Vectorized Execution
Vectorized Execution is a data processing paradigm utilized by the fastest modern analytical database engines. Instead of processing data one row at a time, a vectorized engine processes data in batches (vectors) consisting of hundreds or thousands of values simultaneously. By aligning the software’s execution model with the physical architecture of modern CPUs—specifically leveraging SIMD (Single Instruction, Multiple Data) instruction sets and maximizing CPU cache locality—vectorized execution delivers orders of magnitude improvements in query performance compared to legacy execution models.
Core Definition
To understand vectorized execution, one must contrast it with the traditional approach: the Volcano iterator model.
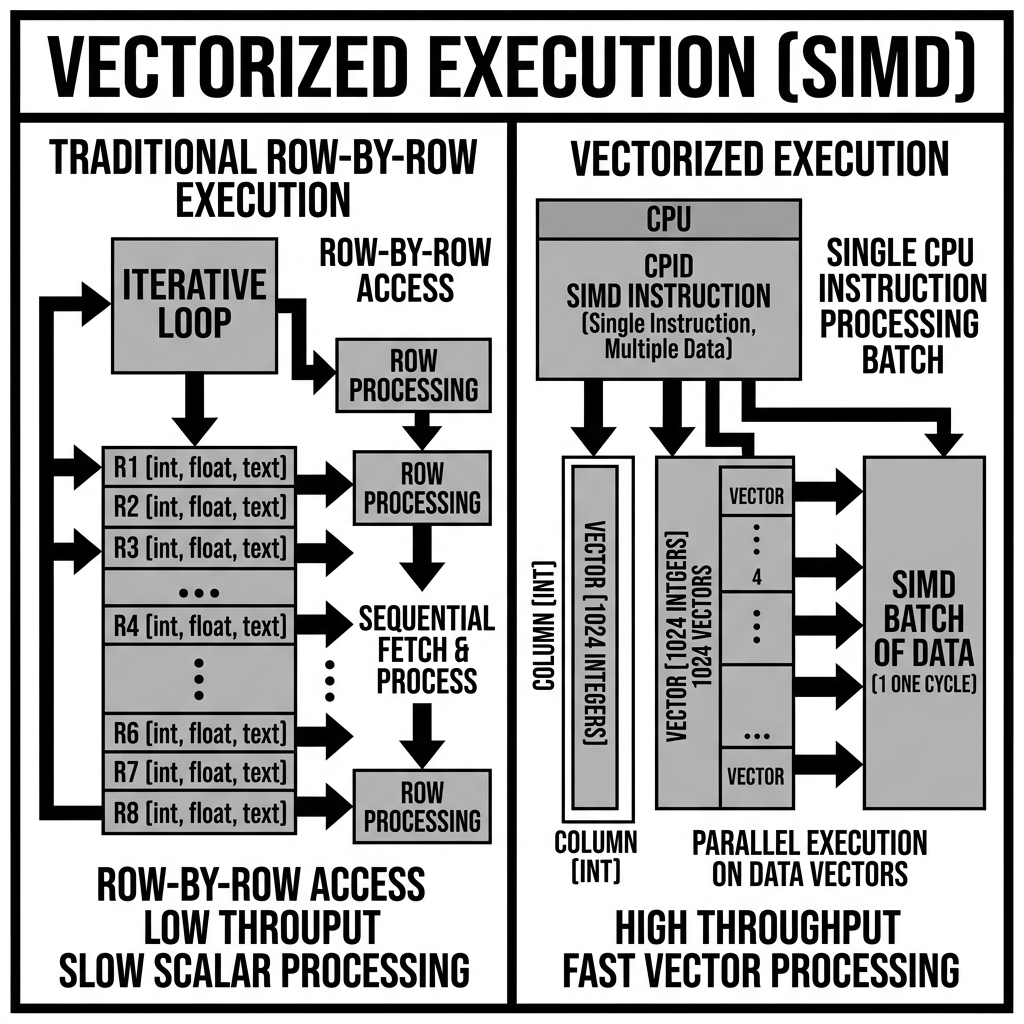
For decades, databases (like early versions of PostgreSQL, MySQL, and Apache Hive) used a row-based, tuple-at-a-time execution model. In this model, if a query requires multiplying price by quantity, the database engine pulls row 1, reads the price, reads the quantity, multiplies them, and passes the result to the next stage. It then repeats this exact process for row 2, row 3, and so on, looping millions of times.
