Project Nessie
Project Nessie is an open-source transactional catalog for Apache Iceberg that introduces Git-like version control semantics to data lakehouse metadata management. While traditional catalogs — Hive Metastore, AWS Glue, and most REST Catalog implementations — track only the current state of each table (a single mutable pointer per table to its latest metadata file), Nessie tracks the state of the entire catalog as a sequence of immutable, content-addressed commits that span all tables simultaneously.
This architectural difference is not merely academic. It is the foundation for a set of capabilities that no traditional catalog can provide: the ability to create isolated branches of the entire data lakehouse (not just individual tables) where experimental transformations, schema migrations, and data quality validation can occur without affecting production; the ability to atomically commit changes to many tables in a single operation that either fully succeeds or fully fails; and the ability to roll back the entire catalog state — all tables, all at once — to any previous point in history with a single command.
Nessie was originally developed by Dremio and is now maintained as a Cloud Native Computing Foundation (CNCF) sandbox project under open-source governance. It is deeply integrated with Dremio’s query engine and serves as the catalog backing Dremio’s Arctic managed catalog service. It is also fully compatible with Apache Spark, Apache Flink, and any other query engine that supports the Iceberg Nessie catalog connector or the Iceberg REST Catalog API (which Nessie now implements).
The Conceptual Model: A Git for Data
To understand Nessie, the Git analogy is genuinely instructive — not as a metaphor but as a precise structural description.
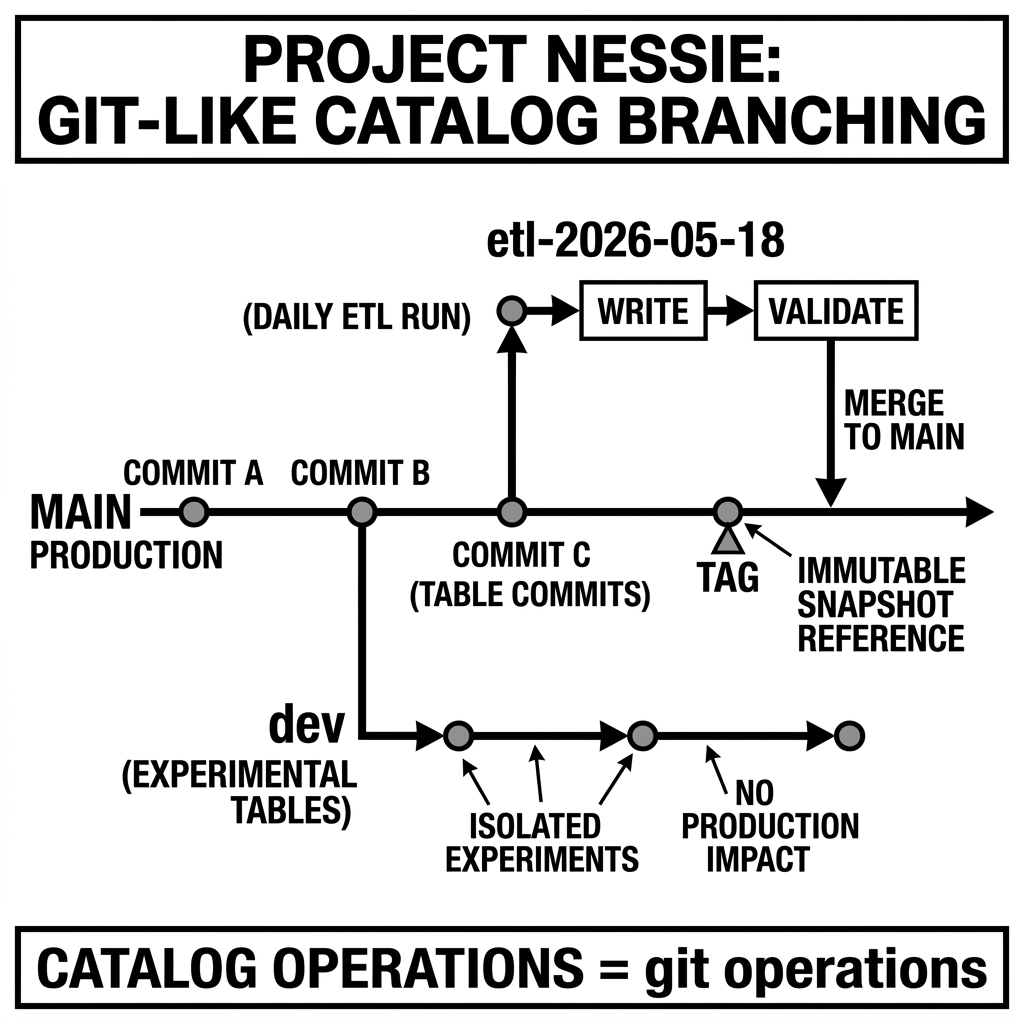
In Git, a repository contains a collection of files. Every git commit creates an immutable, content-addressed snapshot of the entire repository state at that moment. Commits form a directed acyclic graph (DAG), where each commit references its parent commit. Named branches (like main or feature/new-model) are mutable pointers to the tip of a commit chain. Tags are immutable pointers to specific commits. Merging a branch is the operation of advancing one branch pointer to include the commits from another.
