REST Catalog
The Iceberg REST Catalog specification — commonly called the REST Catalog or IRC — is the single most architecturally significant standard to emerge from the Apache Iceberg project since the table format’s initial design. It defines a complete, vendor-neutral HTTP API that standardizes every interaction between a compute engine and an Iceberg catalog service: table discovery, schema loading, atomic commit, credential vending, and multi-table transaction coordination.
Before the REST Catalog specification, Iceberg catalog integration was a fragmented, connector-per-catalog engineering problem. Every combination of query engine and catalog required a distinct, maintained code path: Spark + Hive Metastore required the HMS Spark catalog connector; Trino + Glue required the Trino Glue catalog connector; Flink + Nessie required the Nessie Flink catalog connector. Each connector was independently implemented, independently maintained, and subject to its own bugs, feature gaps, and version compatibility constraints. The result was a combinatorial explosion of N engines × M catalogs requiring N×M connector implementations.
The REST Catalog specification collapses this to N + M: every engine implements the REST Catalog client once, and every catalog implements the REST Catalog server once. Any compliant engine can immediately work with any compliant catalog.
The Role of the REST Catalog in the Iceberg Architecture
To understand the REST Catalog’s architectural position, it is necessary to re-examine the Iceberg catalog’s fundamental responsibility: managing the pointer from a logical table name to the physical location of that table’s current metadata.json file on object storage.
This pointer management is the entire job of the catalog. Everything else in Iceberg — the metadata JSON files, the Manifest Lists, the Manifest Files, the Parquet data files — lives on object storage and is accessed directly by the compute engine using standard object storage APIs (S3, GCS, Azure Blob). The catalog is purely a metadata routing service: it tells compute engines where to find the current metadata, and it coordinates atomic updates to that routing information through the compare-and-swap commit protocol.
The REST Catalog specification is the standardized protocol for this metadata routing service. It defines:
- How engines discover table metadata: The API endpoints and response formats for loading table metadata.
- How engines commit new table states: The atomic commit protocol using compare-and-swap semantics.
- How engines receive storage credentials: The credential vending mechanism for secure, scoped object storage access.
- How engines manage table lifecycle: Create, drop, rename, list tables and namespaces.
The API Specification
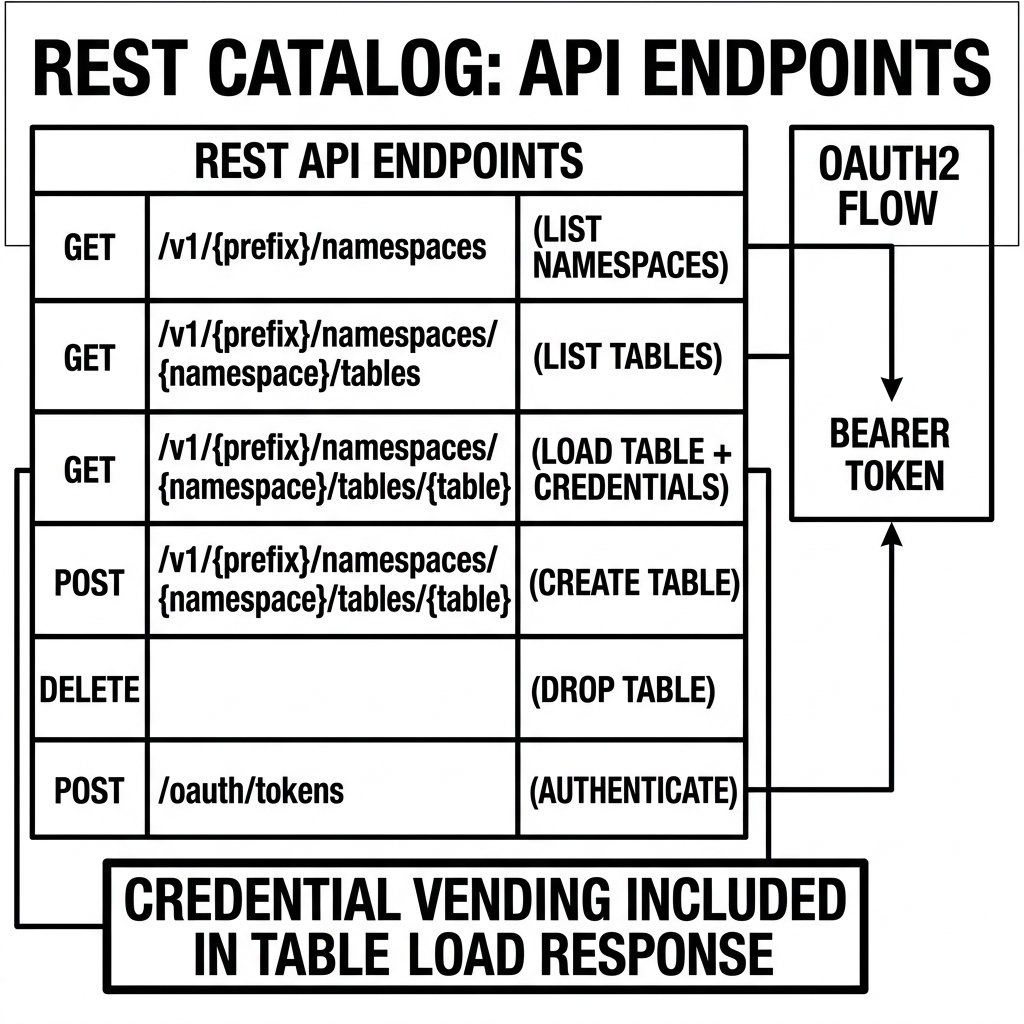
The REST Catalog API is formally defined using the OpenAPI specification, available in the Apache Iceberg repository. The API is organized around a prefix-based URL structure that allows a single REST Catalog server to host multiple independent catalog namespaces simultaneously.
