Storage Layer
In the architecture of a modern data lakehouse, the Storage Layer is the foundational bedrock upon which everything else is built. Unlike traditional relational databases where storage is an opaque, proprietary black box tightly integrated with the query engine, the lakehouse storage layer is deliberately transparent, decoupled, and built entirely on open standards.
This decoupling is what makes the lakehouse possible. By separating the storage of data from the compute engines that process it, organizations achieve independent scalability. If you need to store petabytes of historical logs that are rarely queried, you simply pay for more cheap storage without having to buy expensive compute nodes. If you need to run a massive end-of-month financial aggregation, you spin up a massive compute cluster for three hours to read the storage, and then shut the cluster down when the job is done.
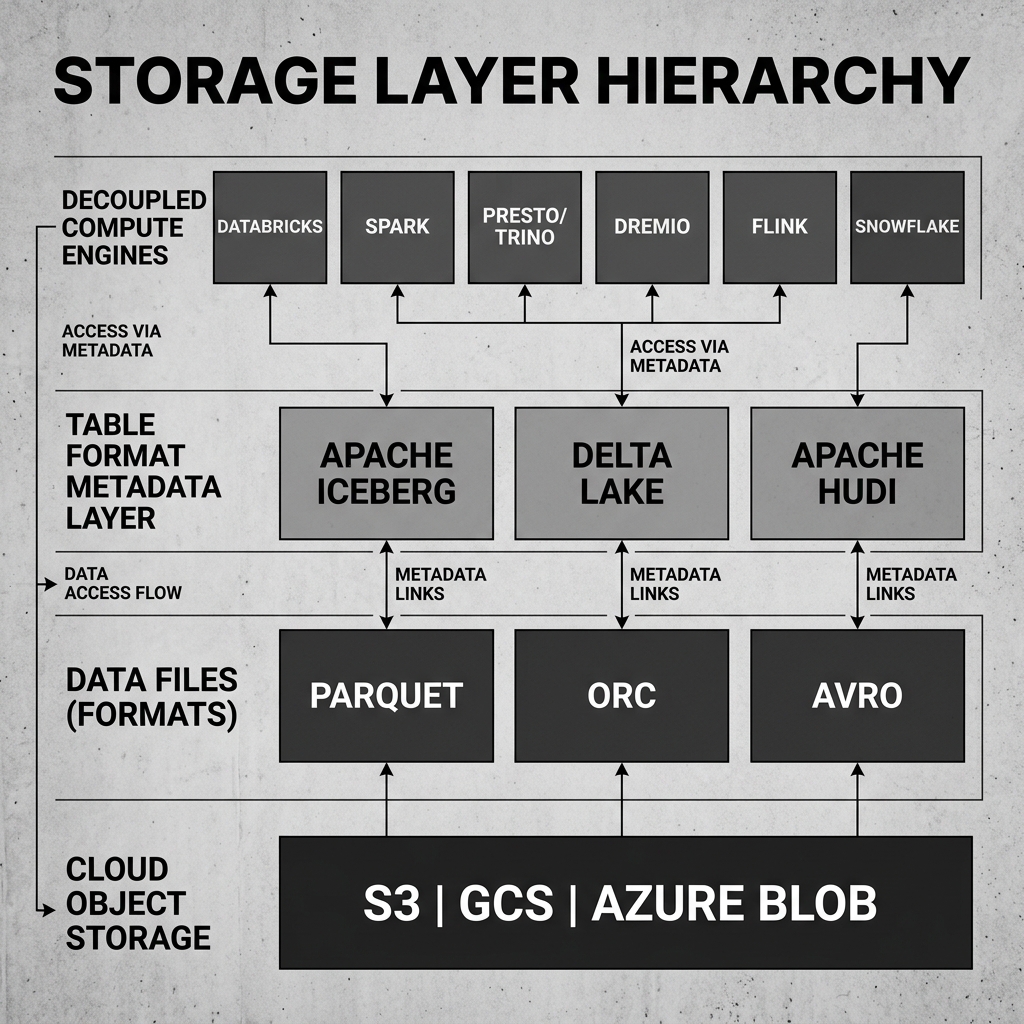
The Storage Layer itself is not a single technology. It is a hierarchical stack of three distinct components: the physical object storage, the data file formats, and the table format metadata. Understanding how these three components interact is essential for understanding lakehouse architecture.
