Silver Layer
In the Medallion Architecture, data quality is not enforced at the point of ingestion. It is enforced at a dedicated processing stage that sits between the raw landing zone and the business-ready analytics layer. This processing stage is the Silver Layer. If the Bronze Layer is where all data arrives without judgment, the Silver Layer is where the judgment happens.
The Silver Layer transforms raw, messy, untrusted Bronze data into clean, validated, standardized, and enriched datasets that can be treated as a reliable foundation for all downstream analytical work. It is the enterprise’s single source of truth, the layer that multiple business teams, machine learning pipelines, and Gold-layer processes all read from as their authoritative data source.
The Silver Layer requires the most careful design work of any tier in the Medallion Architecture. Getting Bronze right is mostly about moving data quickly and reliably. Getting Gold right is mostly about applying business logic. Getting Silver right requires balancing data quality rigor with operational flexibility, and the decisions made at Silver directly determine the reliability of everything built on top of it.
What the Silver Layer Does
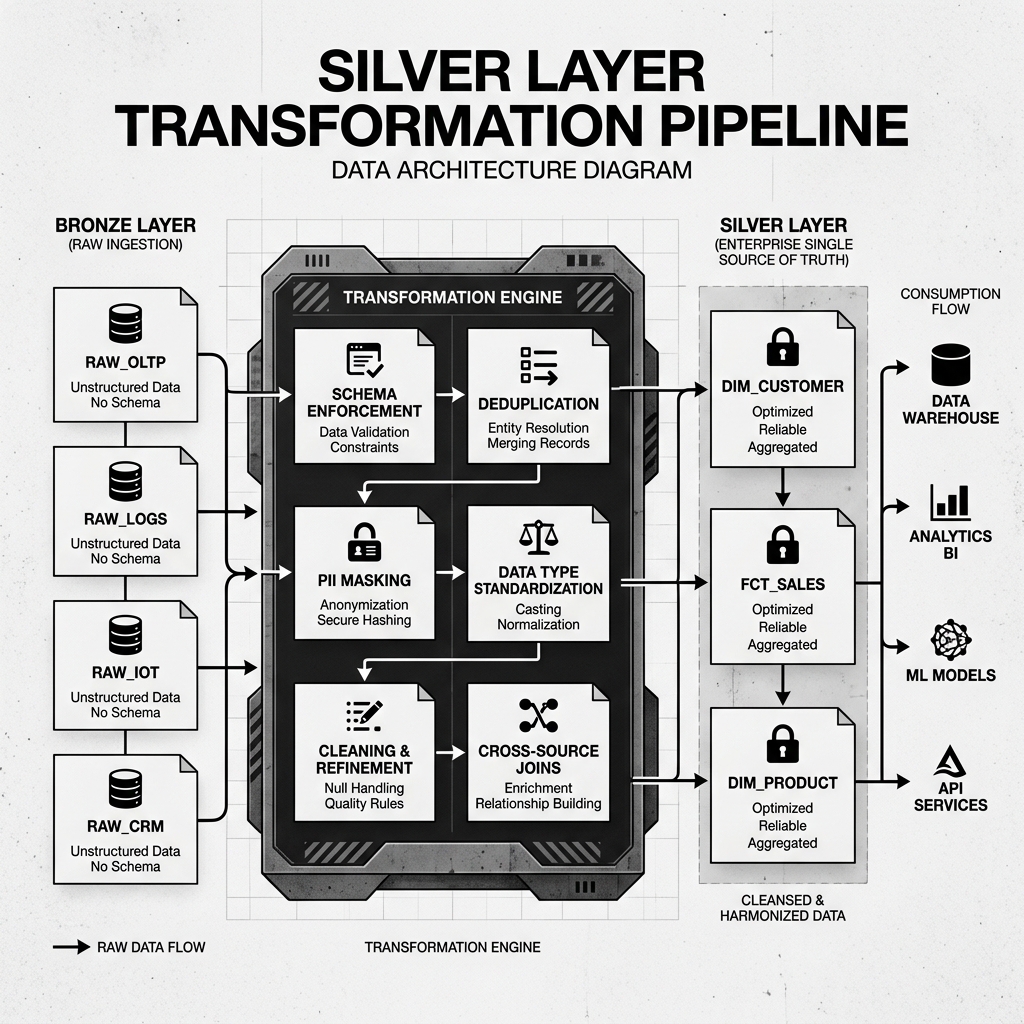
The Silver Layer is responsible for several distinct categories of data processing, all applied as part of a coordinated transformation pipeline that reads incrementally from Bronze.
Schema Enforcement is the first line of defense. Bronze data arrives in whatever schema the source system dictated. Silver pipelines apply explicit, versioned schemas to every input record. A record that claims to have a customer_id of "ABC-NULL" instead of a valid UUID fails schema validation and is routed to a quarantine table. A record missing a required event_timestamp field is similarly rejected. This enforcement ensures that every record in Silver conforms to a known, documented structure.
Data Cleansing resolves the quality issues that schema enforcement passes through. A phone number in the format (555) 123-4567 is standardized to +15551234567. A country code of "usa" is normalized to "US". Trailing whitespace is trimmed from string fields. Numeric columns that arrived as strings in the raw source are cast to their proper types. None of this logic is as simple as it sounds at scale: edge cases multiply rapidly, and the Silver pipeline must handle them explicitly and predictably.
Deduplication removes redundant records that entered the Bronze layer because of network retries, pipeline failures, or source system bugs. Silver pipelines implement deduplication logic based on natural keys, such as (order_id, event_type), ensuring that each unique business event appears exactly once in the Silver layer even if it was ingested multiple times.
