Table Format
If you look inside a traditional data lake, you will find a collection of directories and files. A table like sales_data is typically represented as a directory in object storage, containing hundreds or thousands of Parquet or CSV files. This approach, pioneered by Apache Hive, was revolutionary in its time, but it has severe limitations for modern, high-performance analytics.
When a query engine asks “What were the total sales yesterday?” against a Hive-style table, it has to perform a file system list operation to find all the files in the sales_data directory, open them to see if they contain yesterday’s data, and then process them. This listing operation is extremely slow on object storage like S3. Worse, if an ingestion job fails halfway through writing a new batch of files, the table is left in a corrupted state with partial data, because there is no mechanism for atomic transactions across multiple files.
A Table Format solves these problems. It is an abstraction layer that sits between the query engines and the raw data files. Instead of relying on the file system hierarchy to define what files belong to a table, a table format uses an explicit metadata structure to define the table. When a query engine reads a table format, it doesn’t scan directories; it reads a manifest that precisely lists every valid data file.
The three major open-source table formats in the industry today are Apache Iceberg, Delta Lake, and Apache Hudi. While their implementations differ, they all provide the same core set of capabilities that transform a sluggish data lake into a high-performance data lakehouse.
Key Capabilities of a Table Format
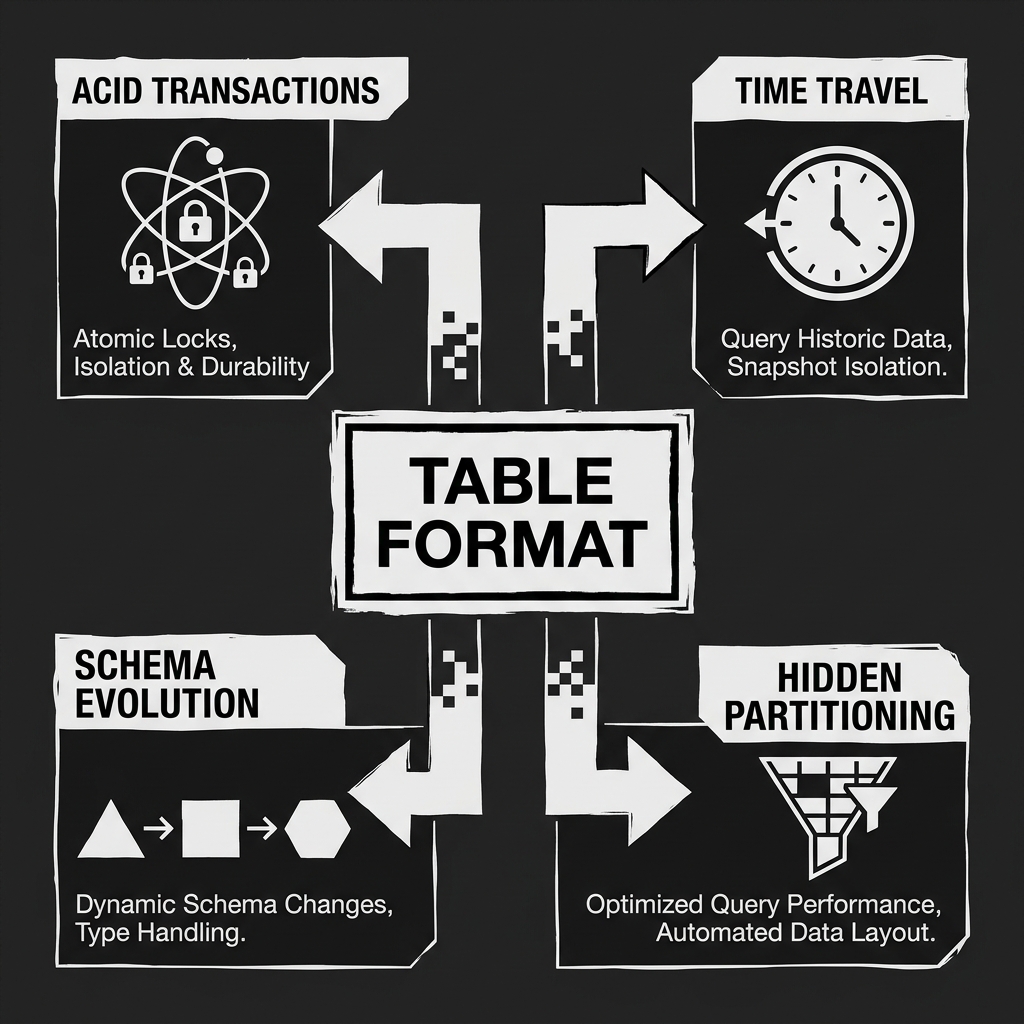
By controlling the definition of the table through metadata rather than file placement, table formats unlock features previously available only in proprietary relational databases.
