Polyglot Persistence
For a long time, the default answer to any data storage question in enterprise software development was a relational database. Whether an application needed to store financial transactions, user session states, hierarchical product catalogs, or application logs, developers modeled it into tables, rows, and columns and put it in Oracle, PostgreSQL, or SQL Server. The relational database was treated as a universal hammer, making every data storage requirement look like a relational nail.
This monolithic approach to storage eventually broke down under the weight of web-scale applications. Storing millions of transient user session tokens in a relational database caused lock contention and slowed down core transactional processing. Storing deeply nested, highly variable JSON documents in a rigid tabular schema required painful and brittle normalization. Attempting to perform full-text search across millions of text records using standard SQL LIKE clauses was prohibitively slow.
Polyglot Persistence, a term popularized by Martin Fowler and Pramod Sadalage in their book NoSQL Distilled, is the architectural response to this problem. It is the practice of using different data storage technologies to handle different data access patterns within a single application or enterprise architecture. Rather than forcing all data into one paradigm, polyglot persistence advocates choosing the right tool for the job.
The Right Tool for the Job
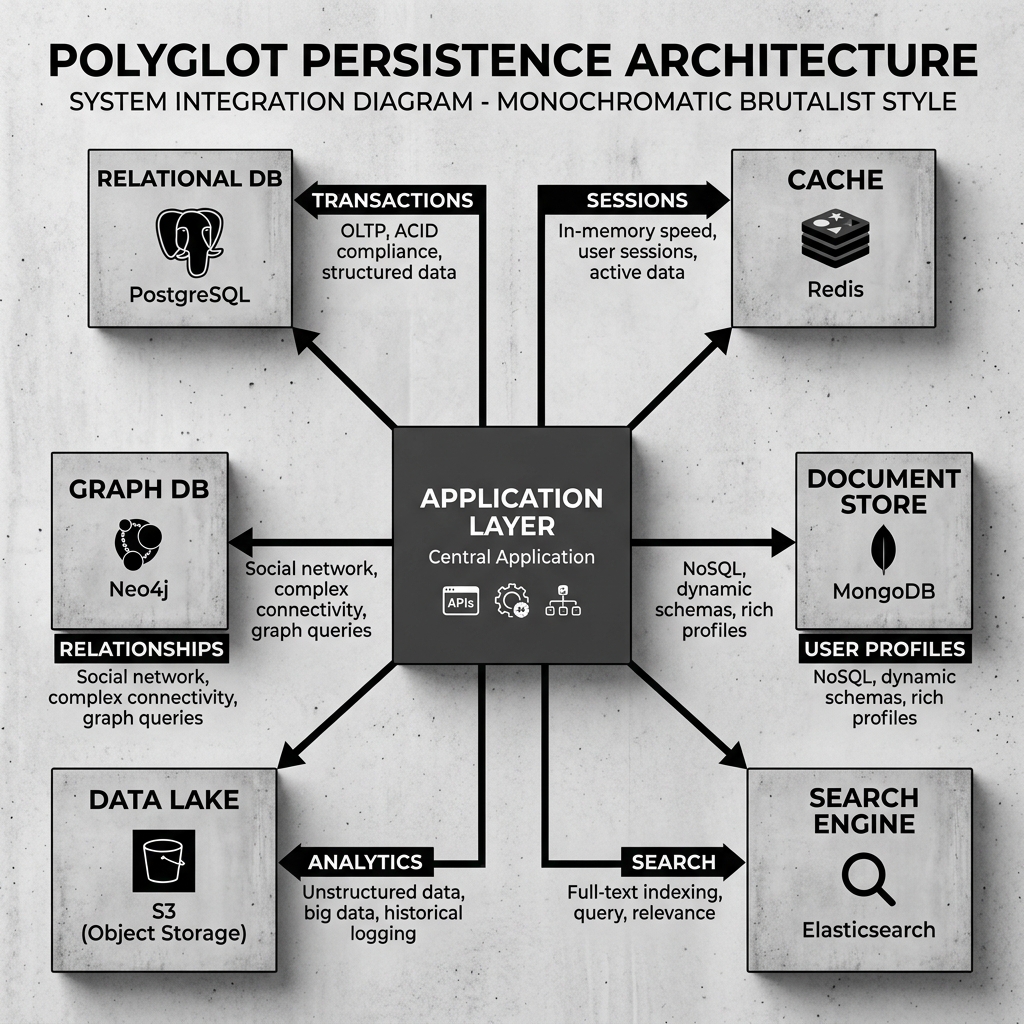
A typical modern e-commerce platform provides an excellent illustration of polyglot persistence in practice.
