Row-Oriented Formats
Row-oriented formats are data storage layouts where the data associated with a single record (a row) is stored contiguously on physical storage media. This is the traditional method of storing data, utilized by standard relational databases (like MySQL and PostgreSQL) and common text-based formats (like CSV and JSON). While row-oriented storage is highly efficient for specific operational workloads, it presents severe performance bottlenecks when used for large-scale analytics within a modern data lakehouse.
The Architecture of Row Storage
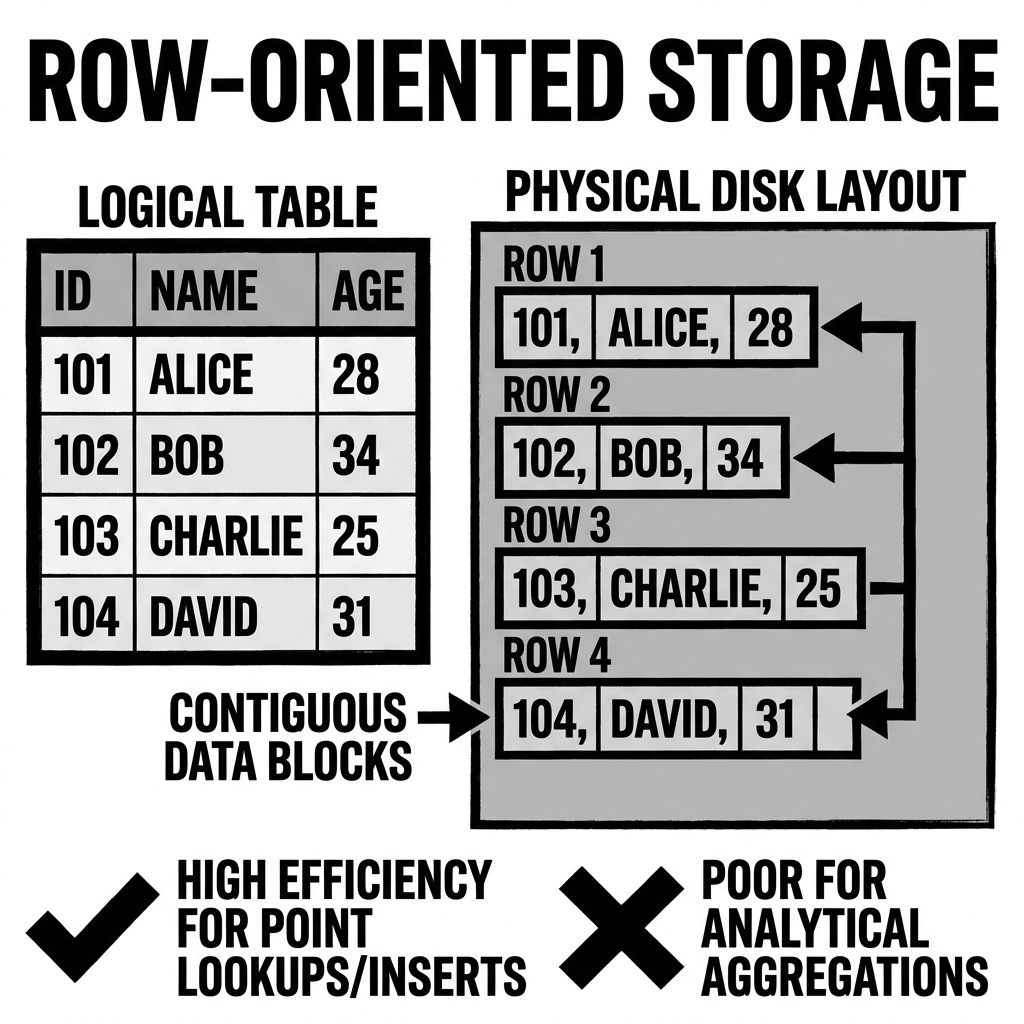
In a row-oriented format, if a database table consists of an ID, Name, Email, and RegistrationDate, the data for User 1 is written sequentially to the disk, immediately followed by the data for User 2.
Physically, the disk layout looks like this:
[1, 'Alice', 'alice@email.com', '2023-01-01'] [2, 'Bob', 'bob@email.com', '2023-01-02'] ...
This architecture is optimized for Online Transaction Processing (OLTP) workloads. OLTP systems—such as the backend database for an e-commerce website or a banking application—are characterized by thousands of concurrent users performing small, rapid operations: fetching a user’s profile, inserting a new order, or updating an account balance.
Row-oriented storage excels at these tasks because of disk locality. When an application requests SELECT * FROM users WHERE id = 1, the database engine locates the start of Row 1 and reads a single, contiguous block of data from the hard drive into memory. The disk head performs one seek operation to retrieve the entire, fully constructed record. Similarly, inserting a new user is incredibly fast; the database simply appends the new, contiguous row of data to the end of the file.
The Analytical Bottleneck
While perfect for point lookups and inserts, row-oriented storage fails spectacularly when subjected to Online Analytical Processing (OLAP) workloads.
Analytical queries rarely request a single, complete record. Instead, they typically perform mathematical aggregations over a massive number of rows, but only look at a small subset of the columns.
Consider the query: SELECT COUNT(id) FROM users WHERE RegistrationDate > '2023-01-01'.
To execute this query on a row-oriented file (like a massive CSV), the database engine must scan the entire file. It reads User 1’s ID, Name, and Email, discards them from memory, checks the RegistrationDate, and increments the count. It then repeats this for User 2, User 3, and millions of others.
Because the RegistrationDate values are physically separated by the other column data, the database is forced to read massive amounts of entirely irrelevant data (Names, Emails) from the slow physical disk just to access the dates. This wasted Input/Output (I/O) results in crippling performance delays. Furthermore, because adjacent data points on the disk are of heterogenous types (an integer, then a string, then a date), row-oriented data compresses very poorly compared to columnar data.
Row Formats in the Data Engineering Pipeline
Despite their analytical inefficiency, row-oriented formats still play a critical role in the broader data ecosystem, particularly during the ingestion phase.
Data often originates in row-oriented formats. Application logs are written as JSON objects. Relational databases export dumps as CSVs. Streaming systems like Apache Kafka often transport events as row-oriented Avro records.
In a traditional ETL (Extract, Transform, Load) pipeline, data engineers must construct systems that extract these row-oriented JSON or CSV files from source systems, process them, and quickly transform them into columnar formats (like Apache Parquet) before writing them to the data lakehouse.
Summary and Tradeoffs
Row-oriented formats are the backbone of transactional computing, sacrificing large-scale scanning speed for unparalleled efficiency in reading and writing single, complete records.
The primary tradeoff is architectural mismatch. Using row-oriented formats like CSV or JSON as the foundational storage layer for a data lakehouse will result in skyrocketing compute costs and agonizingly slow query times, as analytical engines are forced to read exabytes of unnecessary data. Understanding this distinction is the core reason why modern data architectures mandate the conversion of operational row data into optimized columnar formats for downstream analytics.
Visual Architecture