StarRocks
StarRocks is an open-source, next-generation Massive Parallel Processing (MPP) database designed for blazing-fast, real-time analytics. Originally built to serve high-concurrency, low-latency user-facing analytical applications, StarRocks has rapidly evolved to become a powerhouse engine for querying the open data lakehouse. By combining a fully vectorized execution engine with a Cost-Based Optimizer (CBO) and advanced materialized view capabilities, StarRocks allows organizations to achieve sub-second query performance directly on data lakes without the need for complex data pipelines or external caching layers.
Core Definition
StarRocks was founded in 2020 by a team of engineers seeking to address the limitations of existing analytical databases. Traditional data warehouses often struggled with real-time data ingestion, while early MPP engines like Apache Impala or Presto lacked the ability to support thousands of concurrent queries with sub-second latency. StarRocks was built from the ground up in C++ to solve these specific challenges.
The engine is characterized by three core pillars: vectorized execution, an intelligent Cost-Based Optimizer, and a unified architecture. Vectorized execution means that StarRocks processes data in batches (vectors) using SIMD (Single Instruction, Multiple Data) instructions on modern CPUs, drastically reducing CPU overhead and maximizing memory bandwidth. The CBO automatically determines the most efficient execution plan for complex, multi-table joins, eliminating the need for manual SQL tuning.
Crucially, StarRocks operates as both an internal database and an external query engine. In its internal mode, data is ingested into StarRocks’ own highly optimized, columnar storage format. This provides the absolute lowest latency for high-frequency queries. However, in its external mode, StarRocks can query data directly where it lives on the data lakehouse (in formats like Apache Iceberg, Delta Lake, or Apache Hudi) without importing the data. This dual capability allows organizations to use a single engine for both sub-second operational analytics and massive-scale exploratory queries.
Architecture and Components
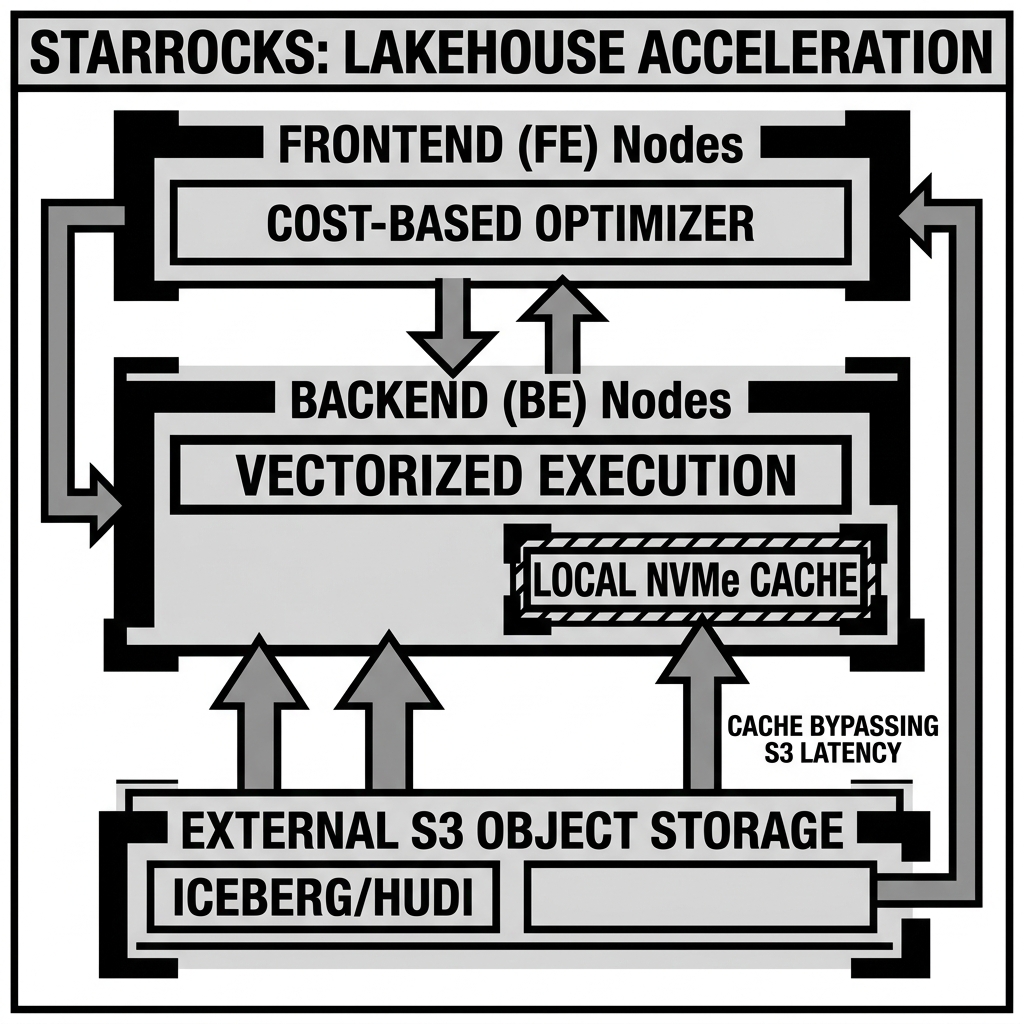
The architecture of StarRocks is highly simplified compared to many distributed data systems. It consists of only two types of nodes: Frontend (FE) nodes and Backend (BE) nodes. It does not rely on external dependencies like Apache ZooKeeper or Hadoop Distributed File System (HDFS).