The core financial transactions—processing an order, deducting inventory, charging a credit card—require strict ACID guarantees. If the system crashes mid-order, the state must roll back cleanly. For this operational workload, a relational database (like PostgreSQL) remains the correct choice.
However, the user’s shopping cart state is highly transient. It needs to be read and updated extremely fast, often dozens of times per session, but if the data is lost, the worst outcome is a mildly annoyed user. Storing this in PostgreSQL would place unnecessary load on the transactional system. Instead, the application stores cart sessions in an in-memory key-value cache (like Redis).
The product catalog consists of highly variable data. A laptop has completely different attributes (RAM, CPU speed) than a t-shirt (size, color). Modeling this in a rigid relational schema leads to sparse, unwieldy tables. Instead, the application stores product profiles in a document database (like MongoDB), where each product is represented as a flexible JSON document.
When a user types “blue running shoes” into the search bar, the application needs to perform fuzzy matching, stemming, and relevance scoring across millions of product descriptions. Relational databases are poor at this. Instead, the application indexes the catalog data into a search engine (like Elasticsearch) specifically designed for full-text retrieval.
Finally, the application generates terabytes of clickstream logs detailing every button a user clicks. This data needs to be stored cheaply and analyzed in bulk later to train recommendation models. This data is streamed directly into an object storage data lake (like Amazon S3).
Diagram 1: Polyglot Persistence Architecture
The Costs of Polyglot Persistence
While polyglot persistence solves the problem of using the wrong tool for the job, it introduces new challenges. The most significant is operational complexity.
Instead of needing database administrators who are experts in just one technology, the engineering organization now needs expertise in five different systems. Each database technology has its own backup procedures, its own high-availability architecture, its own query language, and its own scaling characteristics.
Furthermore, polyglot persistence creates data consistency challenges. If a product’s price is updated in the relational database, that change must also be propagated to the search index and the document store. This requires complex event-driven architectures and distributed transaction coordination, often relying on Change Data Capture (CDC) streams to keep the various datastores synchronized. The system transitions from strong consistency (guaranteed by a single relational database) to eventual consistency across the polyglot ecosystem.
Polyglot Persistence in the Lakehouse Era
In the context of data analytics and the data lakehouse, the concept of polyglot persistence takes on a slightly different shape.
The data lakehouse itself is an attempt to reduce polyglot persistence for analytical workloads. By using open table formats like Apache Iceberg, the lakehouse allows a single storage repository (the object store) to serve the use cases that previously required both a data lake (for raw files) and a data warehouse (for structured SQL querying).
However, the lakehouse does not eliminate polyglot persistence entirely; it merely shifts the boundary. The operational applications generating the data still rely on specialized databases (graph, time-series, document, relational). The lakehouse becomes the central analytical convergence point where data from all these specialized operational systems is brought together.
For example, an organization might use a specialized time-series database (like InfluxDB) to capture high-frequency IoT sensor readings, and a specialized vector database (like Pinecone) to serve AI embeddings for a chatbot application. Both of these specialized stores feed their historical data into the central Apache Iceberg lakehouse. The lakehouse then serves as the unified historical repository, allowing data scientists to join the time-series sensor data with the vector embeddings and the relational customer data to train new models.
Diagram 2: Polyglot Persistence in the Lakehouse Ecosystem

Striking the Balance
The goal of architectural design is not to use as many database technologies as possible. Every new database type added to a system increases operational overhead exponentially. The goal is to introduce a new persistence technology only when the existing technologies fail to meet a specific, critical requirement.
If an application’s search needs are simple, the basic text search capabilities built into PostgreSQL might be sufficient. Adding Elasticsearch just to check a “polyglot” architectural box is an anti-pattern. However, when an application genuinely hits the scaling or functional limits of a single paradigm, polyglot persistence provides the framework for distributing the workload across specialized systems designed specifically for those access patterns.