Transaction Log
The Transaction Log is one of the most fundamental data structures in computer science. Originally developed to give relational databases the ability to survive hardware failures without losing committed data, the transaction log has evolved into the architectural backbone of the modern data lakehouse. Every major Open Table Format — Delta Lake’s _delta_log, Apache Hudi’s Timeline, and Apache Iceberg’s Metadata JSON chain — is, at its core, a specialized implementation of the transaction log concept applied to the unique constraints of distributed cloud object storage.
To understand why every Open Table Format converged on a log-based design, and to understand the precise mechanisms through which these logs deliver ACID guarantees, crash recovery, and Time Travel, it is necessary to understand the transaction log from its first principles in database theory up through its specific manifestations in the modern lakehouse ecosystem.
The First Principles: Why Logs?
The transaction log solves a fundamental problem in computing: the discrepancy in reliability between volatile memory (RAM) and persistent storage (disk or object storage). Processors execute computations in RAM, which is extraordinarily fast — nanosecond-latency reads and writes. But RAM is volatile: if power is removed, every bit disappears instantly. Persistent storage (hard drives, SSDs, or cloud object storage) is orders of magnitude slower, but it retains data indefinitely without power.
In any database, a transaction may modify hundreds or thousands of data structures in memory during its execution. The database cannot write each individual in-memory modification to persistent storage immediately — that would require thousands of random-access writes per transaction, destroying throughput. But if the database only writes to persistent storage at the end of a transaction, a crash mid-transaction leaves the database in an indeterminate state: some modifications might have been flushed to disk, others might not.
The Write-Ahead Log (WAL) Solution
The Write-Ahead Log (WAL) is the foundational solution to this problem. The WAL rule is simple and absolute: before applying any change to the database’s actual data files, write a description of that intended change to the log.
The log is always written first (hence “write-ahead”). Only after the log entry is safely on persistent storage does the system proceed to apply the change to the actual data structures. If the system crashes at any point:
- If the crash occurred before the log entry was written, the transaction is simply lost — but the data files are in a consistent pre-transaction state, because no changes were applied.
- If the crash occurred after the log entry was written but before the data files were updated, the system restarts, reads the log, and re-applies the changes from the log entry (redo). The data files are brought to the correct post-transaction state.
- If the crash occurred after both the log entry and the data file changes were completed but before the transaction was marked committed, the system restarts, reads the log, sees an uncommitted transaction, and undoes its effects (undo). The data files are returned to the pre-transaction state.
This redo/undo mechanism guarantees that the database always returns to a consistent state after a crash, regardless of when exactly the crash occurred during a transaction.
Logs as the Source of Truth
Beyond crash recovery, the transaction log has a deeper property: it is a complete, ordered record of every change ever made to the database. If you replay the log from the very beginning, you can reconstruct the exact current state of the database from scratch. This means the log, not the data files themselves, is the authoritative source of truth for what the database contains.
This property is the direct predecessor of the Time Travel capability in modern Open Table Formats. If the log retains its history for 30 days, you can replay the log up to any point within those 30 days and reconstruct the exact state of the database at that moment in time.
The Append-Only Architecture
A transaction log is strictly append-only. Old log entries are never modified or deleted while they are within the retention window. New entries are always added at the tail of the log.
This append-only property is critical for three reasons:
Sequential Write Performance
Append operations are the fastest possible writes to any storage medium, from a spinning hard drive to Amazon S3. A spinning disk’s read/write head is already positioned at the end of the log file from the previous write — writing the next entry requires no seek operation. On SSDs, sequential writes saturate write bandwidth far more efficiently than random writes. On cloud object storage like S3, new object writes (which are always sequential) complete without any need for expensive read-modify-write cycles.
The practical consequence is that a database or table format can sustain very high transaction throughput precisely because every commit is a fast, sequential append to the log, regardless of how complex or large the underlying data modification was.
Immutability and Reader Isolation
Because log entries are never modified, a reader that begins traversing the log at any point can always read a consistent, immutable history. There is no risk of a concurrent writer modifying a log entry that a reader is in the middle of processing. This property enables the Snapshot Isolation that modern Open Table Formats rely on for concurrent readers and writers.
When a Spark cluster writes a new Delta commit entry to the _delta_log/, every concurrent Trino query is safely reading an older set of log entries. The Trino query sees a perfectly consistent snapshot of the table’s state at the moment it began, unaffected by the concurrent Spark write. The Spark write similarly proceeds unaffected by the ongoing Trino reads. This is not achieved through locks — it is achieved through the immutability of the append-only log.
Auditability and Compliance
An append-only log is a perfect audit trail. Every change ever made to the data — who made it, when, what was added, what was removed — is permanently recorded in chronological order. For regulatory compliance (GDPR, SOX, HIPAA) and operational forensics (debugging a bad pipeline run), this complete, tamper-evident history is invaluable. Data governance teams can answer questions like “what was in this table at 11:37 PM on March 14?” or “when exactly was customer 99’s record first inserted and what were its subsequent modifications?” — questions that are simply unanswerable in legacy data lake architectures without a transaction log.
