server implementing the Iceberg REST Catalog specification, plus Polaris-specific management endpoints for RBAC administration. Implemented using the Dropwizard framework in Java.
Authentication and Authorization: Polaris uses OAuth 2.0 bearer tokens for authentication. Every inbound API call must present a valid bearer token. Polaris validates the token against the registered service principals (for machine-to-machine calls) or against an integrated identity provider (for user-facing calls). After authentication, the authorization layer evaluates the caller’s catalog role assignments to determine what operations they are permitted to perform.
Credential Vending Engine: When a query engine requests table access, the credential vending engine generates short-lived cloud provider credentials scoped to the specific storage paths of the requested table. This is the component that translates Polaris RBAC policies into storage-layer enforcement.
Catalog Metadata Store: All persistent catalog state — catalog registrations, namespace hierarchies, table metadata pointer locations, service principal definitions, catalog role definitions, and role assignments — stored in the RDBMS-backed JPA persistence layer.
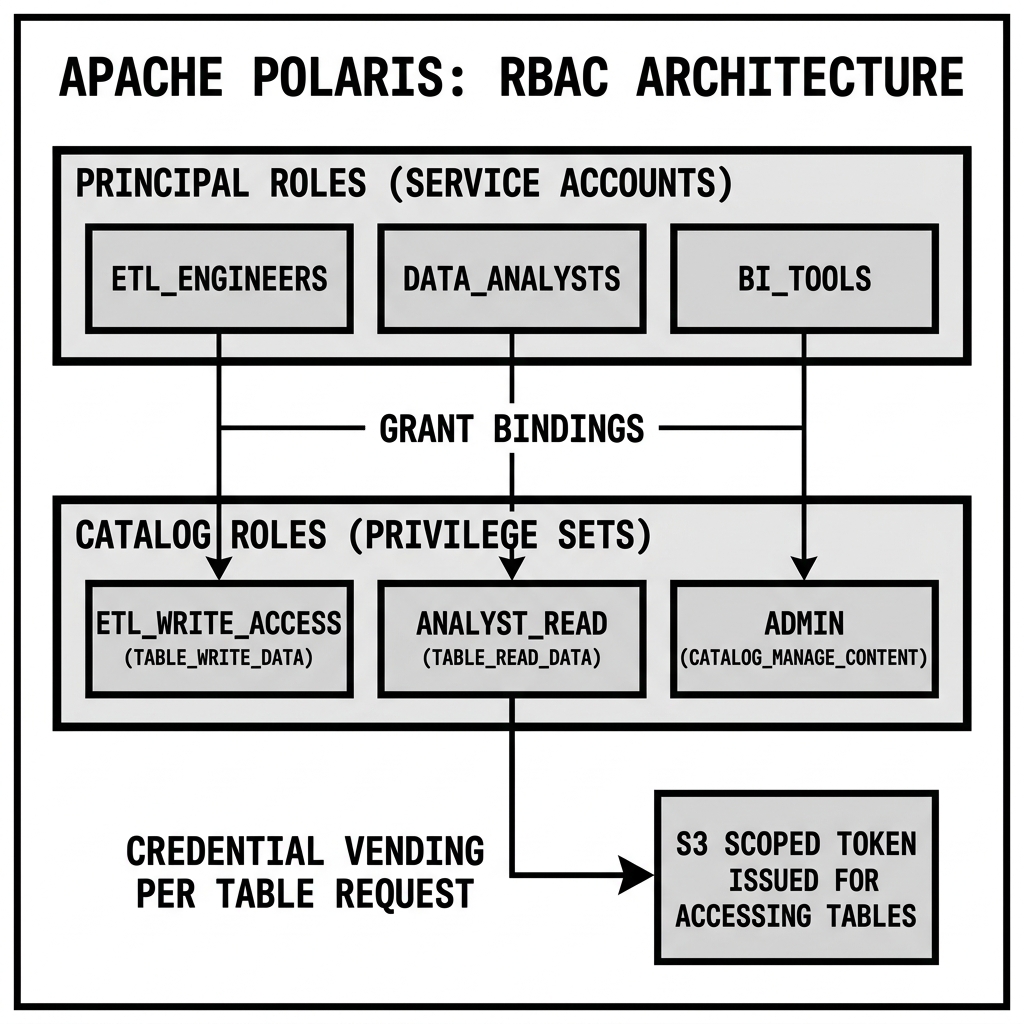
The RBAC Model
Polaris implements a hierarchical RBAC model specifically designed for multi-engine lakehouse environments. Understanding its structure is essential for designing governance policies for a Polaris-based deployment.
