Presto
Presto (often referred to as PrestoDB to distinguish it from its fork, Trino) is an open-source, distributed SQL query engine designed for running interactive analytic queries against data sources of all sizes, ranging from gigabytes to petabytes. Like Trino, Presto decouples compute from storage, allowing users to query data where it lives without requiring an expensive, slow data movement or ingestion process. Presto remains a critical piece of data infrastructure at massive technology companies, particularly those operating at hyperscale.
Core Definition
The story of Presto is fundamentally tied to the evolution of big data at Facebook. In 2012, Facebook’s data warehouse team realized that Apache Hive, which translated SQL queries into MapReduce jobs, was far too slow for interactive data exploration. Analysts were waiting hours for queries to return. To solve this, a small team of engineers built Presto from scratch as a distributed, in-memory engine utilizing Massively Parallel Processing (MPP) principles.
Presto was open-sourced in 2013 and quickly gained adoption across the industry due to its incredible speed and flexibility. However, in 2018, the original creators of Presto departed Facebook due to differing visions regarding the project’s governance and direction. They created a fork initially called PrestoSQL (later rebranded to Trino). Facebook retained control over the original project, now managed under the Presto Foundation (part of the Linux Foundation) and heavily supported by companies like Meta, Uber, and ByteDance.
At its core, Presto provides a unified SQL interface over a heterogeneous mix of data sources. Through its connector architecture, Presto allows users to query data residing in Hadoop Distributed File System (HDFS), Amazon S3, MySQL, PostgreSQL, Cassandra, and many other systems. A single SQL statement can join data from an operational NoSQL database with historical logs sitting in an Apache Iceberg table on object storage.
Architecture and Components
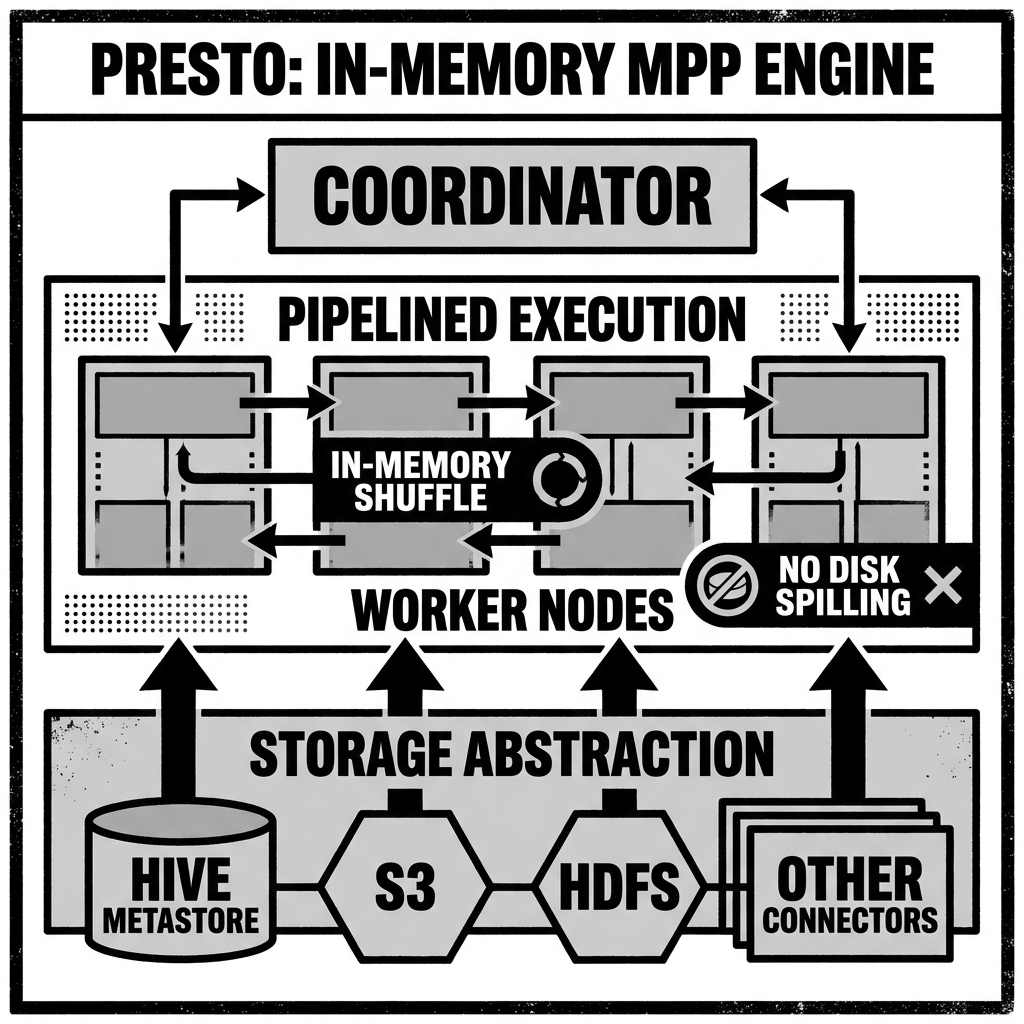
The architecture of Presto is virtually identical to that of Trino, given their shared heritage. It employs a master-worker topology.