This row-by-row approach is incredibly inefficient on modern hardware for two primary reasons:
- Virtual Function Call Overhead: The engine must constantly evaluate the data type and operation for every single row, generating massive CPU overhead simply trying to figure out how to execute the operation.
- Poor Cache Locality: Modern CPUs are fast, but main memory (RAM) is relatively slow. CPUs rely on small, ultra-fast caches (L1/L2/L3) to keep data readily available. Row-based processing constantly pulls disparate data types into the cache, leading to frequent “cache misses,” forcing the CPU to sit idle while waiting for data from RAM.
Vectorized execution flips this paradigm. It reads data in blocks or vectors (e.g., an array of 1024 integers representing the price column, and another array of 1024 integers representing the quantity column). The engine then executes a single, tightly written loop over these arrays.
Because the data in the array is of a single, uniform type and stored contiguously in memory, the CPU can load the entire array into its high-speed L1 cache. The virtual function call overhead is paid only once per block of 1024 rows, rather than 1024 times.
The Power of SIMD
The true power of vectorized execution is unlocked through SIMD (Single Instruction, Multiple Data). SIMD is a feature built into modern CPUs (like Intel’s AVX-512 or ARM’s NEON extensions) that allows the processor to perform the exact same mathematical operation on multiple data points simultaneously within a single clock cycle.
When a query engine like ClickHouse, StarRocks, or DuckDB encounters the operation price * quantity on a vectorized block, it does not loop through the 1024 items sequentially. It loads a chunk of the price array into a massive SIMD register, loads a chunk of the quantity array into another, and issues a single hardware instruction: multiply.
The CPU hardware physically multiplies 8, 16, or even 32 pairs of numbers at the exact same instant. This hardware-level parallelism results in dramatic speedups for analytical workloads, which are heavily reliant on mathematical aggregations, filtering, and transformations.
Synergy with Columnar Formats
Vectorized execution is inextricably linked to columnar storage formats like Apache Parquet and Apache Arrow.
If data is stored on disk in a row-oriented format (like CSV), assembling a contiguous array of 1024 price values requires the database to read 1024 entire rows, extract the price from each, and stitch them together in memory. The overhead of this assembly process completely negates the benefits of vectorized execution.
Columnar formats, by definition, store all values for a single column contiguously on disk. When a vectorized engine reads a Parquet file, it can copy the raw, contiguous block of price data directly from the disk (or object storage) straight into CPU memory as a vector.
This synergy is why Apache Arrow was created. Arrow is an in-memory columnar data format explicitly designed to facilitate vectorized execution. Engines and libraries that use Arrow internally can pass massive vectors of data between different systems (e.g., from a Python Pandas script to a DuckDB engine) with zero serialization overhead, maintaining the contiguous memory layout required for SIMD processing.
Summary and Tradeoffs
Vectorized execution is the hallmark of a next-generation compute engine. By abandoning the legacy row-by-row processing model and aggressively optimizing for CPU cache architecture and SIMD instruction sets, vectorized engines can process billions of rows per second on surprisingly modest hardware. It is the core technology powering the sub-second query latency demanded by modern real-time analytics platforms.
The primary tradeoff with vectorized execution is the immense engineering complexity required to build it. Writing an engine that successfully leverages SIMD instructions across different CPU architectures (Intel vs. AMD vs. ARM) requires writing highly specialized, low-level C++ or Rust code. It is significantly harder to build and maintain than a traditional Java-based row iterator.
Furthermore, vectorized execution is primarily beneficial for OLAP (Analytical) workloads that scan and aggregate massive volumes of data. For high-throughput OLTP (Transactional) workloads, where the goal is to quickly insert or update a single, complete record containing many different data types, traditional row-based processing often remains more efficient. However, in the context of the open data lakehouse, vectorized execution is an absolute necessity for achieving competitive performance.
Visual Architecture