Strict Metrics
Strict Metrics
When a query engine like Apache Spark or Trino runs a query against a data lakehouse, its primary goal during the planning phase is to read as little data as possible. To do this, it evaluates the WHERE clause (the predicate) against the metadata (the min/max statistics) of the Parquet files.
In Apache Iceberg, this evaluation happens at two levels: Inclusive Metrics Evaluation and Strict Metrics Evaluation.
Inclusive vs. Strict Evaluation
Inclusive Metrics answer a simple question: “Could this file possibly contain the data I’m looking for?”
If the query is WHERE Age = 30, and File A has min: 20, max: 40, the answer is yes. The file might contain a 30-year-old. The file is included in the scan plan.
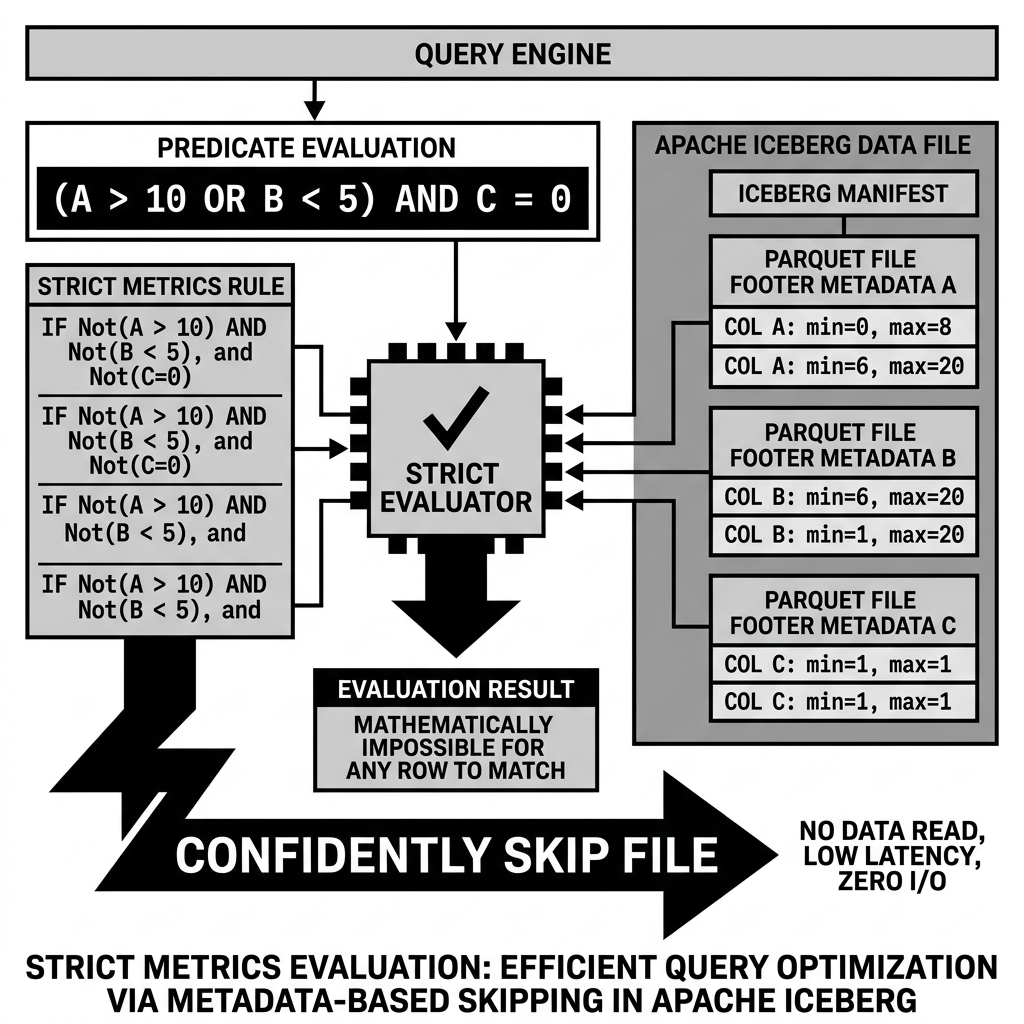
Strict Metrics answer a much more rigorous question: “Does every single row in this file mathematically guarantee a match for this predicate?” Strict metrics are used to definitively prove that a file, or conversely, that a file definitively cannot match a complex, multi-part logical predicate.
Diagram 1: Inclusive vs. Strict Metrics

Why Strict Metrics Matter
Strict Metrics evaluation shines when queries involve complex boolean logic (AND, OR, NOT).
Imagine a query: SELECT * FROM sales WHERE (amount > 1000 OR region = 'NA') AND status = 'COMPLETED'.
Iceberg’s strict evaluator takes this complex expression and pushes it down to the Manifest File layer. It looks at the min/max statistics and null counts for amount, region, and status for a specific Parquet file.
Using strict mathematical logic, the evaluator attempts to prove the negative. If the file’s status column has statistics of min: 'PENDING', max: 'PENDING', the strict evaluator knows immediately that status = 'COMPLETED' is false for every single row in that file. Because of the AND condition, if one side is definitively false, the entire complex predicate is false.
The file is confidently skipped.
This level of rigorous, metadata-driven evaluation allows modern query engines to process highly complex, deeply nested filters in a fraction of a second without ever touching the actual Parquet data files on disk. By aggressively pruning the search space using strict metrics, Iceberg ensures that compute clusters spend their CPU cycles crunching actual data, not scanning irrelevant files.
Diagram 2: Strict Metrics Evaluation