Snapshot Isolation
When multiple systems interact with the same data simultaneously, chaos can easily ensue. If an analyst runs a query that takes five minutes to execute, and a data pipeline deletes half the records in the table during minute three, what happens to the analyst’s query? Does it return half old data and half new data? Does it crash?
In legacy data lakes built on implicit directory structures (like Apache Hive), these “phantom reads” and “dirty reads” were a constant plague. Modern data lakehouses solve this entirely by implementing a transactional guarantee known as Snapshot Isolation.
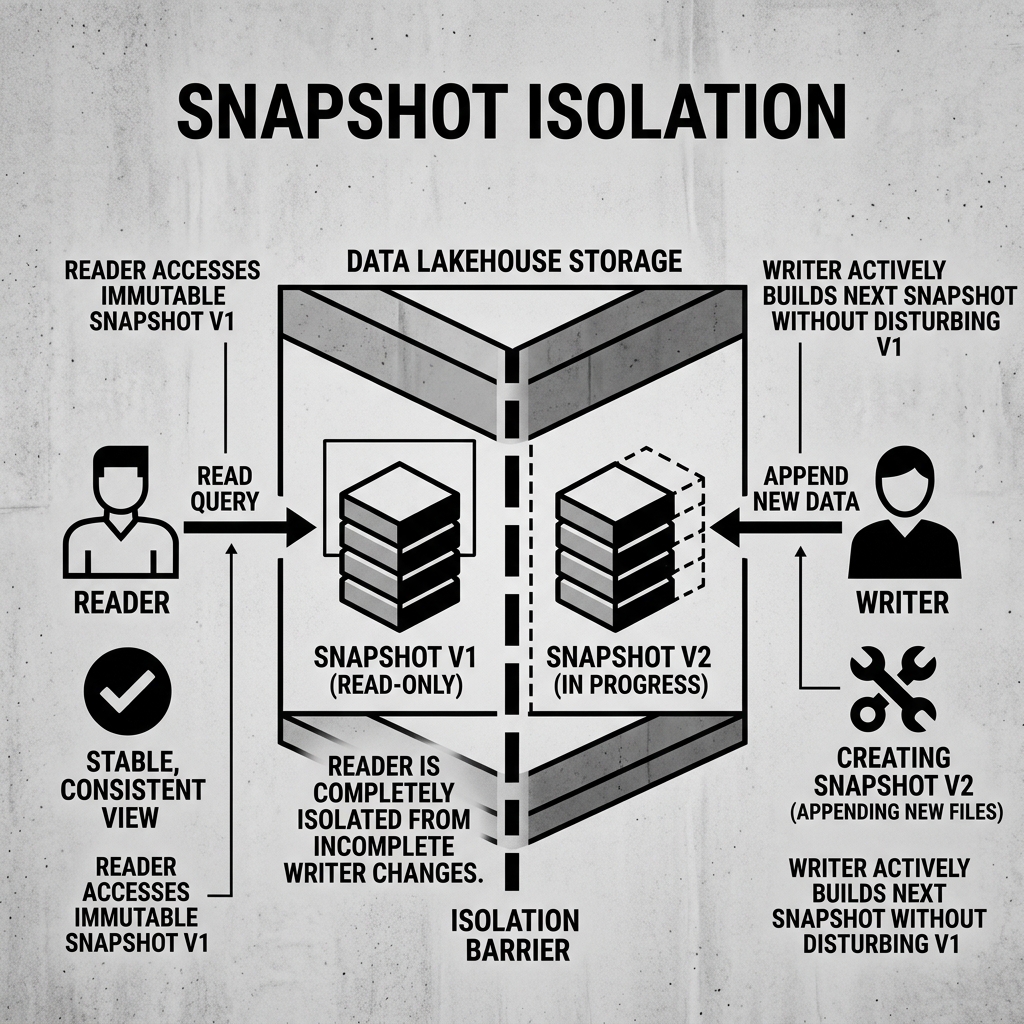
Snapshot Isolation guarantees that all reads made in a transaction will see a consistent snapshot of the database, exactly as it existed at the moment the transaction started. The reader is completely isolated from any concurrent changes made by other transactions.
Protecting the Readers
In a table format like Apache Iceberg, every committed state of the table is represented by an immutable Snapshot.
When an analyst executes a SELECT query, the query engine asks the catalog for the current active Snapshot (let’s call it Snapshot V1). The engine then begins reading the data files referenced by V1.
While the analyst’s query is running, a massive Apache Spark ETL job wakes up and begins appending millions of new rows to the table. The Spark job writes new Parquet data files and builds a new metadata tree for Snapshot V2. Once finished, Spark atomically updates the catalog pointer to make V2 the new active Snapshot.
Under Snapshot Isolation, the analyst’s query is entirely unaffected by the Spark job. The analyst’s query remains locked onto the metadata tree for Snapshot V1. It will only read the Parquet files that existed when V1 was created. It will not see any of the new data files added by V2, nor will it crash if V2 logically deleted some of the old files (because Iceberg does not physically delete files until they expire).
