SQL Dialects
SQL (Structured Query Language) is the lingua franca of data analytics. However, despite being an ANSI standard since 1986, the implementation of SQL across different database systems and compute engines is highly fragmented. These variations are known as SQL Dialects. In the context of the open data lakehouse—where a single dataset might be queried by Apache Spark, Trino, Snowflake, and Dremio—understanding and managing the nuances of different SQL dialects is a critical challenge for data engineers.
Core Definition
The ANSI SQL standard defines the core syntax and semantics for interacting with relational databases, covering fundamental operations like SELECT, INSERT, UPDATE, DELETE, JOIN, and basic aggregations like SUM and COUNT.
However, the standard leaves significant room for interpretation and does not cover advanced analytical functions, vendor-specific performance optimizations, or modern data types like complex JSON or array structures. As database vendors and open-source communities built their engines to handle specific workloads, they extended the SQL standard with custom functions and syntax.
This resulted in the creation of distinct SQL dialects. For example, extracting the year from a timestamp is achieved using EXTRACT(YEAR FROM date_col) in standard SQL, but might be written as YEAR(date_col) in Spark SQL or DATE_PART('year', date_col) in PostgreSQL. While these differences appear minor, they completely break automated data pipelines and dashboarding tools when migrating between compute engines.
Common SQL Dialects in the Lakehouse
In the modern data lakehouse ecosystem, several dominant SQL dialects interact frequently:
Spark SQL: Apache Spark provides a highly permissive dialect. It borrows heavily from HiveQL (the dialect used by Apache Hive) to ensure backward compatibility with early Hadoop ecosystems. Spark SQL is known for its extensive library of built-in functions for complex data types (arrays, maps, structs) and its integration with the broader Spark DataFrame API.
Trino/Presto SQL: Trino and Presto are famously strict regarding ANSI SQL compliance. They mandate explicit type casting and adhere closely to the standard syntax. This strictness ensures predictable behavior but often requires developers migrating from more permissive systems (like MySQL or Spark) to rewrite their queries to satisfy Trino’s rigid parser.
Snowflake SQL: Snowflake provides a robust, proprietary dialect. While highly ANSI compliant, it includes extensive proprietary extensions to handle semi-structured data (like querying JSON using dot notation, e.g., column_name:json_key::string), time travel (AT (TIMESTAMP => ...)), and specialized window functions.
ClickHouse SQL: ClickHouse utilizes a highly customized dialect optimized for its columnar storage and vectorized execution. It features unique syntax for array manipulations, higher-order functions (like arrayFilter or arrayMap), and specialized GLOBAL JOIN semantics dictated by its distributed architecture.
The Challenge of Interoperability
The fragmentation of SQL dialects creates massive friction in the open data lakehouse. The fundamental promise of the lakehouse is that data is stored in a vendor-neutral format (like Apache Iceberg) and can be accessed by any compute engine. However, if the business logic (the SQL queries, views, and dbt models) is written in a specific proprietary dialect, the organization is still experiencing vendor lock-in at the compute layer.
If an organization decides to switch their primary ingestion engine from Databricks (Spark SQL) to Snowflake, they do not need to move their Iceberg data. However, they must manually rewrite hundreds or thousands of SQL pipelines and materialized view definitions to translate from Spark SQL’s permissive syntax to Snowflake’s dialect.
This challenge is particularly acute when defining views. A view is essentially a saved SQL query. If a view is created using Trino SQL, a Spark engine attempting to read that view will fail because it cannot parse the Trino-specific syntax stored in the catalog.