In Nessie, a catalog is the repository. The “files” are the table metadata pointers — the mapping from each table’s logical name to its current Iceberg metadata file URI. Every Nessie commit is an immutable, content-addressed snapshot of the entire catalog’s table-metadata-pointer state at that moment. Commits form a directed acyclic graph. Named branches (like main or etl/staging) are mutable pointers to the tip of a commit chain. Tags are immutable pointers to specific commits. Merging a Nessie branch is the operation of advancing one branch’s catalog state to include the table metadata pointer changes from another branch.
The structural isomorphism is complete. Every Git concept has a precise Nessie analog, and the properties that make Git valuable for software engineering — isolation, auditability, rollback, concurrent development without interference — all translate directly to data engineering.
The Technical Architecture
The Nessie Commit Object
At the heart of Nessie’s versioning model is the Commit object — an immutable record stored in Nessie’s backend database that represents a single atomic change to the catalog state.
Each Commit contains:
hash: A cryptographic hash of the commit’s content (the parent hash + the set of table metadata pointer changes it contains). This hash is the commit’s globally unique identifier.
parentHash: The hash of the parent commit that this commit was based on. Every commit except the initial root commit has exactly one parent (for fast-forward merges) or two parents (for true merge commits).
operations: A list of individual table operations included in this commit. Each operation is one of:
PUT— Update or create a table’s metadata pointer to a new URI.DELETE— Remove a table’s registration from the catalog.UNCHANGED— An explicit assertion that a table’s pointer has not changed (used in merge conflict detection).
committer: The identity of the entity that performed the commit (a user or service account).
commitTime: The wall-clock timestamp of the commit.
message: A human-readable description of the commit’s purpose.
metadata: Optional key-value properties for attaching arbitrary metadata to the commit (for audit trails, CI/CD pipeline identifiers, etc.).
The Branch Pointer
A Nessie branch is simply a named, mutable pointer to a specific commit hash. Nessie stores one record per branch: a mapping from the branch name (e.g., main) to the current tip commit hash.
When a writer commits a new table state to the main branch:
- The writer sends a Nessie commit request containing the table name and the new metadata URI.
- Nessie creates a new Commit object with the operation
PUT(table_name, new_metadata_uri)and the parent hash set to the current tip ofmain. - Nessie performs a compare-and-swap on the branch pointer: if the current
maintip hash matches the expected hash (the one the writer started from), advance themainpointer to the new commit hash. - If the compare-and-swap fails (another writer has already advanced
mainsince the writer started), return a conflict error. The writer must retry.
This compare-and-swap is functionally equivalent to the Iceberg REST Catalog’s atomic commit protocol, but it operates at the catalog level (over the entire catalog state) rather than at the individual table level.
The Backend Database
Nessie’s commit history and branch pointer data is stored in a pluggable backend database. Supported backends include:
- In-memory (for testing only)
- RocksDB (embedded, single-node)
- MongoDB
- Amazon DynamoDB
- PostgreSQL / CockroachDB (via JDBC)
- Google Cloud Spanner
- Apache Cassandra
For production deployments, DynamoDB, PostgreSQL, and MongoDB are the most common choices. DynamoDB’s conditional writes provide native compare-and-swap semantics for branch pointer updates. PostgreSQL’s SERIALIZABLE transactions provide equivalent guarantees. The choice of backend determines Nessie’s scalability, availability, and consistency characteristics.
Core Capabilities
Branching: Isolated Development Environments
Creating a Nessie branch is an O(1) metadata operation — it simply records a new named pointer to the current commit hash. No data is copied. No table metadata files are duplicated. The branch instantly has access to the same set of table metadata pointers as its parent branch, but any subsequent commits on the branch advance only the branch’s pointer, not the parent’s.
The practical use cases for branching in a data lakehouse context are numerous:
ETL Development and Testing: A data engineer developing a new transformation pipeline creates a branch from main, runs the pipeline on the branch (which may write new table metadata to Nessie on the branch), validates the output, and merges the branch to main only after validation passes. If validation fails, the branch is simply discarded — no cleanup of main is required.
Schema Migration: A schema evolution that adds a column to a critical production table can be performed on a branch first. The new schema is applied on the branch, tested against the full production data (which is shared by reference with the main branch), and merged to main only when the migration is confirmed safe.
Multi-Team Parallel Development: Two teams can work on different parts of the data lake simultaneously on separate branches, without any risk of one team’s work breaking the other’s. Their branches are completely isolated at the catalog level.
CI/CD Pipelines for Data: Each pull request in a data engineering repository can be associated with a Nessie branch that is automatically created when the PR opens and merged (or discarded) when the PR is closed. This brings software engineering’s change management discipline to data engineering workflows.