The Entity Hierarchy
Catalogs: The top-level organizational unit in Polaris. A Polaris instance can host multiple independent catalogs. Each catalog has its own namespace hierarchy, table set, RBAC policies, and storage configuration. Catalogs can be isolated environments (e.g., production, staging) or business domain groupings (e.g., analytics, finance, marketing).
Namespaces: Hierarchical groupings within a catalog (analogous to databases or schemas). Namespaces support multi-level nesting: analytics.sales.regional is a three-level namespace. Access control policies can be applied at any namespace level, enabling fine-grained delegation.
Tables: Individual Iceberg tables within namespaces. Tables are the most granular unit of access control in Polaris.
Service Principals: Machine identities (for compute engines) or user identities (for individual engineers). Each service principal has a client ID and client secret (for OAuth 2.0 credential authentication). A service principal represents a Spark cluster, a Trino coordinator, a specific user’s dbt project, etc.
Principal Roles: Named groupings of service principals. A principal role (e.g., data_engineers, analysts_read_only, etl_pipelines) can include multiple service principals, simplifying the assignment of access policies to groups of engines or users.
Catalog Roles: Named sets of privileges defined within a specific catalog. A catalog role specifies exactly what operations are permitted on which resources within the catalog. Examples:
CATALOG_MANAGE_CONTENT— Full DDL and DML permissions on all tables.TABLE_READ_DATAon namespaceanalytics.sales— Read-only access to all tables in the sales namespace.TABLE_WRITE_DATAon specific tableanalytics.sales.orders— Write access to one specific table.
Role Assignments: The binding that connects a principal role to a catalog role, granting all principals in that principal role the privileges defined in that catalog role.
The Permission Evaluation Flow
When a query engine (authenticated as service principal spark_etl_cluster) calls the Polaris REST API to load table analytics.sales.orders:
- Polaris authenticates the bearer token and identifies the caller as
spark_etl_cluster. - Polaris finds all principal roles that
spark_etl_clusterbelongs to (e.g.,etl_pipelines). - Polaris finds all catalog roles assigned to those principal roles within the
analyticscatalog (e.g.,etl_write_access). - Polaris evaluates whether
etl_write_accessincludesTABLE_READ_DATApermission on theanalytics.sales.orderstable (directly or inherited from a parent namespace grant). - If permission is granted: proceed to generate credentials and return table metadata.
- If permission is denied: return HTTP 403 Forbidden.
This evaluation happens on every API call, ensuring that permission changes (revoking a catalog role, modifying a principal role’s catalog role assignments) take effect immediately on the next API call without requiring any engine restart or credential refresh.
Credential Vending: The Security Architecture
Credential vending is Polaris’s most transformative security capability, and it is one of the primary reasons organizations choose Polaris over simpler catalog alternatives.
The Traditional Security Problem
In traditional data lake security architectures, compute engines (Spark clusters, Trino workers) are granted IAM permissions to access the object storage bucket where table data lives. This creates several problems:
- A Spark cluster with access to
s3://bucket/can read any table in the bucket, regardless of whether the user running the query is authorized to access that data. The IAM permission is granted to the compute engine, not to the user. - If a malicious actor gains access to the Spark cluster’s IAM role credentials (e.g., through an SSRF attack against the EC2 metadata endpoint), they gain access to all data in the bucket with no per-table granularity.
- Revoking a specific user’s access to a specific table requires either a full IAM policy update (slow, coarse-grained) or a more complex Lake Formation integration.
Polaris’s Credential Vending Solution
With Polaris, compute engines have no standing storage credentials. Instead, the Polaris storage configuration holds the cloud provider credentials needed to generate scoped, short-lived access tokens. When a query engine loads a table from Polaris:
- Polaris verifies the caller’s permission to access the table (through the RBAC evaluation above).