The Frontend (FE) nodes are responsible for metadata management, cluster management, client connection handling, and query planning. When a client submits a SQL query, the FE parses the query, analyzes it, and leverages the Cost-Based Optimizer to generate an optimized distributed execution plan. The FE nodes also handle high availability; multiple FE nodes can be deployed, with one acting as the leader and the others as followers, ensuring no single point of failure.
The Backend (BE) nodes are responsible for both data storage (in internal mode) and query execution. When the FE generates an execution plan, it dispatches the query fragments to the relevant BE nodes. The BE nodes execute the vectorized computations in memory and stream the results back. If the query targets internal StarRocks tables, the BE reads from its local columnar storage. If the query targets an external data lake, the BE nodes act purely as compute instances, pulling the Parquet or ORC files directly from object storage like Amazon S3.
This unified, dependency-free architecture drastically simplifies deployment, operation, and scaling. Adding compute capacity to a StarRocks cluster is simply a matter of adding more BE nodes, which the FE immediately recognizes and begins utilizing.
Integration with the Data Lakehouse
StarRocks is increasingly being adopted as the high-performance presentation layer for the modern open data lakehouse. By utilizing the StarRocks external catalog feature, users can map entire databases from Apache Iceberg, Delta Lake, Apache Hive, or relational databases directly into StarRocks.
When querying an Apache Iceberg table, StarRocks leverages the Iceberg metadata to perform aggressive partition pruning and file skipping. However, StarRocks introduces a massive performance advantage through its Local Cache feature. When a BE node reads a Parquet file from Amazon S3, it can cache that file’s data locally on NVMe SSDs or in memory. Subsequent queries targeting the same data will read directly from the local cache, completely bypassing the network overhead and latency of object storage. This caching mechanism allows queries on external data lakes to achieve performance nearly identical to querying internal StarRocks tables.
Furthermore, StarRocks offers an incredibly powerful feature: Asynchronous Materialized Views. Materialized views in StarRocks are not just for internal tables; they can be built on top of external data lake tables. For example, a user can define a materialized view in StarRocks that pre-aggregates sales data from an external Iceberg table on S3. StarRocks will automatically and asynchronously keep this view updated. When a user queries the underlying Iceberg table, the StarRocks optimizer can transparently rewrite the query to hit the much faster, pre-aggregated materialized view instead, delivering instantaneous results.
Real-Time Analytics and High Concurrency
While many engines claim to support real-time analytics, StarRocks excels at high-concurrency, user-facing applications. These are applications where hundreds or thousands of users (like merchants checking their live sales dashboards) are hitting the database simultaneously, and every query must return in under a second.
To achieve this, StarRocks supports high-throughput, low-latency data ingestion. Data can be streamed directly into StarRocks from Apache Kafka or Apache Flink via specialized routines. StarRocks supports the Primary Key model in its internal storage, allowing for continuous, real-time UPSERT and DELETE operations without suffering the read-penalty typically associated with Merge-on-Read architectures.
During query execution, StarRocks’ pipeline execution engine maximizes CPU utilization by breaking query plans into independent pipelines that run concurrently across all available cores. This architecture prevents a single heavy query from monopolizing cluster resources, ensuring that thousands of small, concurrent dashboard queries can execute quickly and consistently.
Summary and Tradeoffs
StarRocks is rapidly redefining the performance expectations for analytical databases. By combining a native C++ vectorized engine, intelligent local caching, and powerful materialized views over external tables, StarRocks bridges the gap between the cheap, scalable storage of the data lakehouse and the sub-second latency required by modern applications.
The primary tradeoff with StarRocks is the complexity of managing a stateful cluster if you choose to utilize its internal storage. While querying external data lakes is stateless and relatively simple, ingesting data directly into StarRocks requires careful management of internal partitions, buckets, and memory limits to avoid performance bottlenecks. Furthermore, while its external query capabilities are incredibly fast, it is primarily optimized for read-heavy analytics, not for massive, long-running batch ETL transformations where a fault-tolerant engine like Apache Spark would be more appropriate.
Despite these nuances, StarRocks provides an unparalleled solution for the “last mile” of analytics. Organizations are increasingly adopting a two-tier architecture: using Spark or Flink to process and write data to Apache Iceberg on S3, and deploying StarRocks as the high-performance query layer to serve that Iceberg data directly to thousands of concurrent users at blazing speeds.
Visual Architecture