Tabular
Tabular was a managed data lakehouse platform built entirely around Apache Iceberg, founded in 2021 by the original creators of the Apache Iceberg project: Ryan Blue (co-creator and Iceberg PMC Chair), Daniel Weeks (co-creator and Iceberg PMC member), and Jason Reid (formerly Director of Data Science & Engineering at Netflix). The company’s founding premise was straightforward: the people who built the most important open table format standard were the best equipped to build the managed service that made that standard operationally accessible at enterprise scale.
In June 2024, Databricks acquired Tabular in a landmark consolidation of the open lakehouse ecosystem — bringing together the original creators of Apache Iceberg (the Tabular team) with the organization behind Delta Lake (Databricks), and creating the potential for deeper technical integration between the two leading open table formats.
Understanding Tabular’s architecture, philosophy, and technical contributions is essential for understanding the arc of the Iceberg ecosystem’s commercial development and why its foundational design decisions continue to influence the managed catalog landscape.
The Founding Vision: The Headless Data Warehouse
Tabular’s founders conceived of the product as a “headless data warehouse” — a concept that captures precisely what separates a lakehouse from a traditional data warehouse and what Tabular was designed to enable.
A traditional data warehouse (Snowflake, Redshift, BigQuery) bundles storage, catalog, compute, and governance into a monolithic, vendor-controlled package. You store your data in the vendor’s proprietary format, governed by the vendor’s catalog, queried by the vendor’s compute engine, with access controlled by the vendor’s security model. This integration delivers excellent user experience but at the cost of complete vendor lock-in: your data, your catalog, and your compute are all owned and controlled by one vendor.
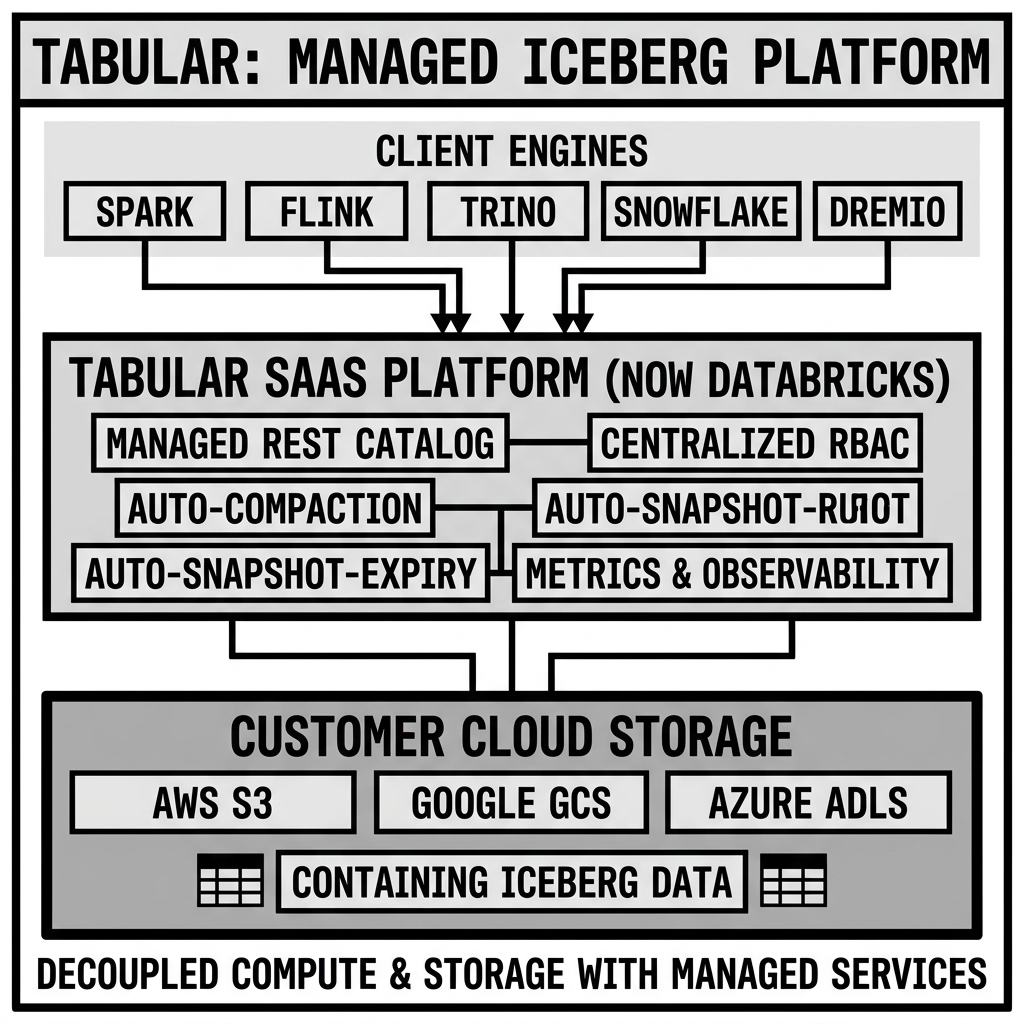
A headless data warehouse separates these concerns. Tabular provided:
- Your data, your storage: Data stays in customer-owned S3, GCS, or ADLS, in the open Apache Iceberg format, accessible by any engine without Tabular’s involvement.