ACID Transactions: When an ingestion job writes new files to a table format, it does not simply drop them in a directory. It creates a new metadata snapshot that atomically points to the new files alongside the old ones. Only when that metadata snapshot is committed do the new files become visible to readers. If the job fails, the commit never happens, and the partial files are ignored. This ensures that readers never see half-written data.
Time Travel and Rollbacks: Because every change to the table creates a new, immutable metadata snapshot, the table format retains a history of all previous states. An analyst can append a clause like AS OF '2026-01-01' to their SQL query, and the engine will read the metadata snapshot that was active on that date, returning the data exactly as it looked then. If a bad pipeline corrupts the table, engineers can simply roll the table’s state back to a previous healthy snapshot.
Schema Evolution: In a Hive-style table, renaming a column or changing a data type often requires rewriting the entire historical dataset. Table formats decouple the logical schema from the physical data files. You can safely add, drop, or rename columns, and the table format will track these changes in its metadata, allowing engines to read older files using the newer schema definitions without any rewriting.
Hidden Partitioning: Partitioning data (e.g., by date) is essential for query performance. But traditionally, query writers had to explicitly know the partitioning scheme and include it in their WHERE clauses, or else trigger a massive full-table scan. Table formats like Iceberg track the relationship between logical columns (like timestamp) and partition folders internally. The user simply queries WHERE timestamp = '2026-05-18', and the table format automatically prunes the unnecessary partitions behind the scenes.
Diagram 1: Table Format Metadata Architecture
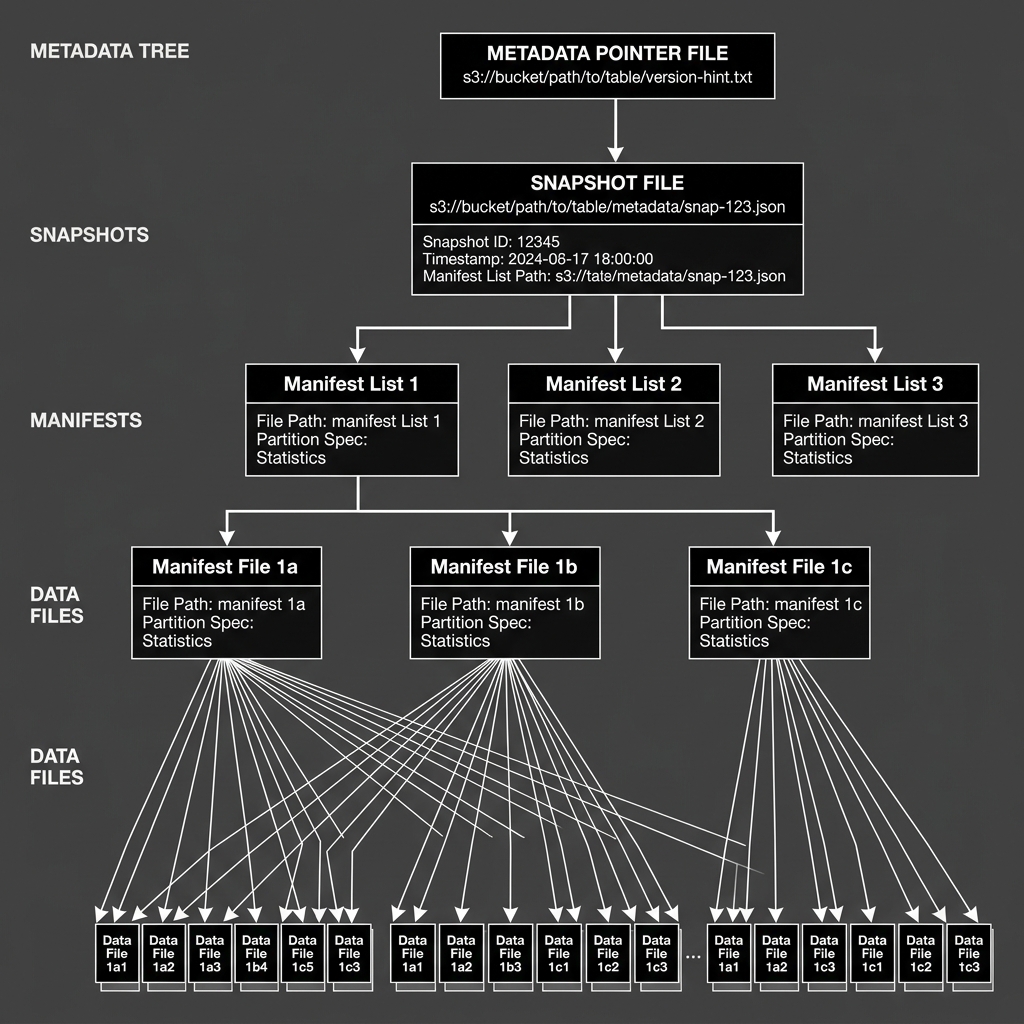
How the Metadata Tree Works
To understand how table formats deliver these features so quickly, it is helpful to look at the metadata structure of Apache Iceberg as an example.
