Rewrite Data Files
In Apache Iceberg, the abstract concept of “Compaction” is practically executed using a specific maintenance API called rewriteDataFiles.
Typically orchestrated via a compute engine like Apache Spark, this action is the primary mechanism data engineers use to optimize the physical layout of their Parquet files, ensuring the lakehouse remains highly performant even after millions of streaming micro-batch inserts.
When you execute rewriteDataFiles, you must configure a strategy that dictates how the engine should process the files.
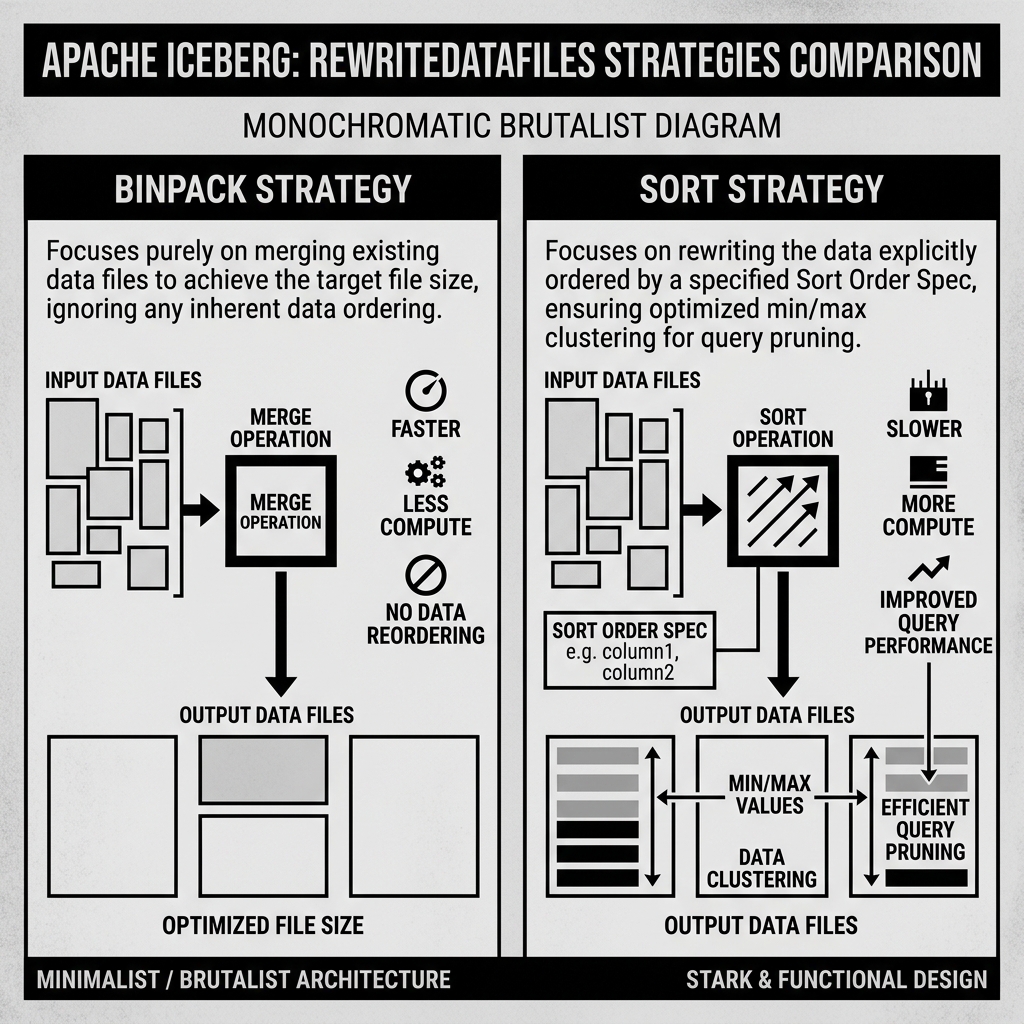
Binpack vs. Sort Strategies
There are two primary strategies for rewriting data files:
-
BINPACK: This is the default and fastest strategy. The Binpack strategy focuses entirely on the size of the files, completely ignoring the data inside them. It looks for files that are too small (e.g., 10MB) and packs them together until they reach the target file size (e.g., 512MB). Because it does not care about data ordering, it requires less CPU overhead and executes very quickly.
-
SORT: This strategy is much more computationally expensive but yields far better query performance. The Sort strategy physically reorders the rows within the Parquet files according to the table’s Sort Order Spec. By explicitly ordering the data, the Sort strategy tightens the min/max statistics stored in the Iceberg Manifests, allowing the query engine’s predicate pushdown logic to skip massive amounts of irrelevant data during future queries.
