Rule-Based Optimizer (RBO)
A Rule-Based Optimizer (RBO) is a critical component of a database’s query planning phase. Unlike a Cost-Based Optimizer (CBO) that uses mathematical models and data statistics to estimate the cheapest execution path, an RBO relies on a static, predefined set of logical rules or heuristics to transform and simplify a SQL query. While pure RBO systems have largely been superseded by CBOs for physical execution planning, the RBO remains an indispensable first step in modern lakehouse query engines, responsible for cleaning, simplifying, and logically rewriting queries before they are handed off for cost evaluation.
Core Definition
When a user submits a complex SQL query containing multiple subqueries, convoluted WHERE clauses, and redundant expressions, executing that query exactly as written is highly inefficient.
A Rule-Based Optimizer acts as a strict editor. It traverses the Abstract Syntax Tree (AST)—the internal representation of the parsed SQL query—and applies a series of rigid, algorithmic rules to transform the tree into a logically equivalent, but structurally simpler, form.
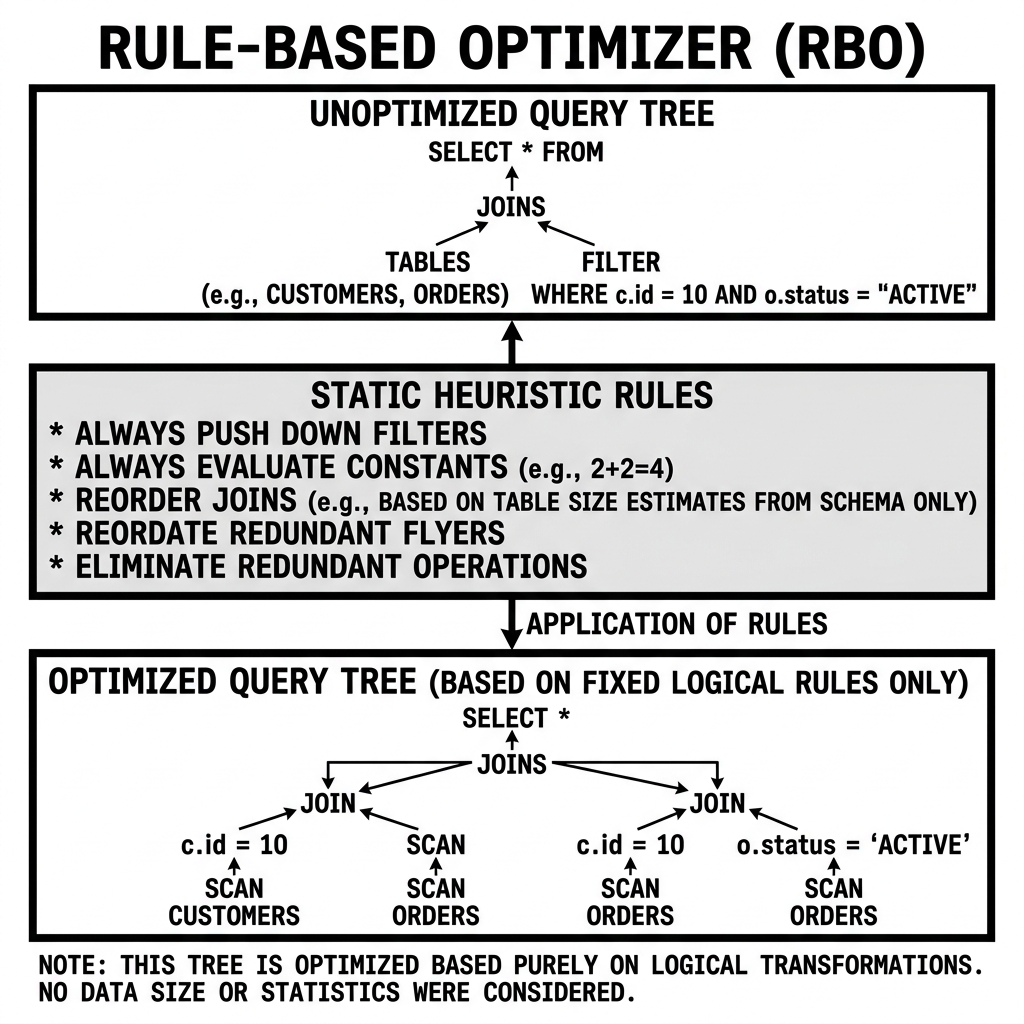
The defining characteristic of an RBO is that it is “blind” to the actual data. It does not know if a table has ten rows or ten billion rows. It does not look at metadata statistics or histograms. It applies its transformations strictly based on the relational algebra and logical structure of the query itself. If a rule says “always push filters down the tree,” the RBO will apply that rule universally, under the assumption that filtering data early is always a logically sound strategy.