The Coordinator node is the central management server. It receives requests from the client, parses the SQL statement, and creates a logical query plan. It then translates this logical plan into a distributed, physical execution plan. The Coordinator leverages the metadata provided by the source systems (via connectors) to optimize the query, pushing down filters and selecting the most efficient path for data retrieval.
The Worker nodes execute the physical plan generated by the Coordinator. They are responsible for fetching data from the external storage systems, executing operations such as aggregations, joins, and filters in memory, and exchanging data with other workers during shuffle phases. The final results are collected by the Coordinator and streamed back to the user.
Presto achieves its high performance by executing processing entirely in memory and pipelining data between stages over the network. This avoids the expensive disk I/O overhead that plagued earlier generations of big data tools. Furthermore, Presto utilizes byte-code generation to compile specific parts of the query execution plan into highly optimized machine code at runtime.
Presto in the Modern Lakehouse
While Presto was originally built to query raw CSV, JSON, and Parquet files managed by the Hive Metastore, it has evolved to support the requirements of the modern data lakehouse. The Presto community has developed robust integrations with open table formats like Apache Iceberg and Apache Hudi.
When a user queries an Iceberg table using Presto, the engine bypasses traditional directory listing. Instead, the Presto Coordinator interacts directly with the Iceberg catalog to retrieve the table’s current metadata snapshot. By evaluating the query predicates against the column-level statistics stored in the Iceberg manifest files, Presto can aggressively prune data. It only assigns read tasks to the Worker nodes for the specific Parquet files that actually contain the data relevant to the query.
This integration transforms the data lake into a highly performant, transactional data warehouse. Users can run interactive aggregations over petabytes of object storage while Iceberg handles the ACID transactions and metadata tracking underneath.
The Presto vs. Trino Divergence
Because Presto and Trino share the exact same codebase prior to 2018, they are fundamentally similar engines. However, the two projects have diverged in their focus and community dynamics over the years.
Trino (the fork maintained by the original creators) has seen massive adoption in the broader open-source community and among enterprise vendors. It has focused heavily on expanding its connector ecosystem, improving ANSI SQL compliance, and adding fault-tolerant execution modes to better support long-running ETL workloads.
Presto (the original project maintained by the Presto Foundation) has been heavily driven by the needs of hyperscale tech companies like Meta, Uber, and ByteDance. Consequently, the Presto roadmap has often prioritized extreme scalability, resource isolation, and deep integration with custom internal infrastructure. One of the most significant recent developments in the Presto ecosystem is the Velox project.
Velox is an open-source C++ database acceleration library developed by Meta. The Presto community has been working to replace Presto’s original Java-based worker execution engine with Velox (an initiative often referred to as Prestissimo). By moving the heavy lifting of data processing from the Java Virtual Machine to native C++, Presto aims to achieve massive improvements in CPU efficiency and memory management, pushing the boundaries of query performance even further.
Summary and Tradeoffs
Presto revolutionized the big data landscape by proving that interactive SQL was possible at petabyte scale directly on distributed storage. Its decoupled architecture, in-memory MPP processing, and robust federation capabilities make it a foundational technology for modern data platforms.
The primary tradeoff with Presto, similar to Trino, is its heavy reliance on in-memory execution. Queries that require massive memory footprints for complex joins or global aggregations can fail if the cluster’s memory is exhausted. Furthermore, managing and tuning a large-scale Presto cluster requires dedicated engineering resources and deep expertise in distributed systems.
While the community split between Presto and Trino has caused some confusion in the market, both engines represent the pinnacle of open-source distributed SQL processing. For organizations operating at the absolute extremes of scale, Presto’s continued evolution, particularly its integration with native C++ execution engines like Velox, ensures it remains a dominant force in the data lakehouse ecosystem.
Visual Architecture