Trino
Trino (formerly known as PrestoSQL) is a highly parallel and distributed open-source SQL query engine. It was designed from the ground up to execute interactive, low-latency analytics against massive datasets. Unlike traditional relational database management systems, Trino does not store data itself. Instead, it decouples compute from storage, allowing users to query data where it currently resides using standard ANSI SQL. Trino is a cornerstone of the modern data lakehouse, providing blazing-fast read access to open table formats like Apache Iceberg, Delta Lake, and Apache Hudi.
Core Definition
Trino originated at Facebook in 2012 under the name Presto to address the performance limitations of Apache Hive. While Hive translated SQL queries into MapReduce jobs that relied heavily on disk I/O, Presto was engineered as an in-memory, Massively Parallel Processing (MPP) engine. By keeping intermediate results in memory and pipelining execution across a cluster, Presto achieved query speeds that were orders of magnitude faster than Hive, enabling truly interactive data exploration.
In 2018, the original creators of Presto departed Facebook and formed a fork of the project, initially called PrestoSQL, which was later rebranded to Trino to distinguish it from the PrestoDB project retained by Facebook. Today, Trino is maintained by the Trino Software Foundation and enjoys widespread adoption across the industry.
The fundamental value proposition of Trino is its ability to perform federated queries. Because Trino separates the processing engine from the storage mechanism, it relies on a plugin architecture called Connectors. Connectors allow Trino to communicate with various external systems. A user can write a single SQL query that joins live operational data residing in a PostgreSQL database with historical analytical data sitting in an Amazon S3 data lake. Trino handles the complex task of optimizing the query, pushing down predicates to the respective source systems, and merging the results in memory.
Architecture and Components
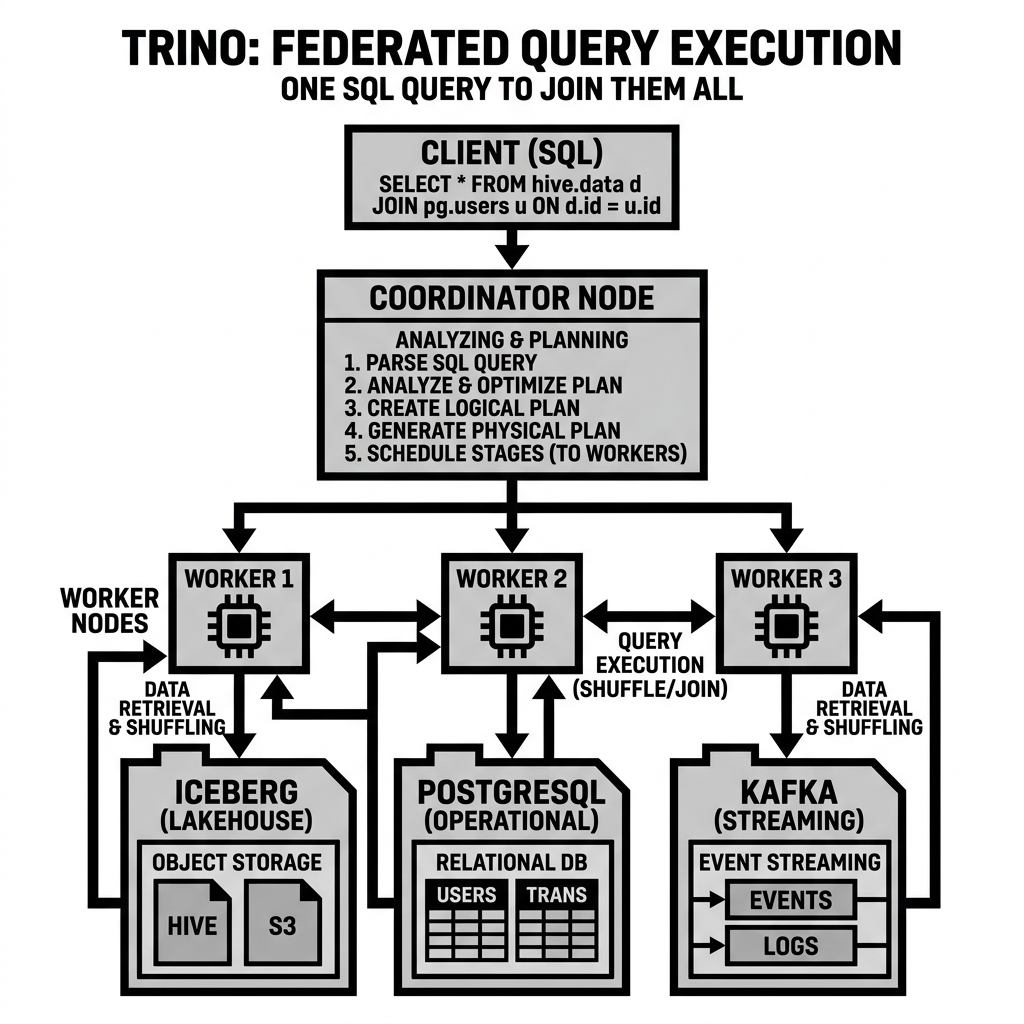
The architecture of a Trino cluster is based on a classic coordinator-worker model.