PII Masking and Tokenization protects sensitive personal data before it becomes accessible to broader audiences. In the Silver layer, full names might be replaced with tokenized identifiers. Social security numbers are hashed with a one-way function. Email addresses are partially masked. Only specially authorized data engineering jobs retain access to the full un-masked Bronze records when legally required.
Cross-Source Enrichment is where the Silver layer adds value beyond simple cleaning. Raw order records from the Bronze orders table are joined with customer profile records from the Bronze customers table to produce a unified Silver customer_orders table that contains both the transactional details and the customer context in a single, pre-joined structure. This eliminates the need for every downstream consumer to replicate the same join logic independently.
Diagram 1: Silver Layer Transformation Pipeline
Incremental Processing
Silver-layer transformation pipelines almost always run in incremental mode rather than processing the entire Bronze table on every run. The most common approach leverages the Iceberg table format’s snapshot model.
When the Silver pipeline last ran, it recorded the snapshot ID of the Bronze table it processed. On the next run, it asks the Bronze table for all records added since that snapshot ID (the incremental delta). It processes only those new records, applies all the cleaning, validation, and enrichment logic, and writes the results to the Silver table using an ACID merge operation.
This incremental approach allows Silver pipelines to process petabytes of historical Bronze data efficiently, because each run only touches the fraction of data that has changed since the last run. It also means Silver tables are always current: as soon as a batch of Bronze data is committed, the next Silver pipeline run will incorporate it.
Diagram 2: Data Quality Gates
The Quarantine Pattern
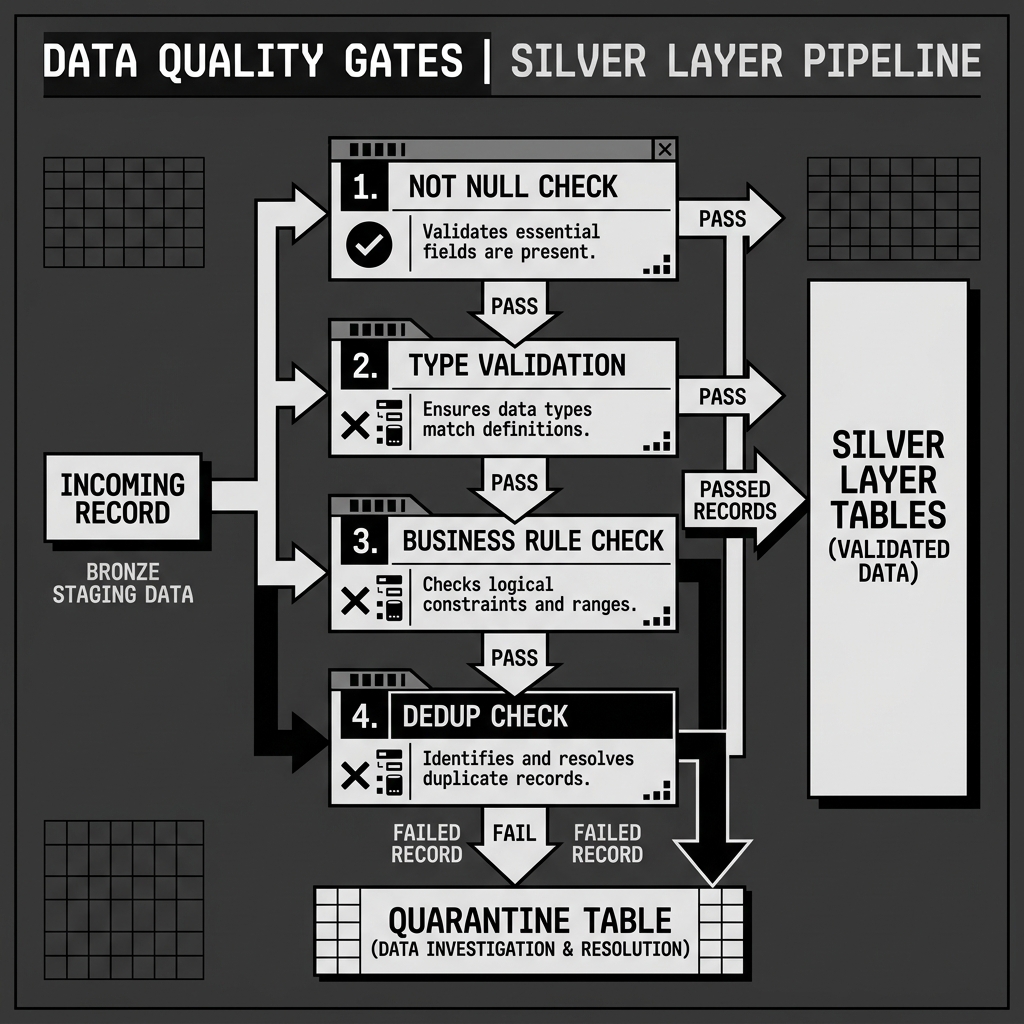
Every Silver pipeline should include a quarantine mechanism for records that fail validation. Rather than silently dropping bad records or halting the pipeline on the first error, a robust Silver pipeline writes failing records to a dedicated quarantine table with metadata explaining precisely which validation rule they violated and what the raw record looked like.
The quarantine table enables data engineers to investigate data quality issues systematically. By monitoring the quarantine table, they can identify patterns of failures, such as a specific source system that repeatedly sends malformed timestamps, trace those failures back to their origin, and work with the source system owners to fix the problem upstream. Without quarantine, bad records simply disappear from the pipeline, and the data quality issue may not be noticed until it surfaces as an incorrect business metric months later.
The Silver layer, when designed and maintained rigorously, becomes the most trusted dataset in the entire organization. Business teams stop emailing each other spreadsheets and instead query the Silver layer directly, confident that the data they receive is clean, consistent, and accurate. This reduction in data distrust is one of the most significant organizational benefits of the Medallion Architecture.