- Polaris uses its server-side cloud credentials to call the cloud provider’s STS (Security Token Service) with a policy that restricts access to the specific S3 prefix (or GCS bucket path, or Azure container path) where the table’s data files reside.
- The STS generates a short-lived credential set (typically with a 15-minute to 1-hour TTL) that is valid only for the specific storage paths of this table.
- Polaris returns the short-lived credentials to the query engine alongside the table metadata.
- The query engine uses these scoped credentials to read and write the table’s Parquet files, and cannot use them to access any other table’s data.
If the query engine’s credentials expire before the query completes (for very long queries), the engine calls Polaris again to refresh the credentials. Polaris re-evaluates the caller’s permissions at refresh time — if the user’s access has been revoked since the initial load, the refresh fails and the query terminates without access to the data.
This architecture achieves genuine table-level access control at the storage layer, enforced through the cloud provider’s own IAM system, with no standing credentials on the compute side.
Multi-Cloud Storage Support
Polaris supports storage credential vending for all three major cloud providers:
- AWS S3: Uses AWS STS
AssumeRoleto generate temporary access key + secret key + session token credentials scoped to specific S3 prefixes via an IAM policy condition. - Azure Data Lake Storage (ADLS Gen2): Uses Azure Managed Identity or Service Principal token exchange to generate SAS tokens scoped to specific blob container paths.
- Google Cloud Storage (GCS): Uses GCP Service Account credential impersonation to generate short-lived tokens scoped to specific GCS bucket paths.
A single Polaris instance can serve catalogs backed by storage on multiple cloud providers simultaneously, enabling true multi-cloud data governance where the same RBAC policies govern access to data on S3, ADLS, and GCS from a single catalog service.
Federated Catalogs
One of Polaris’s most powerful features is its ability to act as a federated catalog — managing multiple underlying catalog backends through a single Polaris API surface.
A Polaris federated catalog can include:
Internal catalogs: Tables fully managed by Polaris, where Polaris controls both the metadata pointer and the access governance.
External catalogs: Tables whose metadata is managed by a separate catalog service (e.g., AWS Glue, another REST Catalog server, or a Hive Metastore), but whose access governance is managed by Polaris. Polaris periodically synchronizes metadata from the external catalog and enforces its own RBAC policies on top of the external catalog’s table set.
This federation capability allows organizations with existing catalog infrastructure (Glue, HMS) to centralize their access governance in Polaris without requiring a full catalog migration. New tables and catalogs are created natively in Polaris; legacy tables remain in their original catalogs but are governed through Polaris’s RBAC.
Polaris in the Interoperability Ecosystem
Polaris’s implementation of the complete Iceberg REST Catalog API makes it accessible to any engine with an Iceberg REST Catalog client:
- Apache Spark: Through the Iceberg Spark runtime with
catalog.type=restconfiguration pointing to the Polaris URL. - Trino: Through the Iceberg Trino connector with
iceberg.catalog.type=rest. - Apache Flink: Through the Iceberg Flink runtime with
catalog-type=rest. - Dremio: Through Dremio’s native Polaris catalog integration, with RBAC-aware credential vending fully supported.
- Snowflake: Through Snowflake’s native Iceberg external table feature, which supports Polaris as the catalog backend.
This engine-agnostic compatibility is Polaris’s fundamental value proposition: it is the catalog that works with every engine, governed by a single, authoritative RBAC model, with table-level access control enforced at the storage layer through credential vending.
Conclusion
Apache Polaris is the most complete realization of the vision that motivated the Iceberg REST Catalog specification: a vendor-neutral, standards-compliant, governance-rich catalog service that any engine can access and any organization can adopt. Its hierarchical RBAC model provides the fine-grained access control that enterprise data governance requires. Its credential vending mechanism enforces table-level security at the cloud storage layer without requiring any changes to compute engine IAM policies. Its multi-cloud storage support enables genuine cross-cloud lakehouse governance. And its federated catalog capability provides a realistic migration path for organizations with existing catalog infrastructure. As the Apache Iceberg ecosystem continues to standardize around the REST Catalog protocol, Polaris is positioned to be the reference implementation that defines what a production-grade open lakehouse catalog looks like.
Visual Architecture