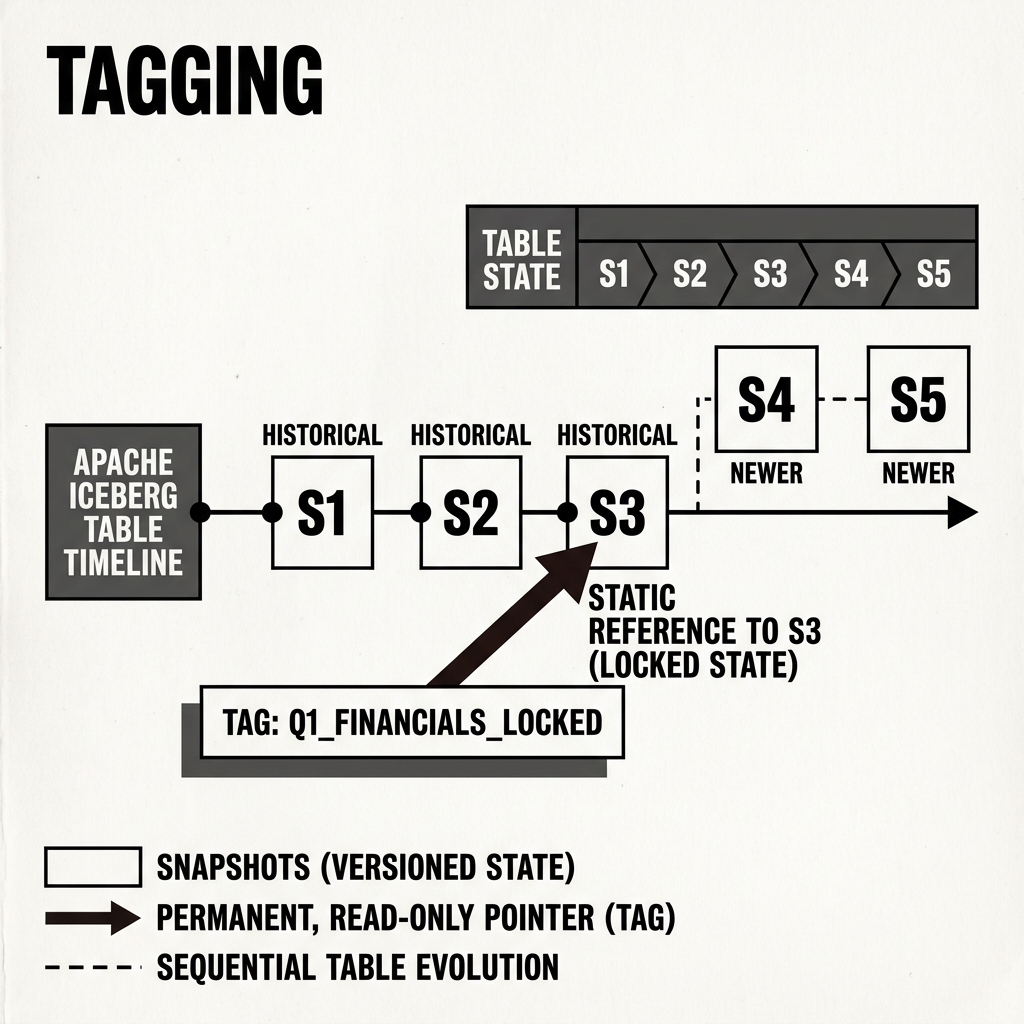
Tagging (Iceberg)
While Time Travel allows you to query historical data by providing a specific Snapshot ID or Timestamp, remembering a random 19-digit number like 4920194857291039485 is not practical for long-term data management.
To solve this, Apache Iceberg introduced Tagging.
A Tag in Iceberg is simply a human-readable, named pointer (e.g., Q1_FINANCIALS_LOCKED) that acts as a permanent bookmark to a specific, immutable Snapshot. Unlike a Branch, which is designed to evolve and move forward as new data is written, a Tag is explicitly designed to remain static.
Creating Human-Readable Bookmarks
When a fiscal quarter closes, the finance team needs a guarantee that they can audit the exact state of the ledger for years to come.
Instead of writing down the active Snapshot ID on a sticky note, a data engineer executes an ALTER TABLE command to create a Tag: ALTER TABLE ledger CREATE TAG Q1_FINANCIALS_LOCKED AS OF VERSION 4920194857291039485.
