Write-Audit-Publish (WAP)
The “silent failure” is the most dangerous event in data engineering. A pipeline succeeds, no errors are thrown, and data is written to production. However, the data itself is logically corrupted—perhaps millions of rows contain NULL values for a critical revenue column. By the time an analyst notices the discrepancy in a dashboard, the corrupted data has already infected downstream systems.
The Write-Audit-Publish (WAP) pattern is an architectural standard designed specifically to eliminate silent data corruption. Enabled by the transactional guarantees of modern table formats like Apache Iceberg, WAP treats data deployments with the same rigor as software deployments.
The Audit Phase
The core philosophy of WAP is that no user should ever query data that has not been explicitly validated.
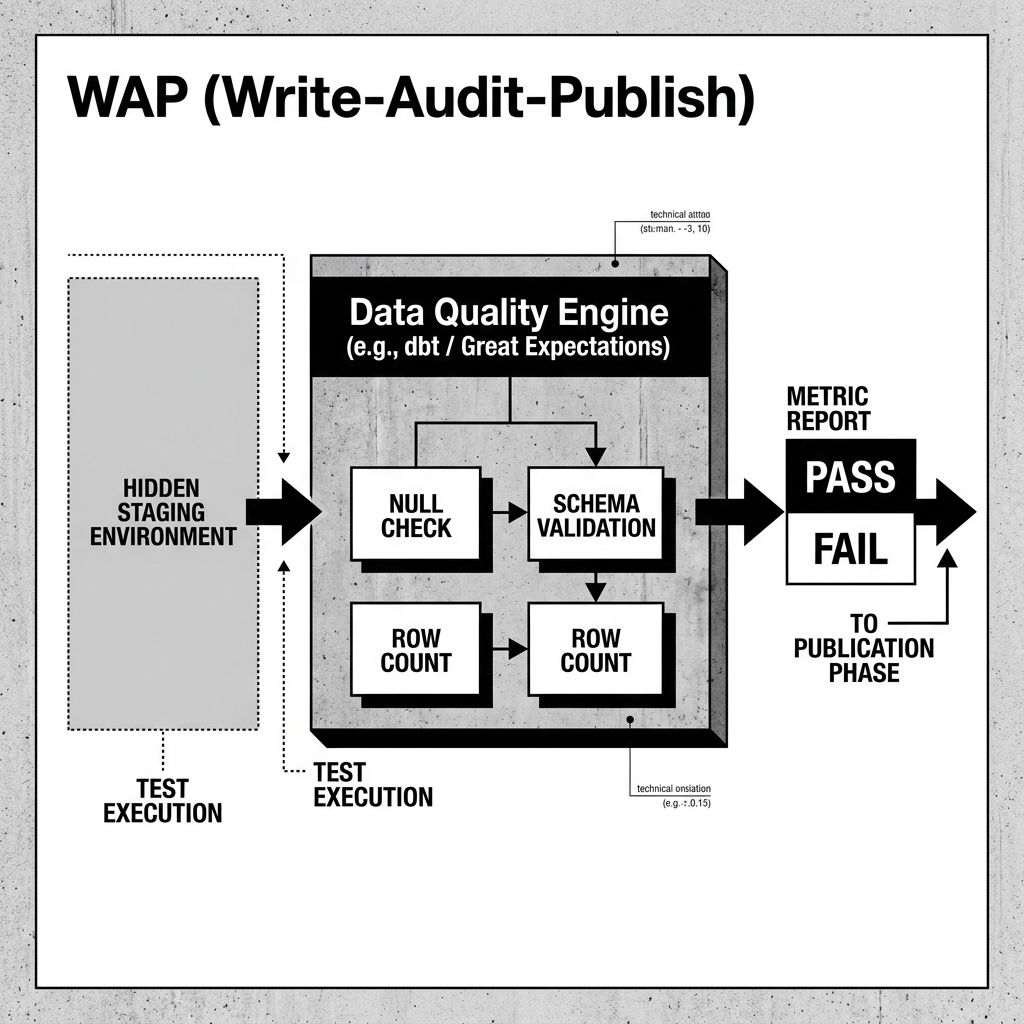
In the Write phase, an ETL pipeline writes its output to a hidden, isolated staging environment (such as an Iceberg branch). This environment is completely invisible to production end-users.
Once the write is complete, the Audit phase begins. A Data Quality engine (like dbt tests, Great Expectations, or custom SQL scripts) is executed directly against the staging environment.
These tests evaluate the physical data against strict business logic:
- Are there any
NULLvalues in thecustomer_idcolumn? - Does the total revenue for the day exceed the expected historical average by more than 20%?
