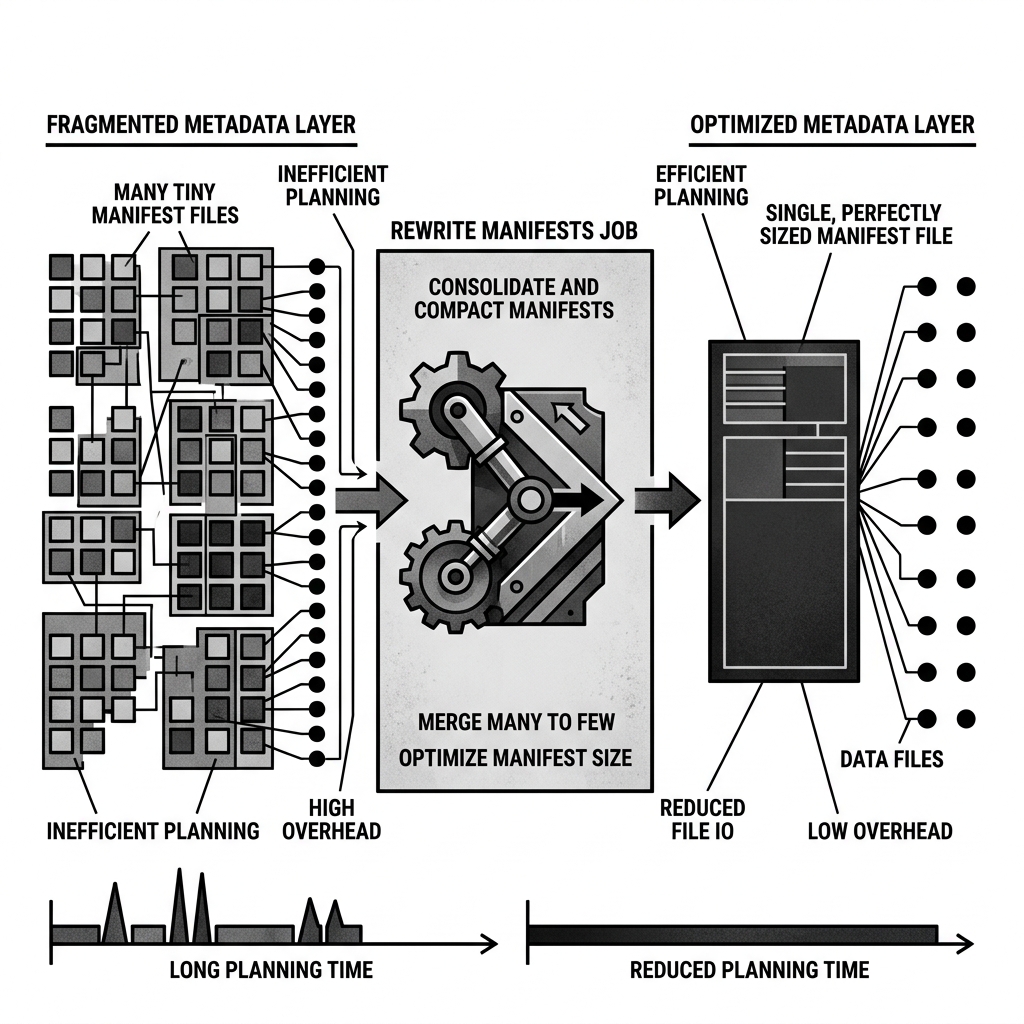
Rewrite Manifests
While rewriteDataFiles focuses on optimizing the physical Parquet data, it does not optimize the metadata layer.
In a high-throughput streaming environment, Iceberg creates a new Manifest File for every single commit. If a streaming job commits every 10 seconds, it will generate over 8,000 tiny Manifest Files per day.
When an analyst executes a query, the compute engine must download and read all 8,000 of those Manifest Files just to figure out which Parquet files to scan. This creates a severe bottleneck in the Query Planning phase. The query might take 5 seconds to run, but 4 seconds of that was spent just reading fragmented metadata.
The solution is the RewriteManifests API.
Compacting the Metadata
The rewriteManifests action is a maintenance job that specifically targets the metadata layer. It completely ignores the physical Parquet data files.
The job reads the thousands of tiny, highly fragmented Manifest Files, consolidates their internal tracking pointers into memory, and writes out a single, perfectly sized Manifest File (typically around 8MB).
By replacing 8,000 tiny files with one optimized file, the query planning time drops from seconds to milliseconds. The compute engine can instantly download the single Manifest, evaluate its statistics, and proceed directly to data execution.