1. Cloud Object Storage (The Physical Layer)
At the very bottom of the stack is the physical storage medium. In almost all modern data lakehouses, this is Cloud Object Storage, such as Amazon S3, Google Cloud Storage (GCS), or Azure Blob Storage.
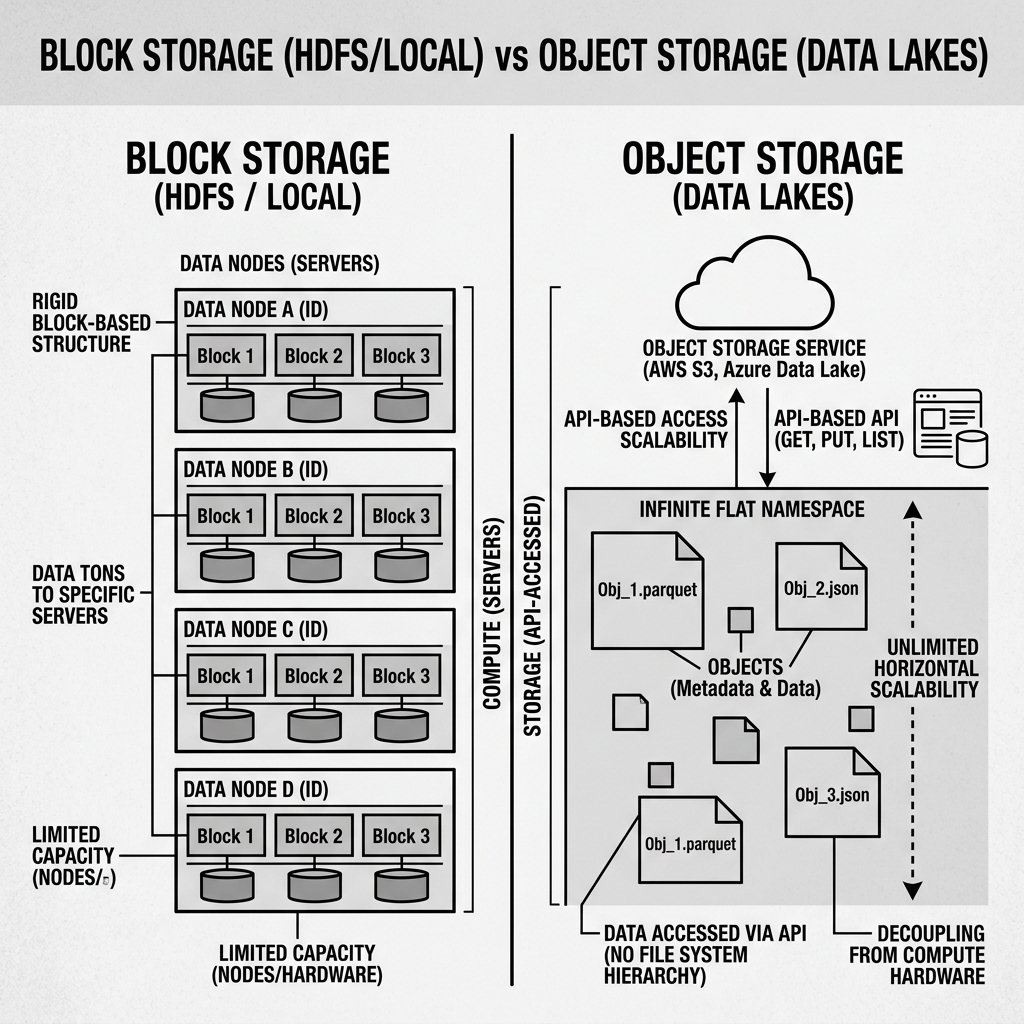
Object storage differs fundamentally from the block storage used by traditional file systems or the HDFS (Hadoop Distributed File System) used by early data lakes. In block storage, data is divided into fixed-size blocks and tied to specific physical disks on specific servers. Scaling requires adding more servers and rebalancing the blocks across them.