Transaction Log Implementations in Open Table Formats
While all three major Open Table Formats implement a transaction log, they do so with meaningful architectural differences that produce different performance and operational trade-off profiles.
Delta Lake: The Sequential JSON Log
Delta Lake’s transaction log is the most conceptually straightforward implementation. It is a flat directory (_delta_log/) containing sequentially numbered JSON files (00000000000000000000.json, 00000000000000000001.json, etc.). Each JSON file represents one atomic commit.
The sequential numbering is both the strength and the critical concurrency mechanism of Delta’s log. Because writers commit by creating a new file with the next sequential number, and because cloud object stores provide conditional “put if absent” semantics, the file creation is itself the atomic commit operation. The first writer to successfully create 00000000000000000005.json wins; any concurrent writer that also attempts to create 00000000000000000005.json gets a conflict response and must retry with 00000000000000000006.json.
Delta’s log is extremely readable and debuggable: a data engineer can open any JSON commit file in a text editor and immediately understand exactly what files were added and removed in that transaction, along with the complete column statistics for each added file. This operational transparency is one of Delta Lake’s most underappreciated engineering advantages.
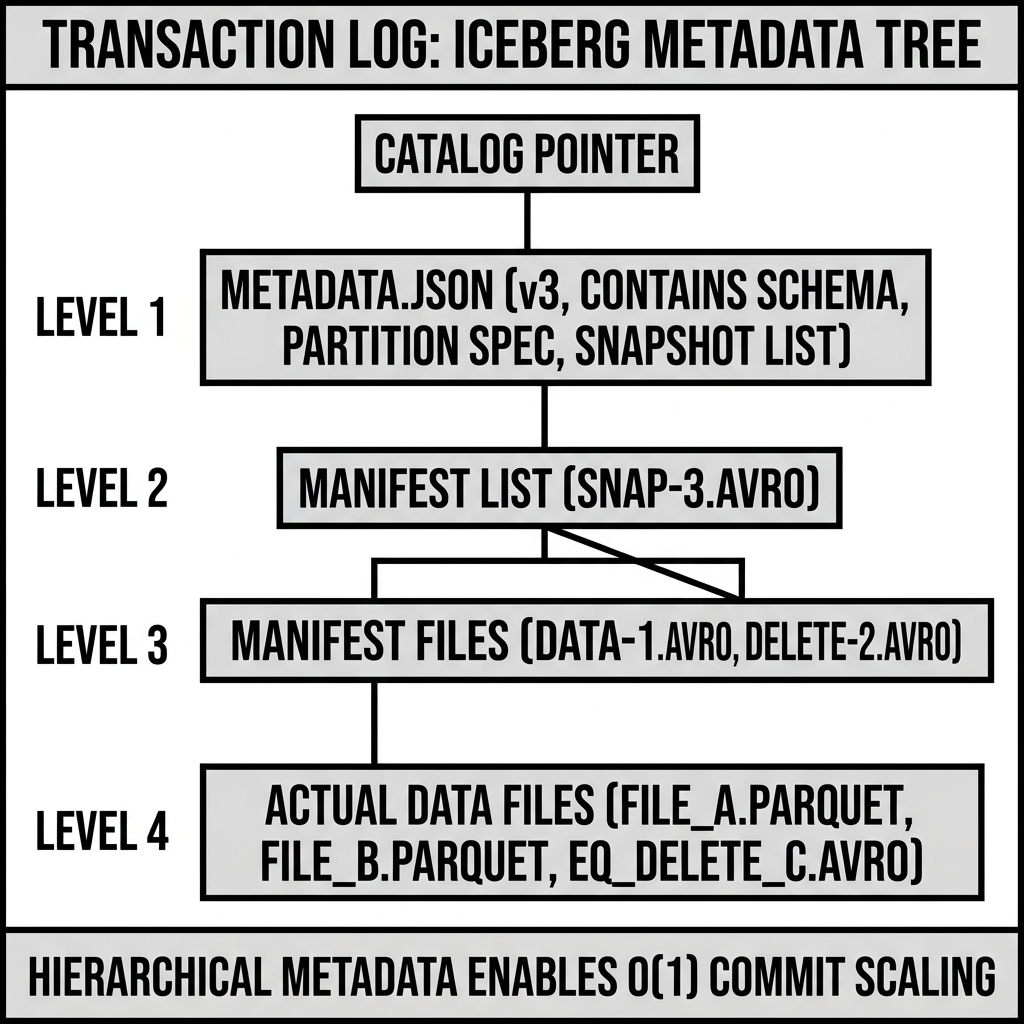
Apache Iceberg: The Metadata Pointer Chain
Iceberg implements the transaction log as a linked chain of immutable JSON metadata files. The current state of the table is always represented by the most recently committed metadata JSON. Each metadata JSON contains a previous-metadata-log array — a list of pointers to all prior metadata JSON files, forming the log history.