Now, if an auditor needs to verify the data two years later, they do not need to hunt for the old Snapshot ID. They simply execute: SELECT * FROM ledger VERSION AS OF 'Q1_FINANCIALS_LOCKED'. The Iceberg catalog instantly routes the query to the exact Snapshot anchored by the Tag.
Diagram 1: The Tagging Concept
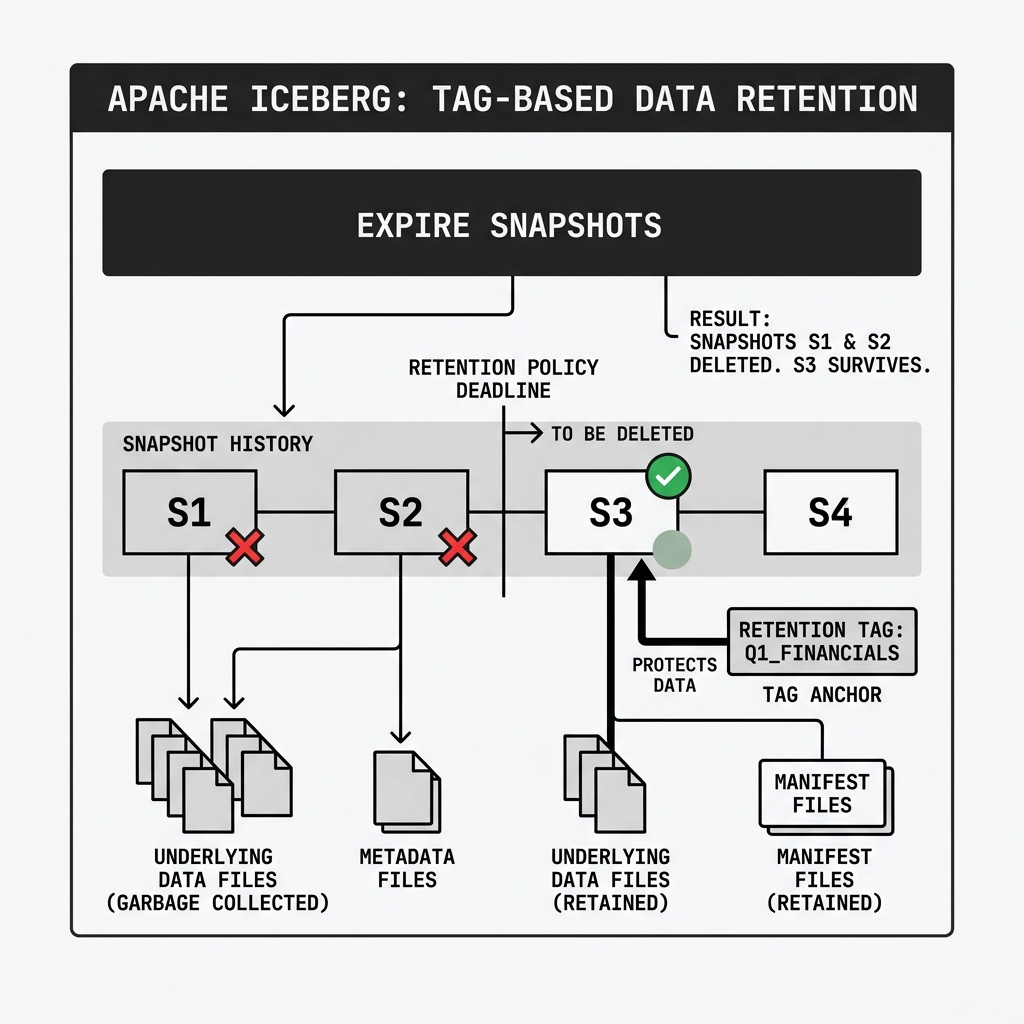
Protecting Data from Garbage Collection
The most critical function of a Tag is its relationship with Iceberg’s garbage collection processes.
In a high-throughput lakehouse, generating hundreds of Snapshots a day consumes massive amounts of storage. To control costs, engineers run Expire Snapshots jobs to delete old Snapshots and physically delete the underlying Parquet files from object storage.
However, if a Snapshot is anchored by a Tag, Iceberg’s metadata tree flags it as protected.
Even if the Expire Snapshots routine is configured to delete everything older than 30 days, Iceberg will automatically skip any Snapshot that has an active Tag pointing to it. The Tag guarantees that the exact combination of Manifests and Parquet files required to reconstruct that historical state will be retained in object storage, ensuring long-term auditability and machine learning reproducibility.
Diagram 2: Tag-Based Data Retention