Configuration Bootstrap: GET /v1/config
Every REST Catalog client session begins with a configuration fetch. The engine calls GET /v1/config (optionally with a warehouse parameter) and receives a response containing:
defaults: Default catalog properties that apply unless overridden by the engine’s local configuration.overrides: Catalog properties that must take precedence over any engine-side configuration.endpoints: An optional list of which REST Catalog endpoints are supported by this server, enabling capability negotiation between clients and servers.
This configuration bootstrap allows catalog administrators to communicate key settings to connecting engines automatically — the storage endpoint, the default file format, the default partition spec — without requiring those settings to be manually configured in each query engine’s catalog plugin configuration.
Namespace Operations
Iceberg organizes tables into a hierarchical namespace structure (analogous to database schemas). The REST Catalog provides standard CRUD endpoints for namespace management:
GET /v1/{prefix}/namespaces— List all top-level namespaces.POST /v1/{prefix}/namespaces— Create a new namespace with properties.GET /v1/{prefix}/namespaces/{namespace}— Get a namespace’s properties.HEAD /v1/{prefix}/namespaces/{namespace}— Check if a namespace exists.DELETE /v1/{prefix}/namespaces/{namespace}— Drop an empty namespace.POST /v1/{prefix}/namespaces/{namespace}/properties— Update namespace properties.
Namespaces support multi-level nesting: analytics.sales.regional is a valid three-level namespace, allowing fine-grained organization of tables across business domains.
Table Operations
The core CRUD operations for tables:
GET /v1/{prefix}/namespaces/{namespace}/tables— List all tables in a namespace.POST /v1/{prefix}/namespaces/{namespace}/tables— Create a new table. The request body includes the initial schema, partition spec, sort order, and table properties. The catalog creates the initialmetadata.jsonand registers the table.GET /v1/{prefix}/namespaces/{namespace}/tables/{table}— Load a table. This is the most frequently called endpoint. The response returns the complete table metadata JSON, the storage location, and optionally pre-vended storage credentials for accessing the table’s data files.DELETE /v1/{prefix}/namespaces/{namespace}/tables/{table}— Drop a table.POST /v1/{prefix}/namespaces/{namespace}/tables/{table}/rename— Rename a table (or move it to a different namespace).
The Commit Endpoint: POST /v1/{prefix}/namespaces/{namespace}/tables/{table}
The commit endpoint is the central ACID-critical operation. When a compute engine completes a write transaction and wants to advance the table to a new state, it sends a POST to the table’s URL with a request body containing:
identifier: The table name being committed.
requirements: A list of preconditions that must hold for the commit to succeed. The most important requirement is assert-current-schema-id and assert-table-uuid — but most critically, assert-ref-snapshot-id, which asserts that the table’s current snapshot ID is the one the writer started from. This is the compare-and-swap condition.
updates: A list of table metadata updates to apply if the requirements are met. Common updates include add-snapshot (adding the new Snapshot entry), set-snapshot-ref (advancing the main branch reference to the new snapshot), set-current-schema (if the schema changed), and add-partition-spec (if a new partition spec was introduced).
The catalog processes the request atomically:
- Validates all requirements against the current table state.
- If any requirement fails: returns HTTP 409 Conflict with details about which requirement was violated. The writer must retry.
- If all requirements pass: applies all updates atomically and advances the table to the new state. Returns HTTP 200 with the updated table metadata.
This is the complete compare-and-swap implementation: the assert-ref-snapshot-id requirement is the “compare” (verify the expected current state), and the atomic metadata update is the “swap” (advance to the new state). The HTTP 409 response is the conflict signal that triggers OCC retry.
Credential Vending
Credential vending is one of the REST Catalog’s most transformative security capabilities. In traditional lakehouse deployments, compute engines require direct, standing credentials to access the object storage bucket where table data lives. This typically means granting the Spark or Trino service account broad S3 bucket read/write permissions — a coarse-grained permission model that cannot enforce table-level access control at the storage layer.
The REST Catalog’s credential vending mechanism inverts this model. Instead of the compute engine holding standing storage credentials, the catalog server dynamically generates short-lived, scoped storage credentials on demand and provides them to the compute engine as part of the table load response.