Common RBO Transformations
Modern query engines like Apache Spark (using the Catalyst Optimizer) and Trino rely on an extensive library of RBO rules to clean up queries. Common transformations include:
Predicate Pushdown: This is arguably the most famous rule. If a query joins two tables and then applies a filter (SELECT * FROM A JOIN B ON A.id = B.id WHERE A.status = 'active'), the RBO will rewrite the query tree to apply the filter before the join (SELECT * FROM (SELECT * FROM A WHERE status = 'active') JOIN B). Filtering data before performing an expensive join is universally beneficial, regardless of data size.
Constant Folding: If a user writes an expression like WHERE age > 10 + 5, the RBO will evaluate the mathematical constant at compile time and rewrite the query as WHERE age > 15. This prevents the CPU from having to calculate 10 + 5 millions of times during row-by-row execution.
Column Pruning: If a user queries SELECT name FROM users, the RBO identifies that out of the 50 columns in the users table, only name is required. It injects rules into the execution plan to ensure the storage reader only reads the name column, aggressively dropping unreferenced data early in the process.
Subquery Decorrelation: In complex SQL, analysts often write correlated subqueries (where the inner query depends on a value from the outer query). Correlated subqueries effectively force a database to execute a nested loop, running the inner query repeatedly for every single row of the outer query. The RBO utilizes complex algebraic rules to “unnest” or decorrelate these queries, transforming them into standard JOIN operations, which distributed compute engines can execute much more efficiently.
RBO vs. CBO in Modern Engines
In the early days of relational databases, engines like Oracle originally relied exclusively on Rule-Based Optimizers to dictate the entire execution plan. For example, a rule might dictate that if an index exists on a column, the engine must always use the index. However, as data grew, this rigid approach failed. If a query filters on a gender column, using a B-Tree index is actually slower than doing a full table scan because the index provides almost no selectivity. The RBO didn’t know this because it didn’t look at the data statistics.
Today, pure RBO systems are extinct for physical planning. Instead, modern data lakehouse engines (like Spark, Trino, and Snowflake) use a hybrid approach.
The query optimization pipeline occurs in two distinct phases:
- The Logical Phase (RBO): The engine first passes the query through the Rule-Based Optimizer. The RBO applies its heuristics (constant folding, predicate pushdown, subquery unnesting) to generate a highly optimized Logical Plan.
- The Physical Phase (CBO): The engine takes this optimized Logical Plan and hands it to the Cost-Based Optimizer. The CBO looks at the actual table statistics (file sizes, row counts from Iceberg metadata) and generates multiple Physical Plans (e.g., choosing between a Hash Join or a Broadcast Join). The CBO calculates the cost of each and selects the winner.
Summary and Tradeoffs
The Rule-Based Optimizer is the unsung hero of query performance. By systematically applying relational algebra rules to eliminate redundant logic and push operations as close to the data source as possible, the RBO dramatically simplifies the workload before the heavy lifting even begins.
The primary tradeoff with an RBO is its inflexibility. Because it does not consider the physical reality of the data, an RBO cannot make complex execution decisions. It cannot decide if it is cheaper to stream data across the network or write it to a temporary disk. It cannot decide which join algorithm to use based on the size of the tables.
Therefore, an RBO is a necessary but insufficient tool for modern distributed data processing. It relies entirely on the Cost-Based Optimizer downstream to handle the physical realities of executing queries over the massive, decoupled storage architecture of the open data lakehouse.
Visual Architecture