Sort Order Spec
While the Partition Spec determines how data is logically divided into coarse-grained directories (like by year or month), the Sort Order Spec determines how the data is physically organized inside those specific data files.
In Apache Iceberg, the Sort Order Spec is a configuration stored in the table’s metadata that instructs the compute engine (like Spark or Flink) on how to sort the rows before writing them to the Parquet data files.
Why does sorting matter? It is entirely about maximizing the effectiveness of Predicate Pushdown.
Tightening Min/Max Statistics
When a query engine evaluates a Parquet file, it looks at the min and max statistics stored in the metadata.
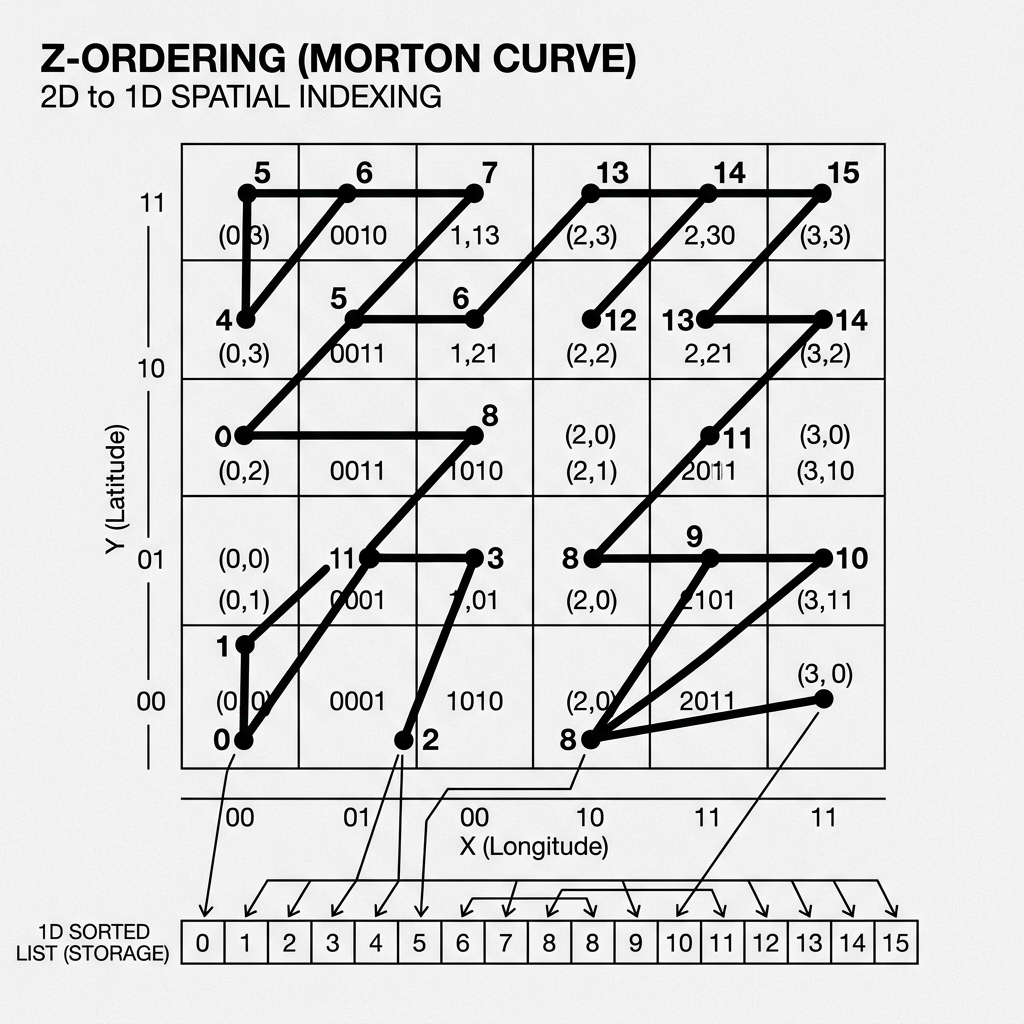
Imagine a partition containing a billion user records. If the data is written randomly (unsorted), a single Parquet file might contain user_id 1 and user_id 999,999. The metadata for that file will state: min: 1, max: 999,999. If you query WHERE user_id = 500, the engine sees that 500 falls within that massive range, so it is forced to download and scan the entire file, even if the record isn’t actually there.
If you apply a Sort Order Spec of user_id ASC, the compute engine will sort the data before writing it. Now, File 1 might contain IDs 1 through 10,000. File 2 contains 10,001 through 20,000.