The credentials are generated by the catalog server using server-side cloud IAM credentials with the appropriate scope for the specific table being accessed. For AWS S3, this means STS AssumeRole with a policy condition that restricts the generated session credentials to specific S3 prefixes (the table’s data directory). For GCS, this means generating a service account token scoped to specific bucket paths. For Azure, this means generating SAS tokens scoped to specific blob containers and prefixes.
The compute engine receives these short-lived credentials in the table load response and uses them exclusively to access the table’s data files. The credentials expire after a configurable TTL (typically 15 minutes to 1 hour). If the engine’s read operation spans longer than the TTL, it re-calls the catalog to refresh the credentials.
The security implications are significant:
- Zero standing credentials on compute engines: Spark clusters, Trino workers, and Flink task managers do not need any S3 IAM permissions. All storage access is mediated through the catalog’s credential vending.
- Table-level access control at the storage layer: The catalog can enforce that a specific engine session only receives credentials scoped to the specific tables that the authenticated user is authorized to access. Even if a user somehow obtained credentials for table A, they could not use those credentials to access table B.
- Dynamic revocation: If a user’s access is revoked in the catalog’s access control system, they simply stop receiving fresh credentials when their existing ones expire. Revocation takes effect within one TTL period without requiring any changes to storage-layer IAM policies.
Multi-Table Transactions
The REST Catalog specification includes support for multi-table commit operations — the ability to atomically commit changes to multiple Iceberg tables in a single operation that is either fully committed across all tables or rolled back from all of them.
The multi-table commit endpoint accepts a list of individual table commit requests (each with their own requirements and updates), and the catalog applies all of them atomically. If any individual table’s requirements fail, the entire multi-table commit fails, and no tables are modified.
This capability enables use cases that are impossible with single-table ACID semantics:
- Atomic ETL: A transformation pipeline that reads from tables A and B and writes to tables C and D can commit all four table state changes atomically. If the commit fails mid-way, no partial writes are visible anywhere.
- Referential integrity across tables: A fact table and its associated aggregate summary table can be updated atomically, ensuring they are always mutually consistent.
- Rollback safety: If an upstream pipeline failure requires rolling back a table, any downstream tables that were updated based on the upstream data can be rolled back atomically in the same operation.
Multi-table transactions are currently implemented by a subset of REST Catalog servers (including Nessie, which has native multi-table commit semantics through its Git-like commit model), and support is expanding as the specification matures.
REST Catalog Implementations
The REST Catalog specification is implemented by a growing ecosystem of catalog services:
Apache Polaris: The premier open-source REST Catalog implementation, donated by Snowflake to the Apache Software Foundation. Provides full REST API compliance, fine-grained RBAC, credential vending for AWS and Azure, and multi-catalog federation.
Project Nessie: Implements the REST Catalog API on top of Nessie’s Git-like versioned catalog backend. Every table commit creates a Nessie commit in a versioned branch, providing all REST API capabilities plus Git-like branching, tagging, and multi-table atomic commits.
Snowflake Open Catalog: Snowflake’s managed Polaris-based catalog offering, providing a hosted REST Catalog that enables external engines (Spark, Trino, Flink, Dremio) to read Snowflake-managed Iceberg tables through the standard REST API.
AWS Glue Iceberg REST endpoint: AWS has added REST Catalog compatibility to AWS Glue, allowing engines with the Iceberg REST Catalog client to connect to Glue without the engine-specific Glue connector.
Lakeformation REST Catalog: AWS Lake Formation has added REST Catalog support, extending credential vending through its fine-grained access control system to any REST Catalog-compatible engine.
The REST Catalog as the Lakehouse Infrastructure Backbone
The REST Catalog specification is not merely an API standard — it is the architectural blueprint for the next generation of lakehouse infrastructure. By standardizing the catalog protocol, it enables:
Compute Engine Portability: Organizations can switch from Spark to Trino to Flink without changing their catalog infrastructure. The catalog implementation choice is completely decoupled from the compute engine choice.
Multi-Cloud Catalog Federation: A REST Catalog client can connect to multiple REST Catalog servers simultaneously (for different tables or namespaces), enabling queries that span tables in different cloud regions, different cloud providers, or different catalog service implementations — all through the same API protocol.
Vendor-Neutral Governance: Access control, audit logging, and data governance policies are enforced once, in the REST Catalog server, and applied uniformly regardless of which compute engine is accessing the data.
Conclusion
The Iceberg REST Catalog specification is the architectural lever that transforms Apache Iceberg from a table format into a complete, standards-based lakehouse management system. Its standardization of the catalog API eliminates the N×M connector proliferation problem, its credential vending mechanism enables table-level security enforcement at the storage layer, its compare-and-swap commit protocol guarantees ACID correctness for concurrent writers, and its multi-table transaction support enables cross-table atomicity that no previous open lakehouse standard has provided. As adoption of REST Catalog-compliant implementations (Polaris, Nessie, Glue, Snowflake Open Catalog) grows, the REST Catalog specification is rapidly becoming the universal protocol of the open data lakehouse — the common language that any engine, any catalog, and any storage layer can use to interoperate reliably and securely.
Visual Architecture