Unlike Delta’s single _delta_log/ directory, Iceberg’s log is distributed: each metadata JSON file lives alongside the table’s data files in the object storage, and the current metadata file’s path is tracked by the Catalog (which holds the current metadata pointer). Committing a new Iceberg transaction means writing a new metadata JSON (with the new snapshot entry and the updated previous-metadata-log array) and performing a catalog-level compare-and-swap to update the current metadata pointer from the old file to the new one.
This two-phase commit (write the metadata file, then update the catalog pointer) is more operationally complex than Delta’s single-file creation, but it provides a cleaner separation between the log content (stored in immutable object files) and the current state pointer (managed by the catalog service).
Apache Hudi: The Multi-State Timeline
Hudi’s implementation of the transaction log — the Timeline — is the most sophisticated of the three. As described in detail in the Apache Hudi article, the Timeline tracks each action through three states (REQUESTED, INFLIGHT, COMPLETED), enabling crash detection and automatic rollback of incomplete transactions by subsequent writers.
The multi-state design makes Hudi’s log more complex to parse and reason about than Delta’s JSON files, but it provides a critical operational advantage: any Hudi writer can detect mid-flight transactions from a crashed predecessor and clean them up, ensuring the table never gets stuck in a partially-written state that requires manual intervention to resolve.
Checkpointing: The Log Performance Solution
A transaction log that is never truncated will grow indefinitely. Replaying an infinitely long log from the beginning to reconstruct the current state would take infinitely long. Every transaction log implementation needs a checkpointing mechanism — a way to periodically create a complete snapshot of the current state that allows log replay to start from a recent, known-good point rather than from the very beginning.
Delta Lake Checkpoints
Delta Lake creates a Parquet checkpoint file every 10 commits (configurable). The checkpoint contains the complete current state of the table — all active add entries with their statistics. When a reader needs to determine the current file set, it:
- Finds the most recent checkpoint file.
- Reads the checkpoint to get the bulk state.
- Replays only the JSON commit files that were created after the checkpoint.
This bounds the log replay cost regardless of table age.
Iceberg Snapshot Expiry
Iceberg’s equivalent of checkpointing is Snapshot Expiry. Rather than compacting the log into a single checkpoint file, Iceberg simply truncates the previous-metadata-log array in the current metadata JSON to remove entries for snapshots older than the retention window. The metadata files for expired snapshots are scheduled for physical deletion. Because each Iceberg metadata JSON is a self-contained complete state (it includes the full current snapshot reference directly, not just a delta), there is no need to replay historical entries to reconstruct the current state — the current metadata JSON directly encodes it.
Hudi’s LSM-Based Timeline Compaction
As described in the Hudi article, modern Hudi versions use an LSM-tree-based timeline that compacts Timeline Instants into larger metadata blocks, preventing unbounded growth of individual small instant files while maintaining full historical access for Time Travel and incremental reading.
Concurrent Writers and Log-Based Conflict Resolution
The transaction log is the foundation of concurrency control in all three formats. Each format uses the log’s properties to implement Optimistic Concurrency Control:
- A writer reads the current log state to establish its base version.
- The writer performs its computation and writes output files.
- The writer attempts to commit a new log entry, conditional on the log still being at the version it started from.
- If the log has advanced (another writer committed first), the writer reads the new log entries, determines if there is a logical conflict, and either retries (if no conflict) or raises an exception (if genuine conflict).
This protocol works because the log is the authoritative source of truth for the table’s state. By making the commit conditional on the log version, the protocol ensures that no writer can create an inconsistent view of the data by basing its commit on stale state.
The Log as the Enabler of Distributed Data Collaboration
At the highest level of abstraction, the transaction log is what transforms a collection of files on cloud object storage into a collaborative, multi-reader, multi-writer, transactional data asset. Without the log, a set of Parquet files on S3 is a static artifact — it can be read, but it cannot be safely updated, cannot be versioned, cannot support concurrent access, and cannot be rolled back after a mistake.
With the log, those same files become a living database with the full suite of ACID properties, Time Travel history, and concurrent access safety that enterprises expect from their most critical data systems. The Delta _delta_log/, Hudi Timeline, and Iceberg metadata chain are not implementation details — they are the architectural core from which every other advanced lakehouse capability emerges.
Conclusion
The transaction log is the oldest and most reliable mechanism for managing state changes in persistent storage systems. Its application to the modern data lakehouse — through Delta Lake’s JSON commit sequence, Iceberg’s metadata pointer chain, and Hudi’s multi-state Timeline — demonstrates the enduring relevance of this fundamental computer science concept. Every feature of a modern Open Table Format that data engineers rely on daily — ACID transactions, Time Travel, Rollback, concurrent safe writes, crash recovery — is a direct consequence of the transaction log’s append-only, immutable, causally-ordered architecture. Understanding the transaction log at this level of depth is not academic; it is the prerequisite for understanding why lakehouse architectures behave the way they do under both normal operation and failure conditions.
Visual Architecture