If you query WHERE user_id = 500, the engine looks at File 2’s metadata (min: 10001, max: 20000) and immediately skips it. By keeping the min/max boundaries extremely tight, sorting allows query engines to skip massive amounts of data during the planning phase.
Diagram 1: Sort Order Efficiency
Z-Ordering for Multi-Dimensional Data
Sorting works perfectly if you only ever query your data by one column. But what if your users frequently query by both customer_id and transaction_date?
If you sort purely by customer_id, the dates will be completely scattered, destroying the effectiveness of date-based predicate pushdown. If you sort primarily by customer_id and secondarily by transaction_date (hierarchical sorting), the primary sort column gets great performance, but the secondary column still suffers.
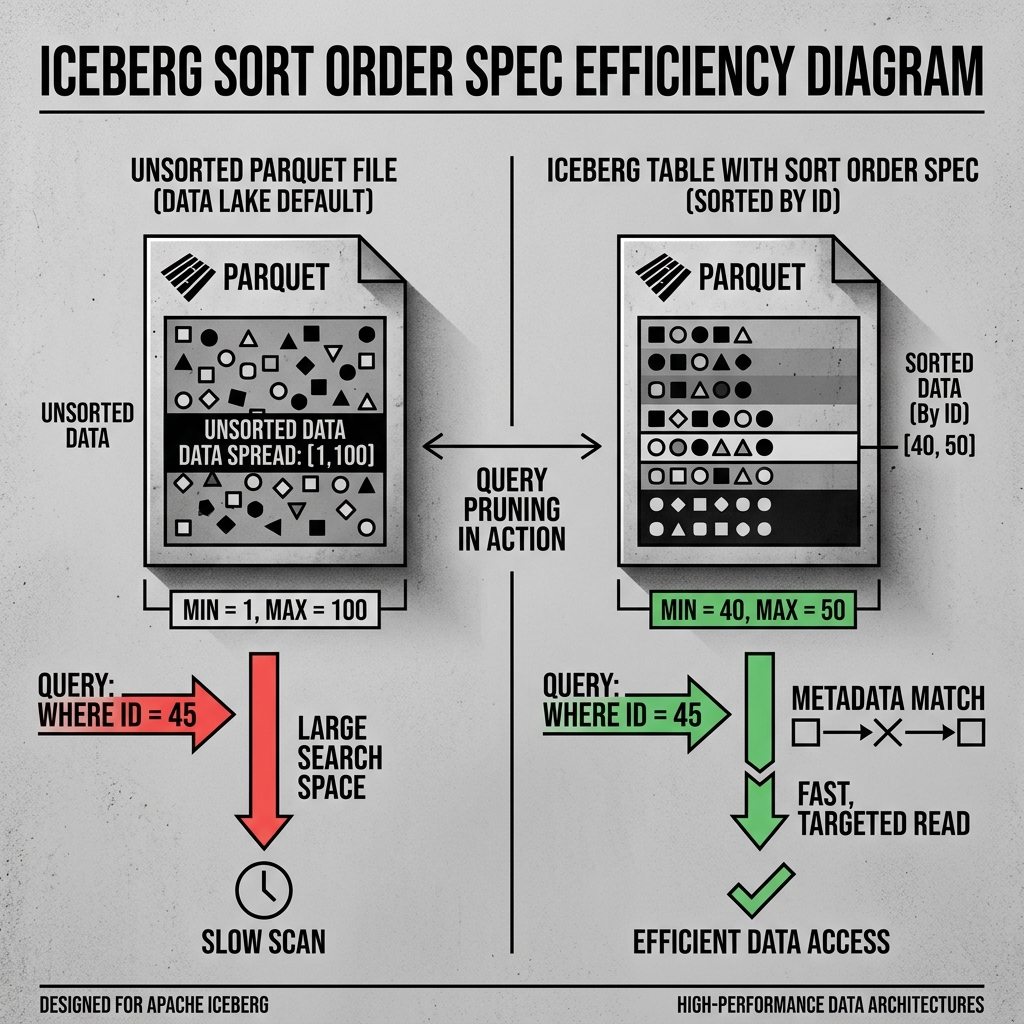
To solve this, advanced data lakehouses utilize Z-Ordering (also known as a Morton curve). Z-Ordering is a technique that interleaves the binary representation of multiple columns to map multi-dimensional data into a single-dimensional list.
Instead of prioritizing one column over another, Z-Ordering clusters data so that records with similar customer_ids and similar transaction_dates are physically stored close to each other in the same Parquet files. This allows the query engine to achieve excellent pruning performance regardless of which column the analyst chooses to filter on.
Diagram 2: Z-Ordering