Readers never block writers, and writers never block readers.
Diagram 1: Protecting Readers via Isolation
Protecting the Writers
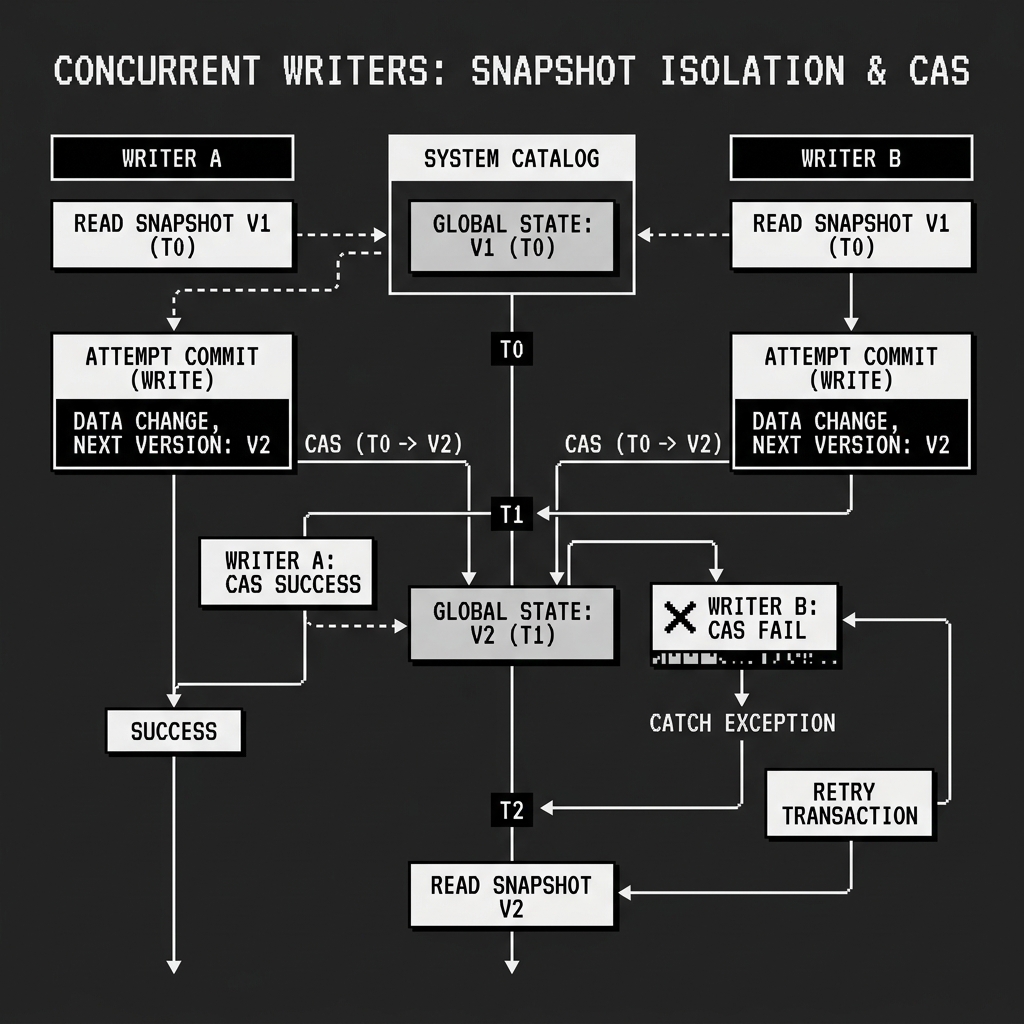
Snapshot Isolation also manages the chaos of concurrent writers. What happens if two different Spark jobs try to write to the table at the exact same time?
Both Job A and Job B start their transactions by reading the current state: Snapshot V1. They both process their data, write their new physical Parquet files, and construct their new metadata trees in isolation.
Job A finishes slightly faster. It issues a Compare-and-Swap (CAS) request to the catalog: “Update the pointer to my new metadata file, assuming the current pointer is still V1.” Because the pointer is still V1, the catalog accepts the atomic swap. Job A successfully commits Snapshot V2.
A fraction of a second later, Job B attempts to commit. It issues its CAS request: “Update the pointer to my new metadata file, assuming the current pointer is still V1.” The catalog rejects the request because the pointer is now V2.
Job B has failed its initial commit. Under Snapshot Isolation, Job B must now catch the exception, download the metadata for the new V2 Snapshot, reconcile its intended changes against the new state (ensuring there are no logical conflicts), and attempt to commit again as Snapshot V3.
Diagram 2: Handling Concurrent Writers
The Lakehouse Difference
Snapshot Isolation is a standard feature in proprietary relational databases like PostgreSQL or Oracle. The breakthrough of the data lakehouse is bringing this enterprise-grade transactional guarantee to massive scale on distributed cloud object storage.
By leveraging immutable files, explicit metadata tracking, and atomic catalog operations, formats like Apache Iceberg provide strict Snapshot Isolation without the need for a central, monolithic database server, enabling true decoupled compute and storage.