Snowflake
Snowflake is a fully managed cloud data platform that fundamentally revolutionized the data warehousing industry. Launched out of stealth in 2014, Snowflake was built entirely from scratch specifically for the cloud. It was the first platform to successfully commercialize the complete physical separation of compute and storage. While historically operating as a closed, proprietary data warehouse, Snowflake has steadily evolved to embrace the open data lakehouse paradigm, allowing organizations to leverage its powerful query engine against open table formats like Apache Iceberg.
Core Definition
Prior to Snowflake, data warehousing was dominated by on-premises appliances like Teradata, or early cloud adaptations like Amazon Redshift. These legacy systems utilized a shared-nothing architecture where compute and storage were tightly coupled on the same physical hardware. If an organization needed more storage space for historical data, they were forced to purchase more compute nodes, even if their query volume had not increased. This led to massive inefficiencies and skyrocketing costs.
Snowflake completely dismantled this paradigm. The founders built a system where the storage layer (backed by cheap, infinite object storage like Amazon S3) was physically and logically separated from the compute layer (backed by ephemeral virtual machines).
This architectural breakthrough allowed storage and compute to scale independently. An organization could store petabytes of data for pennies per gigabyte while spinning up massive compute clusters on demand only when complex queries needed to run. Once the queries finished, the compute clusters could be instantly shut down, meaning the customer only paid for the exact seconds of compute they consumed.
Furthermore, because storage was centralized and decoupled, Snowflake introduced the concept of Virtual Warehouses. Multiple independent compute clusters (Virtual Warehouses) could simultaneously read the exact same underlying data without competing for resources. The marketing team could run massive aggregations on a “Large” warehouse while the executive dashboard ran instantly on a “Small” warehouse, with zero resource contention between them.
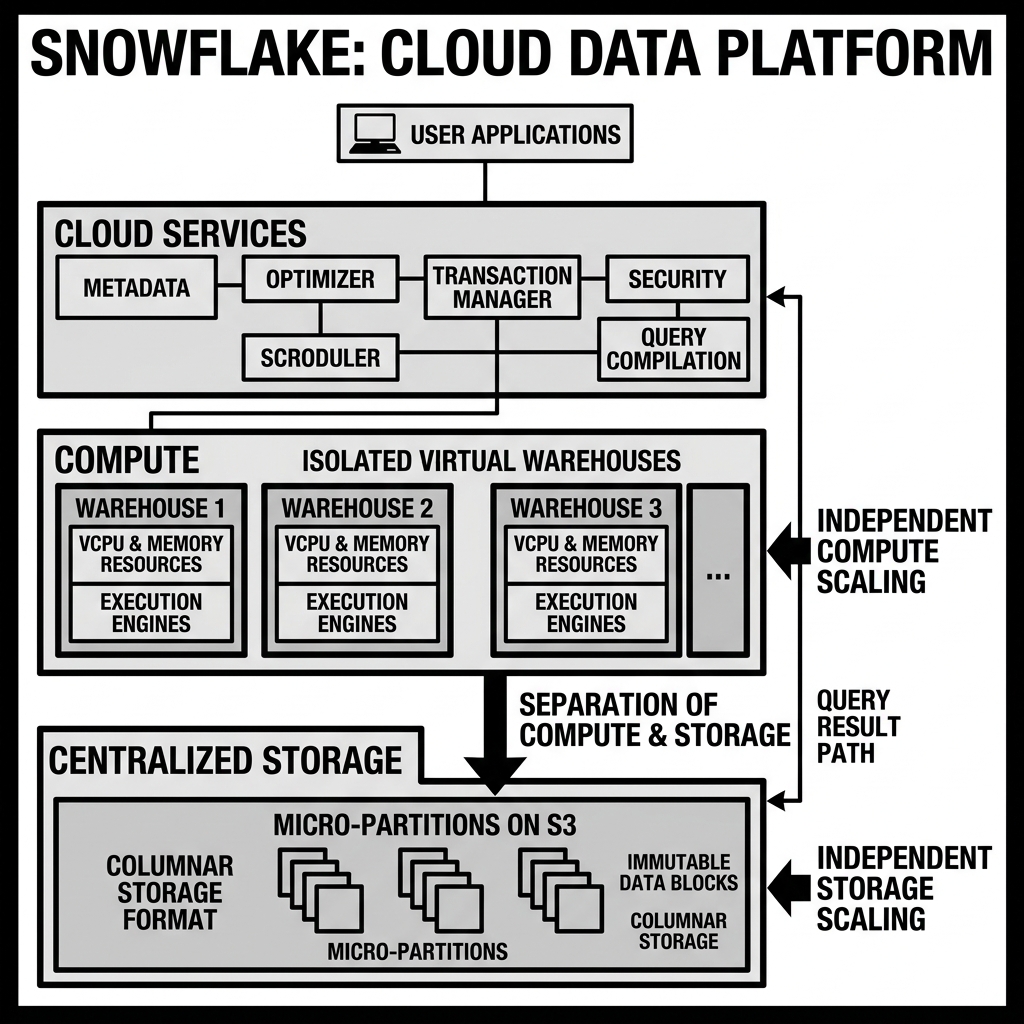
Architecture and Components
Snowflake’s architecture is typically described as a multi-cluster, shared-data architecture. It consists of three distinct layers: the Storage Layer, the Compute Layer, and the Cloud Services Layer.
