Pushdown Optimization
Pushdown Optimization (specifically Predicate Pushdown and Projection Pushdown) is one of the most critical performance techniques in distributed data processing. It refers to the ability of a query engine to delegate data filtering and column selection operations directly to the underlying storage layer or database, rather than loading the entire dataset into the engine’s memory before filtering it. In the context of the open data lakehouse, pushdown optimization is the primary mechanism by which formats like Apache Iceberg and Parquet deliver blazing-fast query speeds.
Core Definition
To understand the value of pushdown optimization, one must understand the bottleneck it solves: data movement. In a distributed architecture, reading data from disk (or object storage like Amazon S3) and transferring it over the network to the compute nodes is the slowest and most expensive operation.
Imagine a user executes the following query against a massive, petabyte-scale table containing ten years of sales data:
SELECT customer_id, total_amount FROM sales WHERE order_year = 2026
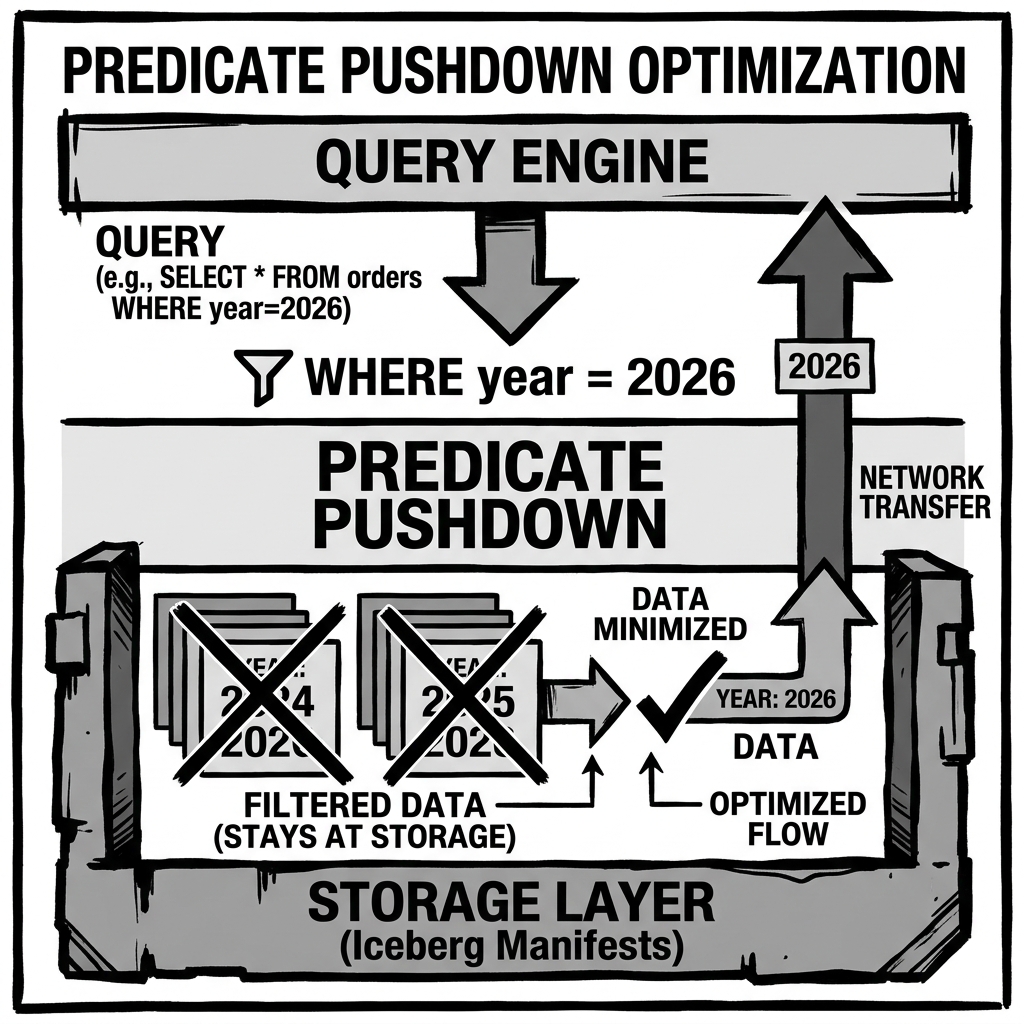
Without pushdown optimization, the compute engine (e.g., Apache Spark) would have to read all ten years of data from S3, transfer petabytes of data over the network into the executor’s memory, and then apply the WHERE clause to filter out 90% of the data. This is incredibly inefficient and would likely cause the engine to crash due to out-of-memory errors.