- Managed catalog and governance: Tabular provides the catalog service (table registration, schema management, snapshot history) and the governance layer (RBAC, access control), fully managed by Tabular’s infrastructure.
- Engine-agnostic compute: Any compute engine (Spark, Trino, Flink, Snowflake, Athena, Dremio) can access Tabular-managed tables through the open Iceberg REST Catalog API. No engine lock-in.
This architecture offered a genuinely novel value proposition: the operational simplicity of a managed data warehouse (no catalog infrastructure to run, no table maintenance to schedule) with the engine flexibility and data portability of an open data lake. Organizations could use any query engine for any workload — Spark for heavy transformations, Trino for interactive analytics, Snowflake for governed SQL access — all pointing at the same Tabular-managed Iceberg tables.
The Tabular Architecture
The Managed REST Catalog
At the core of the Tabular service was its managed implementation of the Apache Iceberg REST Catalog API. Tabular was one of the earliest implementors of the REST Catalog specification, having been deeply involved in its definition (the Iceberg REST Catalog API was substantially co-designed by the same people who founded Tabular and who were driving Iceberg’s specification).
The Tabular catalog exposed the standard Iceberg REST Catalog endpoints:
- Table CRUD (create, load, drop, rename)
- Namespace management (create, list, delete namespaces)
- Atomic table commit (compare-and-swap with
requirementsandupdates) - Credential vending (short-lived, scoped S3/GCS/ADLS credentials)
Because Tabular’s REST Catalog was built by the people who wrote the Iceberg REST Catalog specification, it served as the reference implementation for catalog compliance — engine developers testing their REST Catalog clients would use Tabular to verify their implementation against the authoritative server.
Automated Table Maintenance
One of Tabular’s most operationally significant features was fully automated table maintenance. Running an Iceberg table in production requires regular execution of multiple maintenance operations — operations that, in self-managed deployments, require engineering time to schedule, monitor, and troubleshoot:
Compaction: Merging small files into optimally-sized files (128MB–512MB target). Without compaction, streaming ingestion pipelines accumulate thousands of small files, degrading query performance by orders of magnitude. Tabular monitored each table’s file size distribution and automatically triggered compaction when the small file count exceeded a configurable threshold.
Snapshot expiry: Retaining old Iceberg snapshots indefinitely consumes storage and slows down metadata operations. Tabular’s automated snapshot expiry deleted snapshots older than the configured retention window, keeping the snapshot history at a manageable size while preserving the configured time-travel window.
Orphan file cleanup: Failed write operations leave partially-written Parquet files on object storage that are never referenced by any Iceberg snapshot. Without cleanup, these files accumulate silently, wasting storage. Tabular identified orphan files by comparing the complete list of files in the table’s S3 prefix against the files referenced in the current snapshot’s Manifest Files, then deleted the unreferenced files.
Metadata compaction: After many commits, Iceberg’s Manifest Files can become large and numerous, slowing down query planning. Tabular’s metadata compaction merged small Manifest Files into larger ones, keeping the metadata layer compact and fast.
All of these operations ran automatically in the background, with no user scheduling or monitoring required. This was a significant operational advantage over self-managed Iceberg deployments, where maintaining table performance required dedicated data engineering effort to design, schedule, and operate maintenance pipelines.
RBAC and Access Governance
Tabular implemented table-level RBAC for governing which users and compute engines could access which tables:
Roles: Named permission groups (e.g., data_engineers, analysts, etl_pipelines). Roles are assigned to users, service accounts, and compute clusters.
Grants: Specific access permissions granted to roles at the catalog, namespace, or table level. Common grant types:
CATALOG_MANAGE_CONTENT: Full DDL and DML permissions.TABLE_READ: Read-only access to table data.TABLE_WRITE: Read and write access.
Service principals: Named machine identities for compute engines (a Spark cluster’s service account, a Trino coordinator’s service account). Each service principal is assigned roles, and those role assignments determine what tables and operations the engine is permitted to perform.