Iceberg uses a hierarchical tree of metadata files, rather than a single monolithic file, to keep operations fast even on tables with millions of data files.
At the root of the tree is the Metadata Pointer File (the catalog pointer). This simply tells the query engine where to find the current active snapshot.
The Snapshot File defines the state of the table at a specific point in time. It contains the current schema and points to one or more Manifest Lists.
The Manifest List is an index of Manifest Files. Crucially, it stores summary statistics (like the minimum and maximum partition values) for the manifests it points to. This allows the query engine to completely ignore entire branches of the tree if it knows the data it needs is not there.
The Manifest File is the bottom layer of the metadata. It lists the actual physical Parquet files in object storage, along with detailed column-level statistics (min/max values, null counts) for each file.
When a query engine executes a filter like WHERE customer_id = 12345, it uses the min/max statistics in the Manifest List to quickly eliminate 99% of the Manifest Files. It then reads the remaining Manifest Files and uses their column-level statistics to eliminate 99% of the physical Parquet files. The engine ends up downloading and processing only the tiny fraction of data files that actually contain customer_id = 12345. This metadata-driven pruning is the secret to lakehouse performance.
Diagram 2: Core Table Format Features
The Open Standard Advantage
The most profound impact of table formats is that they are open standards. In a proprietary data warehouse, the vendor owns the metadata layer, meaning you can only access your data using that vendor’s compute engine.
With open table formats, the metadata layer is vendor-neutral. You can write to an Iceberg table using a streaming Apache Flink job, run heavy batch ETL against it using Apache Spark, and serve interactive sub-second dashboards from it using Dremio, all simultaneously, without moving or copying a single byte of data. The table format serves as the universal translator that allows all these disparate engines to agree on what the table looks like and safely interact with it at the same time.