Diagram 1: Fragmented vs. Optimized Metadata
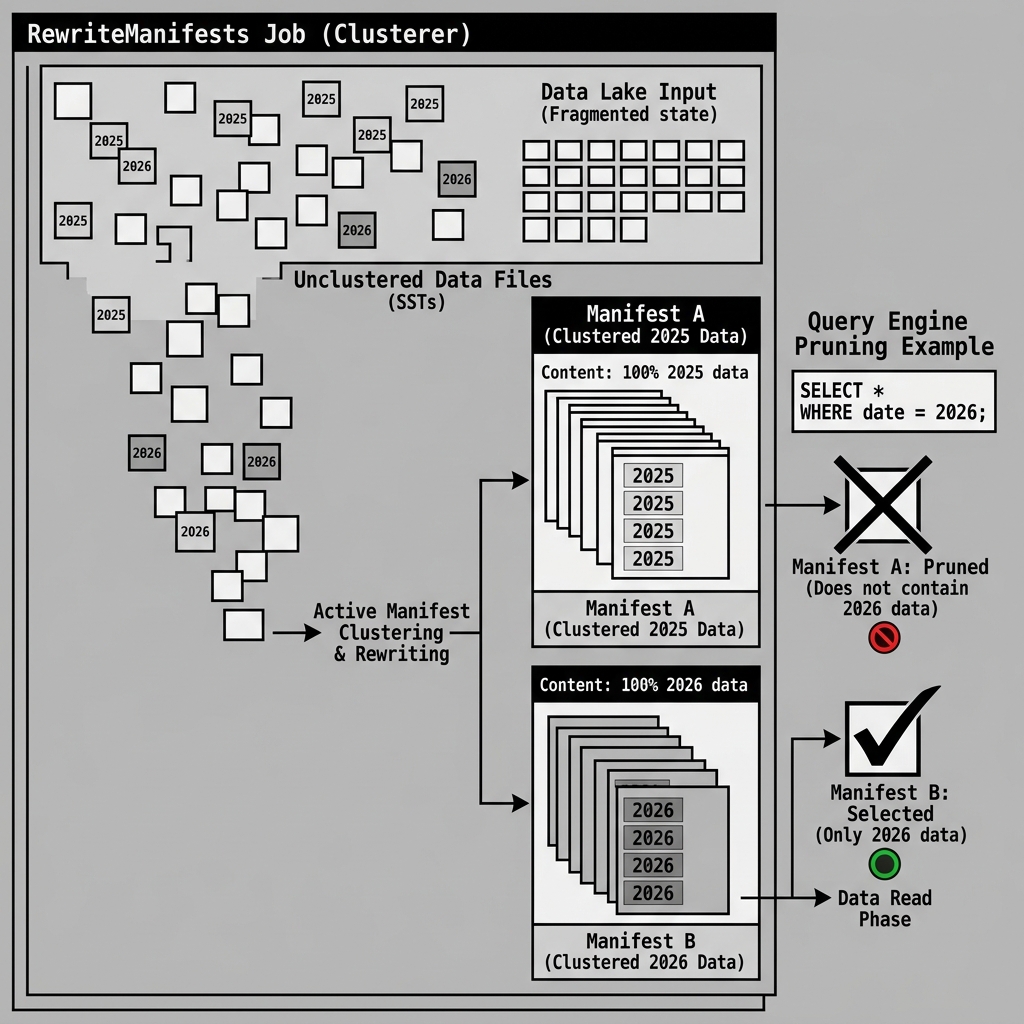
Manifest Clustering
Beyond simply reducing the number of files, rewriteManifests provides a powerful optimization technique known as Manifest Clustering.
Over time, data files belonging to different partitions (e.g., Year 2025 and Year 2026) might get tracked together inside the same fragmented Manifest Files. This means that if a query only asks for 2026 data, the engine is forced to read the Manifest and manually filter out the 2025 pointers.
When you execute rewriteManifests, Iceberg naturally clusters the data file pointers by partition. It will group all the pointers for the 2025 data files and write them into Manifest A. It will group all the pointers for the 2026 data files and write them into Manifest B.
Because the Manifest List tracks the min/max statistics for the Manifest Files themselves, the query engine can now look at the Manifest List and completely skip Manifest A, knowing it only contains 2025 data. By clustering the metadata, Iceberg unlocks massive efficiencies during predicate pushdown at the highest levels of the metadata tree.
Diagram 2: Manifest Clustering