Credential vending through RBAC: When an engine loaded a table through the Tabular REST Catalog, Tabular’s credential vending engine evaluated the engine’s service principal role assignments, determined the appropriate access level, and generated scoped S3 credentials for only the specific table paths the engine was authorized to access. A Trino cluster with TABLE_READ on table A and no access to table B would receive S3 credentials scoped only to table A’s S3 prefix — it was physically unable to access table B’s data files, even if it somehow learned the S3 path.
This credential-vending-enforced access control was one of Tabular’s strongest governance differentiators: access control was not just logical (enforced by the catalog API) but physical (enforced by the cloud provider’s STS, making it technically impossible for an unauthorized engine to read unauthorized data).
Tabular’s Contribution to the Iceberg Specification
Beyond the product itself, Tabular’s most enduring contribution to the lakehouse ecosystem was its foundational role in shaping the Iceberg specification’s evolution. During Tabular’s operational years (2021–2024), the Tabular team drove several of Iceberg’s most important specification advances:
The REST Catalog Specification: As noted above, the Iceberg REST Catalog API was substantially co-designed by the Tabular founders (who were also the Iceberg specification leaders). Tabular’s production implementation provided the real-world validation that drove the specification toward practical completeness.
Iceberg Views: The Iceberg View specification (defining how stored SQL views are represented and managed in Iceberg’s metadata format and REST Catalog API) was substantially driven by the Tabular team, providing the missing piece for organizations that needed both the data tables and the query abstractions that operate on them to be Iceberg-native.
Iceberg Puffin Files: The Tabular team contributed to the design of the Puffin file format for storing extended statistics (Bloom Filters, NDV Theta Sketches, histograms) as table-level index structures, enabling the advanced statistics-based query optimization described in the Column-Level Statistics article.
Multi-table atomic commits: Tabular’s real-world use cases for multi-table consistency drove the REST Catalog specification’s multi-table commit endpoint design, providing the production experience that informed the specification’s constraints and success criteria.
The Databricks Acquisition: Implications for the Ecosystem
Databricks’ June 2024 acquisition of Tabular was the most consequential event in the open lakehouse ecosystem since the founding of both companies. Its implications were immediate and multi-dimensional:
Iceberg expertise at Databricks: The Tabular team, including Ryan Blue (the most prominent individual contributor to the Iceberg specification), joined Databricks. This concentrated the leadership of both Delta Lake (Databricks’ native format) and Apache Iceberg (the broader industry standard) within a single organization.
Delta–Iceberg convergence: Databricks announced deeper integration between Delta Lake and Iceberg, including expanded Delta UniForm support and closer alignment between Databricks’ table maintenance tooling and Iceberg’s maintenance operations. The Tabular team’s Iceberg expertise directly informed Databricks’ Iceberg roadmap.
Tabular’s service sunset/integration: The Tabular standalone managed service was gradually integrated into Databricks’ Unity Catalog product, with Tabular customers migrating to Unity Catalog-based Iceberg table management. This integration brought Tabular’s automated maintenance and credential vending capabilities into the Unity Catalog platform.
Open lakehouse governance implications: With Databricks now controlling the leadership of both Delta Lake and Apache Iceberg (through the acquisition of the Iceberg founders), and with Apache Polaris (Snowflake’s contribution) as the alternative open-source catalog, the governance of the open lakehouse ecosystem became concentrated around two major vendors. This concentration prompted renewed discussion within the ASF about ensuring Iceberg’s specification governance remained genuinely community-driven rather than vendor-driven.
The Legacy: Proving the Headless Data Warehouse Model
Tabular’s most important legacy is not the product itself (which was absorbed into Databricks) but the proof of concept it provided: the “headless data warehouse” model — managed catalog + governance + table maintenance, with engine-agnostic compute and user-owned storage — is operationally viable and commercially attractive.
The features Tabular pioneered (managed REST Catalog, automated table maintenance, credential-vending RBAC) are now standard expectations for any enterprise-grade managed Iceberg catalog service. Polaris (from Snowflake), managed Iceberg offerings from AWS (Glue managed optimization), and Unity Catalog (from Databricks, incorporating the Tabular team) all implement variations of the core Tabular architecture: REST Catalog API + managed maintenance + credential vending + table-level RBAC.
Conclusion
Tabular represented the definitive proof that Apache Iceberg could support a viable managed service business — that the open table format’s richness of metadata, extensibility of catalog protocols, and correctness of ACID guarantees were sufficient to build a production-grade managed data platform. The company’s founders, having invented Iceberg at Netflix, built the most technically authoritative Iceberg implementation in the commercial ecosystem, and their contributions to the Iceberg REST Catalog specification, Iceberg Views, and Puffin file statistics continue to shape the open standard long after Tabular’s independent existence ended. The 2024 Databricks acquisition transferred that expertise and those product capabilities into the broader Unity Catalog ecosystem, where they continue to define the state of the art for managed Iceberg table governance.
Visual Architecture