The Storage Layer is the foundation. When data is loaded into Snowflake, it is automatically reorganized into an optimized, compressed, columnar format (often referred to as micro-partitions). Snowflake manages all aspects of how this data is stored, including file size, compression, metadata tracking, and encryption. The user never directly interacts with these raw files; they are abstracted away entirely.
The Compute Layer consists of Virtual Warehouses. These are massive parallel processing (MPP) compute clusters provisioned from the cloud provider (AWS, Azure, or GCP). Virtual Warehouses execute the data processing tasks required for queries. Because the data lives in the shared storage layer, Virtual Warehouses are stateless. They can be resized dynamically (from X-Small to 6X-Large) in milliseconds to accelerate a query, and they utilize local SSD caching to speed up subsequent reads of the same data.
The Cloud Services Layer is the “brain” of Snowflake. It coordinates all activities across the platform. This fully managed layer handles user authentication, session management, query parsing and optimization, infrastructure management, and metadata tracking. Crucially, the metadata stored in this layer is what allows Snowflake to perform advanced features like zero-copy cloning, where a user can instantly clone a multi-terabyte database for testing without physically duplicating the data.
Snowflake and the Open Data Lakehouse
For years, Snowflake operated as a highly successful “walled garden.” To get Snowflake’s performance, users had to ingest their data into Snowflake’s proprietary storage format. This locked the data into the Snowflake ecosystem, making it difficult and expensive to process that data with other tools (like Apache Spark or Python machine learning frameworks).
As the industry shifted toward the open data lakehouse model—where data is stored in open formats like Apache Iceberg on vendor-neutral object storage—Snowflake was forced to adapt. They introduced Snowflake Iceberg Tables.
Iceberg Tables in Snowflake bridge the gap between Snowflake’s powerful engine and the open lakehouse. Users can create tables in Snowflake that are backed entirely by Apache Iceberg metadata and Parquet data files sitting in the user’s own AWS S3 or Azure Data Lake storage buckets.
When a user queries an Iceberg table, the Snowflake Cloud Services layer reads the Iceberg metadata to prune partitions, and the Virtual Warehouses fetch the Parquet files directly from the customer’s object storage. Snowflake applies its local caching mechanisms to these external files, delivering query performance that is highly competitive with its internal proprietary storage.
This integration is a massive paradigm shift. Organizations can now use Snowflake purely as a high-performance compute engine over their open data lake. They can use Snowflake to write data to Iceberg, and then turn around and read that exact same Iceberg data using Apache Spark or Trino, achieving true interoperability and avoiding vendor lock-in.
Advanced Capabilities and Snowpark
Beyond basic SQL querying, Snowflake has aggressively expanded its capabilities to serve data engineering and data science workloads. The cornerstone of this effort is Snowpark.
Snowpark is a developer framework that allows engineers and data scientists to write code in languages like Python, Java, and Scala, and execute that code directly within the Snowflake engine. Instead of extracting data out of Snowflake to run a Python machine learning model (which is slow and insecure), Snowpark pushes the Python code down to the data.
Snowpark provides a DataFrame API that feels highly similar to Pandas or PySpark. When a developer executes a Snowpark DataFrame operation, Snowflake translates it into optimized SQL or executes it within secure, sandboxed Python runtimes directly on the Virtual Warehouses. This allows organizations to consolidate their data engineering pipelines and machine learning inference workloads entirely within the Snowflake platform, simplifying their architecture.
Summary and Tradeoffs
Snowflake is arguably the most polished and widely adopted cloud data platform in the world. Its fully managed nature, near-zero maintenance overhead, and brilliant separation of compute and storage have set the standard for modern data architectures. By embracing Apache Iceberg, Snowflake has successfully positioned itself as a premier compute engine within the open data lakehouse ecosystem.
The primary tradeoff with Snowflake is cost control. Because Snowflake abstracts away so much complexity and makes it incredibly easy to spin up massive compute resources, organizations frequently suffer from “bill shock.” If virtual warehouses are not properly configured to auto-suspend, or if poorly written queries are repeatedly executed on over-sized clusters, costs can spiral out of control.
Furthermore, despite its embrace of Iceberg, the gravitational pull of the Snowflake ecosystem remains strong. Features like Snowpark and its proprietary sharing mechanisms encourage organizations to move more and more logic into the platform. While the data itself may now reside in open formats, organizations must remain vigilant to ensure their compute logic and pipeline orchestration do not become inextricably locked into a single vendor’s proprietary framework.
Visual Architecture