Pushdown optimization solves this. The compute engine “pushes down” the predicate (WHERE order_year = 2026) and the projection (SELECT customer_id, total_amount) to the storage layer. The storage layer intelligently identifies the files that contain data for 2026, extracts only the customer_id and total_amount columns from those specific files, and sends only that tiny fraction of data back over the network to the compute engine.
Types of Pushdown
Pushdown optimization generally falls into two primary categories: Projection Pushdown and Predicate Pushdown.
Projection Pushdown: This refers to pushing down the SELECT clause. It is fundamentally reliant on columnar storage formats like Apache Parquet or ORC. In a row-based format (like CSV), reading a single column requires reading the entire row. In a columnar format, data is stored column by column. If a table has 100 columns but the query only SELECTs two, projection pushdown instructs the storage reader to physically ignore the data blocks for the other 98 columns on disk. This immediately reduces disk I/O and network transfer by 98%.
Predicate Pushdown: This refers to pushing down the WHERE clause (the filter). This requires the storage layer to maintain statistics about the data. When writing a Parquet file, the writer records the minimum and maximum values for each column within the file’s footer (or row group metadata).
When a query contains the predicate WHERE total_amount > 1000, the engine reads the Parquet footer first. If the footer indicates that the maximum total_amount in this specific file is 500, the engine knows it is mathematically impossible for this file to contain relevant data. It completely skips reading the actual data blocks. This is known as Min-Max filtering or File Skipping.
Pushdown in the Open Lakehouse
While Parquet files support pushdown optimization at the individual file level, executing this across a data lake containing millions of files still requires opening and reading millions of footers, which is prohibitively slow.
Open table formats like Apache Iceberg elevate pushdown optimization from the file level to the table level. Iceberg extracts the column-level min/max statistics from the individual Parquet footers and aggregates them into its manifest files.
When a compute engine like Trino queries an Iceberg table, it does not need to touch the Parquet files at all to perform predicate pushdown. Trino reads the centralized Iceberg manifests, applies the filters against the aggregated statistics, and eliminates 99% of the irrelevant files using purely metadata operations. Only the absolute minimum necessary Parquet files are ultimately read from object storage.
Federated Query Pushdown
Pushdown optimization is also the defining feature of federated query engines. When Trino or Presto executes a query that joins data across different databases (e.g., querying a PostgreSQL operational database and an Iceberg lakehouse table), it utilizes federated pushdown.
If the user queries: SELECT * FROM postgres.users WHERE status = 'ACTIVE', the Trino coordinator does not pull the entire users table from PostgreSQL into its workers. It rewrites the query and pushes the WHERE status = 'ACTIVE' SQL statement directly to the PostgreSQL database. PostgreSQL executes the filter using its local B-Tree indices and returns only the active users to Trino. This minimizes network traffic between the source database and the federated engine.
Summary and Tradeoffs
Pushdown optimization is the unsung hero of modern big data architecture. Without projection and predicate pushdown, querying petabyte-scale data lakes would be physically impossible. The tight integration between compute engines, columnar file formats (Parquet), and table formats (Iceberg) is what guarantees that only the absolutely necessary bytes are scanned during a query.
The primary tradeoff with pushdown optimization is the upfront cost of calculating and storing the statistics required to make it work. Maintaining detailed min/max statistics, Bloom filters, and dictionaries requires extra CPU cycles during data ingestion and increases the size of the metadata files. If data is highly unsorted (e.g., a timestamp column with random values distributed across every file), the min/max statistics will overlap significantly, rendering predicate pushdown useless. Consequently, data engineers must frequently employ techniques like Z-Ordering or specific partition strategies to cluster related data together, thereby maximizing the efficiency of predicate pushdown during query execution.
Visual Architecture