If your users heavily query the table using a specific column (like customer_id), using the SORT strategy on that column will drastically reduce query latency.
Diagram 1: Binpack vs Sort Strategy
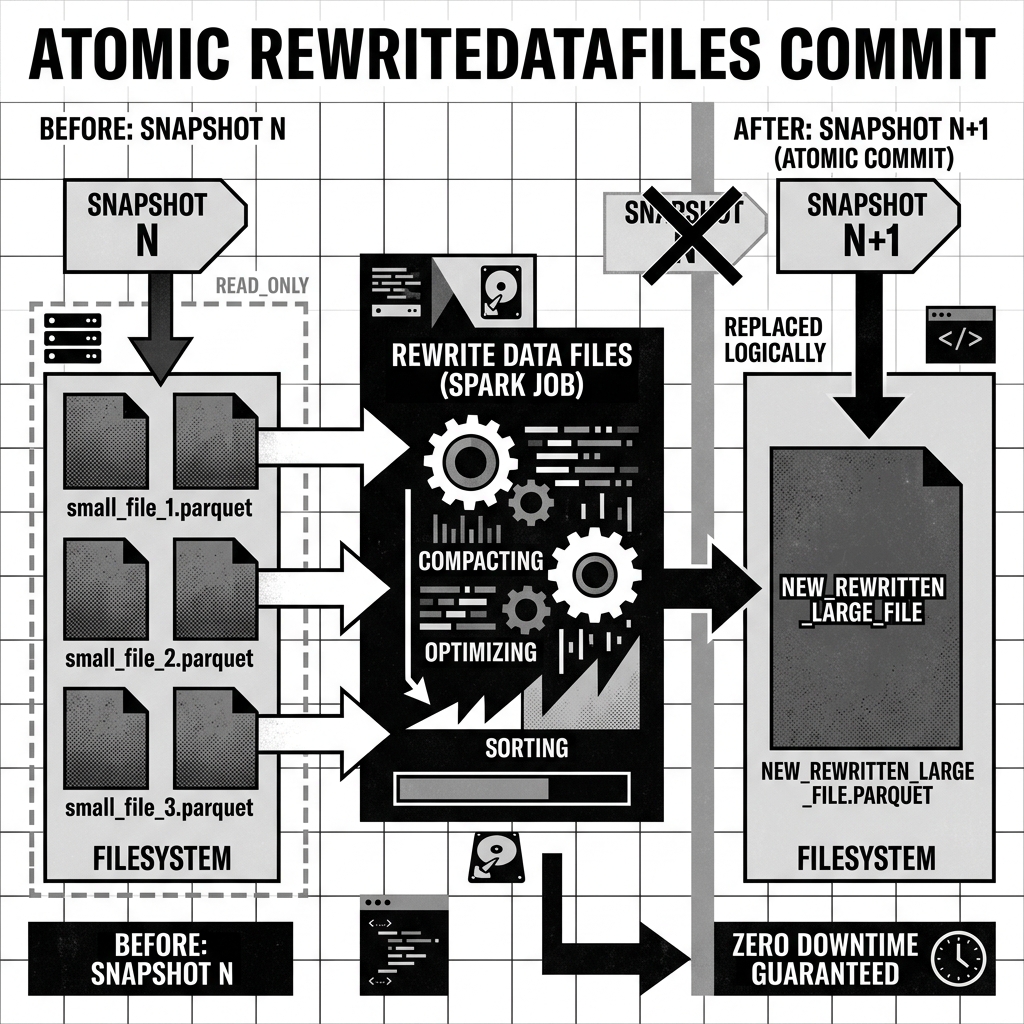
The Atomic Swap
A critical feature of the rewriteDataFiles action is its atomicity.
When the Spark job begins, it reads a batch of small Parquet files. It processes them in memory (using either Binpack or Sort) and writes a brand new, large Parquet file to object storage.
Once the large file is successfully written, Iceberg performs a single, atomic catalog commit. It creates Snapshot N+1. In this new snapshot, the metadata points exclusively to the new large file, and the old small files are logically removed from the active state.
Because this swap is atomic, there is zero downtime. If an analyst queries the table one millisecond before the commit, they read the old small files. If they query it one millisecond after, they read the new large file. At no point is the table unavailable, and at no point will a query return duplicated data.
Diagram 2: Atomic Commit of Rewritten Files