Tagging: Immutable Catalog Snapshots
A Nessie tag is an immutable pointer to a specific commit hash. Unlike branch pointers (which advance with each new commit), tag pointers never move once set.
Tags provide point-in-time catalog snapshots with permanent names:
CREATE TAG quarterly_report_2026_Q1
ON REFERENCE main;This creates a tag pointing to the current main tip commit. Even if main continues to advance with new commits, quarterly_report_2026_Q1 will always refer to the catalog state at the moment of tagging.
Any query engine can subsequently set its Nessie reference to the tag and query the catalog state as it existed at that point in time — seeing the table schemas, metadata versions, and snapshot IDs that existed at that commit, regardless of how the tables have changed since.
This enables:
- Reproducible reporting: Monthly financial reports can be re-run against a tagged catalog state months or years later, and will produce identical results.
- Audit compliance: Regulators asking “what was the data in this table on date X?” can be answered precisely by querying the appropriate tag.
- Debugging: If a data quality issue is discovered today, engineers can query last week’s tagged catalog state to identify exactly when and how the issue was introduced.
Multi-Table Atomic Commits
Because each Nessie commit captures the state of all tables in the catalog simultaneously, a single commit can include PUT operations for multiple tables at once. All of those table metadata pointer updates are applied atomically — either all advance in the same commit, or none do.
This capability is uniquely enabled by Nessie’s catalog-level versioning. No other commonly deployed Iceberg catalog (HMS, Glue, or most REST Catalog implementations) provides native multi-table atomicity.
Practical use cases include:
Atomic ETL Pipelines: A pipeline that reads from a source table and writes to a destination table and a separate audit log table can commit all three table state changes (source snapshot advancement, destination new files, audit log new entry) in a single Nessie commit. If the commit fails, none of the three tables advance — no partial writes are visible anywhere in the catalog.
Consistent Downstream Views: A dimensional model where a fact table and several dimension tables must be mutually consistent (e.g., a sales fact table and the product, customer, and date dimension tables) can be updated atomically as a single Nessie commit, guaranteeing that no query ever sees new fact data with old dimension data (or vice versa).
Zero-Copy Experimentation
Because Nessie branches share table metadata pointers by reference, running experiments on a branch incurs no data duplication cost. When an engineer creates a branch from main, the branch immediately points to all the same Iceberg data files as main. Running a transformation that appends new data on the branch writes new Parquet files but does not copy the existing data. Reading historical data on the branch reads the same Parquet files as main.
This zero-copy characteristic means that experimentation is not just functionally safe (branch changes don’t affect main) but economically safe (no storage costs for maintaining experiment environments). A team can run dozens of parallel experiments on different branches, each examining variations of the same base dataset, without multiplying their storage costs.
Nessie SQL API
Query engines with Nessie integration (notably Dremio, and Apache Spark with the Iceberg Nessie connector) expose Nessie’s version control operations directly through SQL:
-- Create a branch for ETL development
CREATE BRANCH etl_feature_branch AT BRANCH main;
-- Switch the session to work on the new branch
USE REFERENCE etl_feature_branch;
-- Run transformations on the branch
INSERT INTO analytics.orders_summary SELECT ... FROM raw.orders;
-- Create a tag on the validated state
CREATE TAG post_etl_validation AT BRANCH etl_feature_branch;
-- Merge validated changes back to main
MERGE BRANCH etl_feature_branch INTO main;
-- Roll back main to a previous state
ASSIGN BRANCH main TO TAG previous_known_good;This SQL API makes Nessie’s version control capabilities accessible to data analysts and engineers who are already comfortable with SQL, without requiring them to learn a separate CLI or GUI tool.
Nessie and the REST Catalog Protocol
Nessie implements the Apache Iceberg REST Catalog specification, making it compatible with any query engine that supports the Iceberg REST Catalog client. This means that engines which do not have a native Nessie connector can still connect to Nessie through the standard REST API, though they will only access the REST API’s capabilities (table CRUD, atomic single-table commit) rather than Nessie’s extended branching and multi-table commit capabilities, which require the Nessie-specific API extensions.
Conclusion
Project Nessie represents the most architecturally ambitious extension of the Iceberg catalog concept: rather than simply tracking the current state of individual tables, it applies Git’s complete version control model — commit history, branching, tagging, merging — to the entire catalog simultaneously. This architecture delivers isolation guarantees that no other catalog can match (branch-level isolation across all tables simultaneously), atomicity guarantees that go beyond individual tables (multi-table commits), and auditability guarantees that are permanent and immutable (the commit DAG is append-only). For organizations running sophisticated data engineering workflows — CI/CD for data pipelines, multi-team parallel development, regulatory compliance with point-in-time reproducibility requirements — Nessie’s Git-like catalog model provides capabilities that are increasingly recognized as foundational requirements for production data lakehouse governance, not optional advanced features.
Visual Architecture