Object storage, by contrast, provides an infinite, flat namespace. Data is stored as discrete “objects” (files), each with a unique key (a URL-like path) and associated metadata. There is no hierarchical directory structure; folders are merely a naming convention simulated by the prefixes in the object keys. You interact with object storage via simple REST APIs: PUT an object, GET an object, DELETE an object.
Because object storage abstracts away the underlying hardware, it provides virtually unlimited horizontal scalability, eleven nines of durability, and extraordinarily low cost per gigabyte. It is the perfect repository for the massive scale of a data lakehouse.
Diagram 1: Object Storage vs. Block Storage
2. Data File Formats (The Structural Layer)
While object storage can hold any type of file—from JPEGs to raw text—analytical data in the lakehouse must be stored in specialized formats optimized for querying. The most critical requirement is that these formats must be columnar.
In a traditional row-oriented format (like CSV or JSON), data is stored sequentially row by row. If an analyst runs a query like SELECT sum(revenue) FROM sales, the query engine must read every single row in the file, scanning past the customer names, addresses, and product IDs just to extract the revenue values. This is terribly inefficient for analytics.
In a columnar format, data is stored sequentially column by column. All the revenue values are stored together in one contiguous block. When the engine executes SELECT sum(revenue), it only reads the specific block of storage containing the revenue data, ignoring the rest of the file entirely. This dramatically reduces disk I/O and speeds up query execution. Furthermore, because all the values in a column are of the same data type, columnar formats can achieve massive compression ratios.
Apache Parquet is the undisputed industry standard for analytical data files. It is an open-source columnar format that provides aggressive compression, efficient encoding schemes (like dictionary encoding for repetitive string values), and file-level statistics (min/max values for each column) that allow query engines to skip reading the file entirely if they know the data they are looking for is not inside. ORC (Optimized Row Columnar) is a similar open format often used in Hadoop ecosystems.
3. Table Formats (The Metadata Layer)
If you have petabytes of Parquet files sitting in an S3 bucket, you have a data lake, but you do not yet have a data lakehouse. The missing piece is the Table Format.
A query engine cannot simply look at a bucket containing a million Parquet files and know which files belong to which table, which files are part of the current active dataset, and which files represent old data that was logically deleted yesterday but not physically removed from the bucket. Scanning a massive bucket to figure this out takes too long.
The Table Format (such as Apache Iceberg, Delta Lake, or Apache Hudi) solves this by acting as a metadata abstraction layer sitting between the Parquet files and the compute engines. It is essentially a sophisticated index.
When a compute engine wants to query the orders table, it does not scan the S3 bucket. Instead, it reads the table format’s metadata. The metadata provides a definitive, versioned manifest of exactly which specific Parquet files currently constitute the orders table.
Because the table format controls the definition of the table, it can provide database-like features that raw object storage lacks. If a job writes new Parquet files to the bucket, those files are not “visible” to anyone querying the table until the table format’s metadata is atomically updated to include them. This provides ACID transactions. By keeping track of older metadata manifests, the table format allows users to query the table exactly as it looked last week. This provides Time Travel.
Diagram 2: Storage Layer Hierarchy
The Decoupled Advantage
The combination of these three layers—Object Storage, Parquet Files, and a Table Format like Iceberg—creates a Storage Layer that is fully independent of any specific vendor’s compute engine.
Because the entire stack is built on open source standards, you are never locked in. If a new, faster query engine is released next year, you do not need to migrate your data. You simply point the new engine at your existing Iceberg metadata, and it can immediately begin querying your existing Parquet files sitting in your existing S3 bucket. This architectural flexibility is the ultimate promise of the modern data lakehouse.