Translation and Abstraction Layers
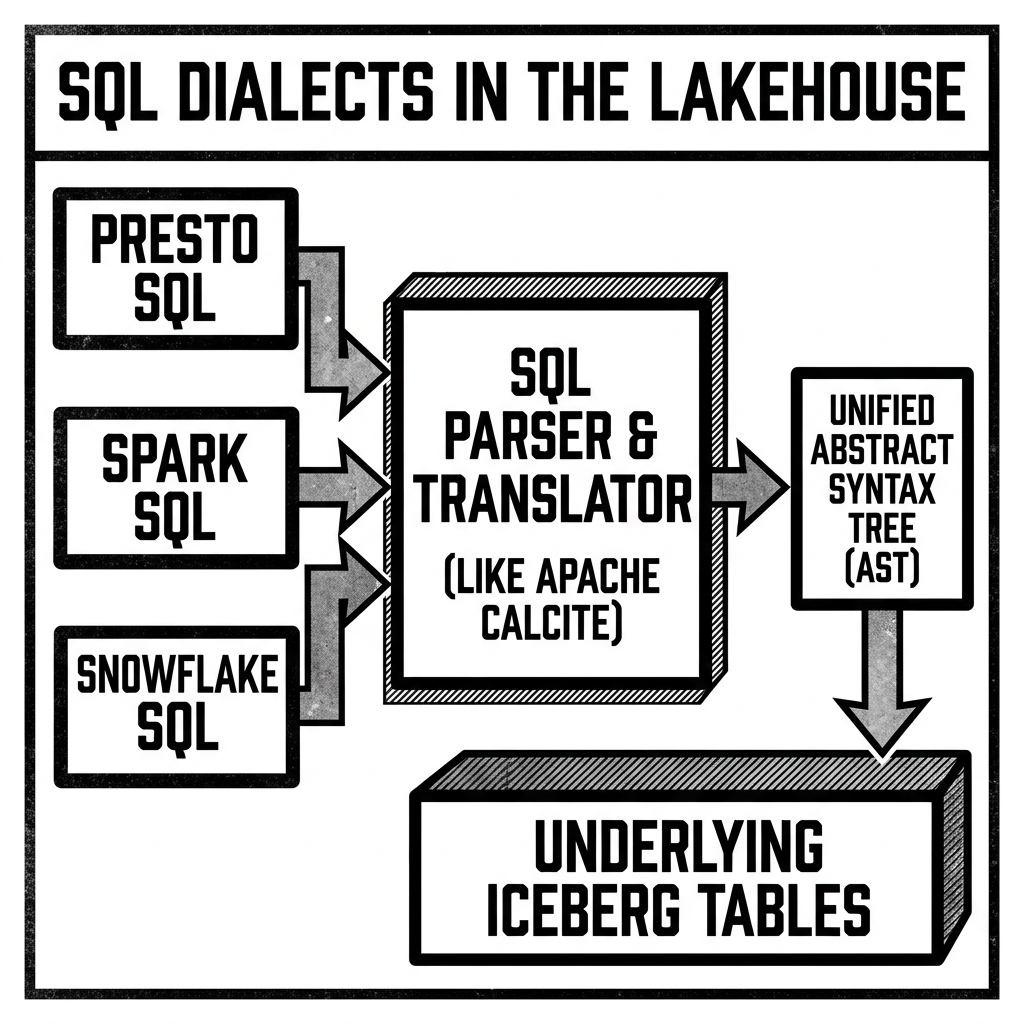
To solve the dialect interoperability problem, the industry is heavily investing in SQL parsing and translation layers.
Tools like Apache Calcite act as foundational frameworks for building databases. Calcite includes a highly sophisticated SQL parser and validator that can understand multiple dialects and translate them into a unified relational algebra (Abstract Syntax Tree or AST). Many modern engines (like Apache Flink) use Calcite internally.
Open-source tools like SQLGlot have emerged specifically to translate SQL between different dialects. Data engineers can write pipelines that automatically transpile a query written in BigQuery SQL into its exact equivalent in Trino SQL or Spark SQL before execution. This transpilation logic is becoming increasingly integrated into orchestration tools like dbt and semantic layers like Cube or Cube.js.
Furthermore, unified catalog standards are evolving to address the view problem. The Iceberg community is developing standard representations for views that store the SQL logic alongside dialect-specific representations, allowing the catalog to serve the correct syntax to the engine requesting the view.
Summary and Tradeoffs
SQL dialects represent the historical fragmentation of the database industry. While the underlying data in a lakehouse has successfully been standardized through open table formats, the compute layer remains highly diverse and dialect-specific.
The tradeoff for data teams is balancing engine-specific performance features against portability. Using a proprietary SQL extension (like Snowflake’s specific JSON parsing syntax) might make a query significantly faster and easier to write, but it irrevocably ties that pipeline to Snowflake. Writing strictly ANSI-compliant SQL ensures maximum portability across engines but often results in highly verbose code and sacrifices access to an engine’s most powerful, specialized analytical functions.
As the lakehouse matures, the adoption of intelligent semantic layers and automated SQL transpilers will increasingly abstract these dialects away, allowing users to write logic once and execute it anywhere.
Visual Architecture