The Coordinator is the brain of the cluster. It receives SQL statements from clients (via JDBC, ODBC, or the Trino CLI), parses the SQL, analyzes the query, and generates a distributed execution plan. The Coordinator tracks the status of all available Worker nodes and schedules the execution of the query fragments across the cluster. It is also responsible for managing the metadata integration via the configured connectors.
The Workers are the muscles of the cluster. They receive tasks from the Coordinator, fetch the required data from the underlying storage systems using the appropriate connectors, process the data in memory, and exchange intermediate results with other Workers. Once the final computation is complete, the results are passed back to the Coordinator, which returns them to the client.
To achieve its high performance, Trino utilizes a vectorized execution model. Instead of processing data row by row, Trino processes data in blocks. This allows the engine to leverage modern CPU architectures, minimizing branch mispredictions and maximizing cache locality. Furthermore, Trino is written in Java but uses advanced techniques like byte-code generation to dynamically compile specialized execution code for specific query operations at runtime.
Integration with the Data Lakehouse
Trino is primarily known as a read-optimized query engine for the data lakehouse. It provides native connectors for modern open table formats, with the Apache Iceberg connector being particularly robust and widely utilized.
When querying an Iceberg table, Trino leverages the rich metadata provided by the Iceberg format to accelerate execution. The Coordinator reads the Iceberg manifest lists and manifest files to evaluate the query’s filters against the column-level statistics stored in the metadata. This allows Trino to aggressively prune irrelevant data files before any tasks are assigned to the Workers.
Once the physical files are identified, the Coordinator splits the read operations into discrete tasks and distributes them across the Worker nodes. The Workers then read the underlying Parquet or ORC files directly from object storage in parallel. Because the data layout is optimized and the irrelevant files have been skipped, Trino can scan terabytes of data and return aggregations in seconds.
While Trino excels at reads, it also supports writing data to the lakehouse. It can perform INSERT, UPDATE, and DELETE operations against Iceberg tables, executing the transactional metadata updates required to maintain ACID compliance. However, for massive, complex ETL pipelines requiring hundreds of nodes and extensive shuffle operations, engineers often prefer engines like Apache Spark due to its fault-tolerant, disk-spilling architecture.
Federated Query Execution
The connector architecture is what enables Trino’s powerful federation capabilities. A single Trino cluster can be configured with dozens of catalogs, each backed by a different connector.
For example, a user could configure a lakehouse catalog pointing to an Iceberg environment, a mysql catalog pointing to a production relational database, and a kafka catalog pointing to a real-time message queue.
A user can then execute a query such as:
SELECT l.customer_id, m.account_status FROM lakehouse.sales.orders l JOIN mysql.crm.users m ON l.customer_id = m.id
When the Coordinator analyzes this query, it attempts to push down as much computation as possible to the source systems. If the query includes a filter like WHERE m.account_status = 'active', Trino will push that filter down to the MySQL database. The database executes the filter and returns only the relevant rows over the network to the Trino Workers. The Workers then perform the final join in memory against the data retrieved from the lakehouse. This minimizes data movement and significantly reduces query latency.
Summary and Tradeoffs
Trino has established itself as the gold standard for interactive, ad-hoc SQL querying across the open data lakehouse. Its in-memory MPP architecture, vectorized execution, and robust connector ecosystem make it an incredibly powerful tool for data scientists and analysts who demand fast answers from massive datasets.
The primary tradeoff with Trino is its strict reliance on in-memory processing. If a query requires more memory than is available across the cluster (for example, during a massive JOIN or GROUP BY operation involving billions of highly distinct rows), the query will fail with an out-of-memory error. Unlike Apache Spark, Trino was traditionally not designed to gracefully spill intermediate shuffle data to disk to survive memory exhaustion. While recent versions of Trino have introduced fault-tolerant execution modes that add disk spilling capabilities, it generally remains optimized for speed over resilience in the face of massive, complex ETL transformations.
Despite this, for the vast majority of analytical read workloads, federated queries, and dashboarding applications, Trino provides unparalleled speed and flexibility. It successfully abstracts away the complexities of the underlying storage layers, providing a unified, high-performance SQL interface to the entire data ecosystem.
Visual Architecture