Schema Evolution
Data structures are rarely static. As applications grow, business requirements change, necessitating the addition, deletion, or renaming of columns in analytical tables.
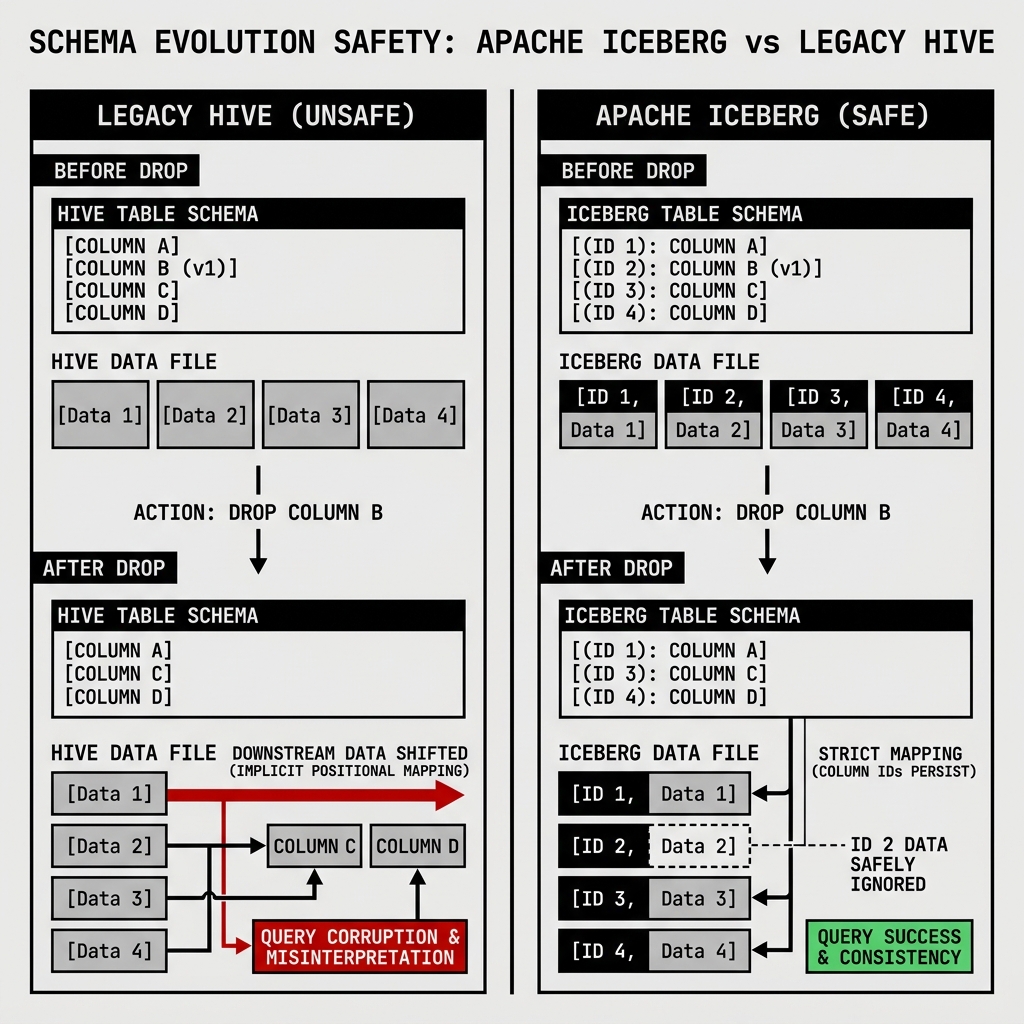
In legacy data lake architectures like Apache Hive, modifying a schema was a notoriously dangerous operation. Hive tracked columns by their physical order or name. If a data engineer dropped a column in the middle of a table, all subsequent columns would logically shift left. This caused downstream query engines to read the wrong data types, silently corrupting analytical reports. To safely evolve a schema in Hive, teams usually had to completely rewrite the entire table.
Apache Iceberg eliminates this danger entirely through Schema Evolution.
The Core Operations
Because Iceberg uses strict Column ID tracking (as defined in the Schema Spec), all schema changes are purely metadata operations. They execute instantaneously, regardless of whether the table contains 10 megabytes or 10 petabytes of data.
Iceberg guarantees the safety of four core schema evolution operations:
- Add: You can append a new column or add a new nested field to a struct. Iceberg simply assigns a new, unique Column ID. When querying older data files that lack this ID, Iceberg automatically returns
NULL. - Drop: You can remove an existing column. Iceberg removes the Column ID from the active schema. The physical data remains in the old Parquet files, but the query engine safely ignores it because the ID is no longer mapped.
- Rename: You can change the name of a column (e.g.,
user_idtoaccount_id). The underlying Column ID remains exactly the same, ensuring that the engine still reads the correct physical data. - Update (Widen): You can widen the type of a column to accommodate larger values (e.g., changing an
INTto aBIGINT, or aFLOATto aDOUBLE). Iceberg handles the implicit casting when reading older files. Note that narrowing types (e.g.,BIGINTtoINT) is not allowed, as it could result in data loss.
Diagram 1: Core Schema Evolution Operations

Guaranteeing Safety and Consistency
The primary benefit of Iceberg’s approach to Schema Evolution is absolute consistency.
If an engineer executes ALTER TABLE users DROP COLUMN phone_number, and then immediately executes ALTER TABLE users ADD COLUMN phone_number, Iceberg does not simply reuse the old physical data.
The dropped column had ID: 5. The newly added column will be assigned ID: 6. Even though the column name is the same, Iceberg knows they are mathematically distinct entities. This completely prevents “zombie data” scenarios where a query for a newly added column accidentally returns deleted data from historical files.
Diagram 2: Iceberg vs. Legacy Safety