- Are there exactly 24 hours of logs present?
The Data Quality engine produces a definitive Pass or Fail. If the audit fails, the pipeline halts immediately. The corrupted data remains quarantined in the staging environment, and engineers are alerted to investigate, ensuring the production tables remain perfectly clean.
Diagram 1: The Data Quality Audit
The Atomic Publish Phase
If the Audit phase returns a “Pass”, the workflow proceeds to the Publish phase.
In legacy data lakes, “publishing” often meant physically moving or copying petabytes of Parquet files from a staging directory into a production directory. This was slow, expensive, and prone to partial failures if the copy job crashed halfway through.
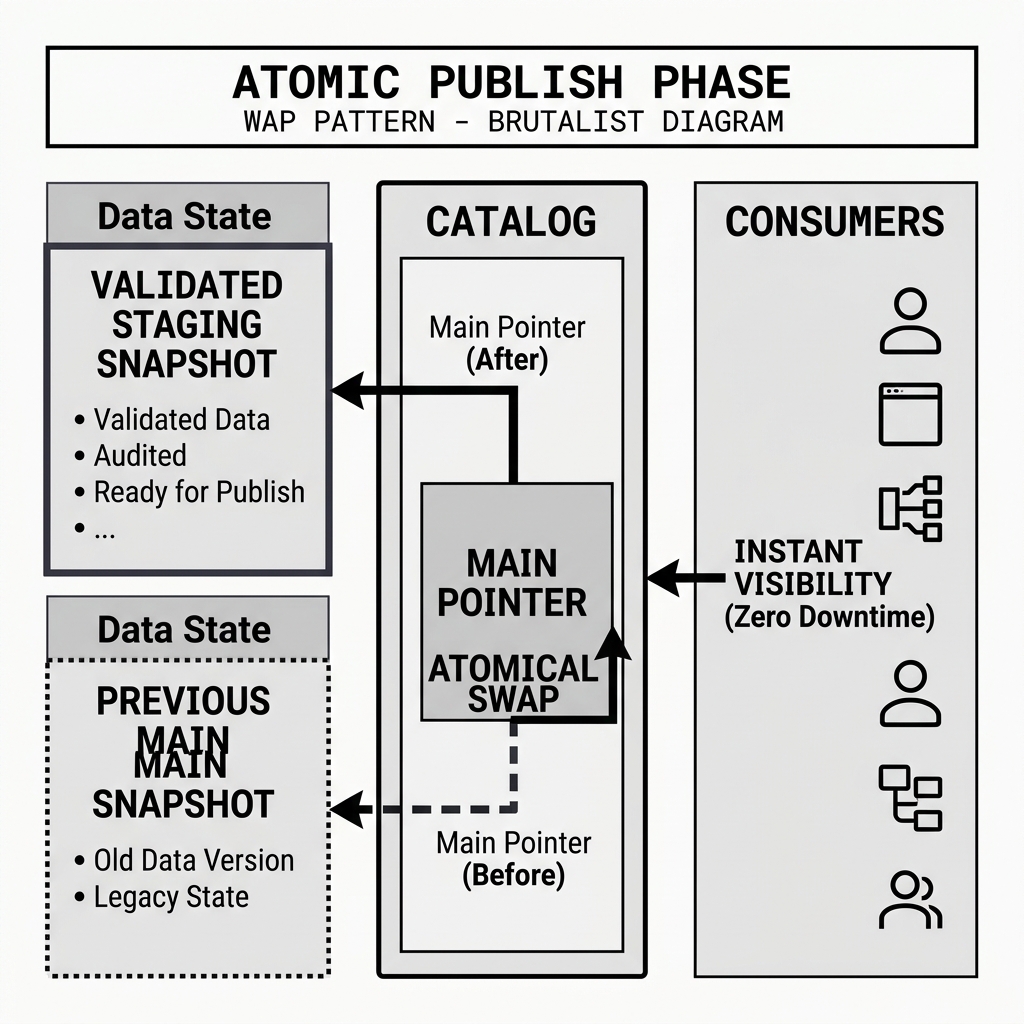
In a modern lakehouse architecture, publishing is a purely metadata-driven operation. The Data Catalog acts as the absolute gatekeeper. During the Publish phase, the Catalog performs an atomic pointer swap. It updates the main production pointer to reference the exact Snapshot ID that was just validated in the staging environment.
This swap occurs in a single, zero-downtime transaction. From the perspective of the end-user, the newly validated data simply materializes instantly, guaranteeing that every query executed against the table only ever returns fully audited, high-quality data.
Diagram 2: The Atomic Catalog Swap