Zero-ETL
Data pipelines are expensive to build and expensive to maintain. Every ETL or ELT pipeline represents a piece of code that must be written, tested, deployed, monitored, and fixed when it breaks. Pipelines break when source schemas change without warning. They fail when network timeouts occur mid-extraction. They produce incorrect results when business logic changes but the pipeline logic does not. The total cost of maintaining a large portfolio of data pipelines across an enterprise can easily run into millions of dollars per year in engineering time.
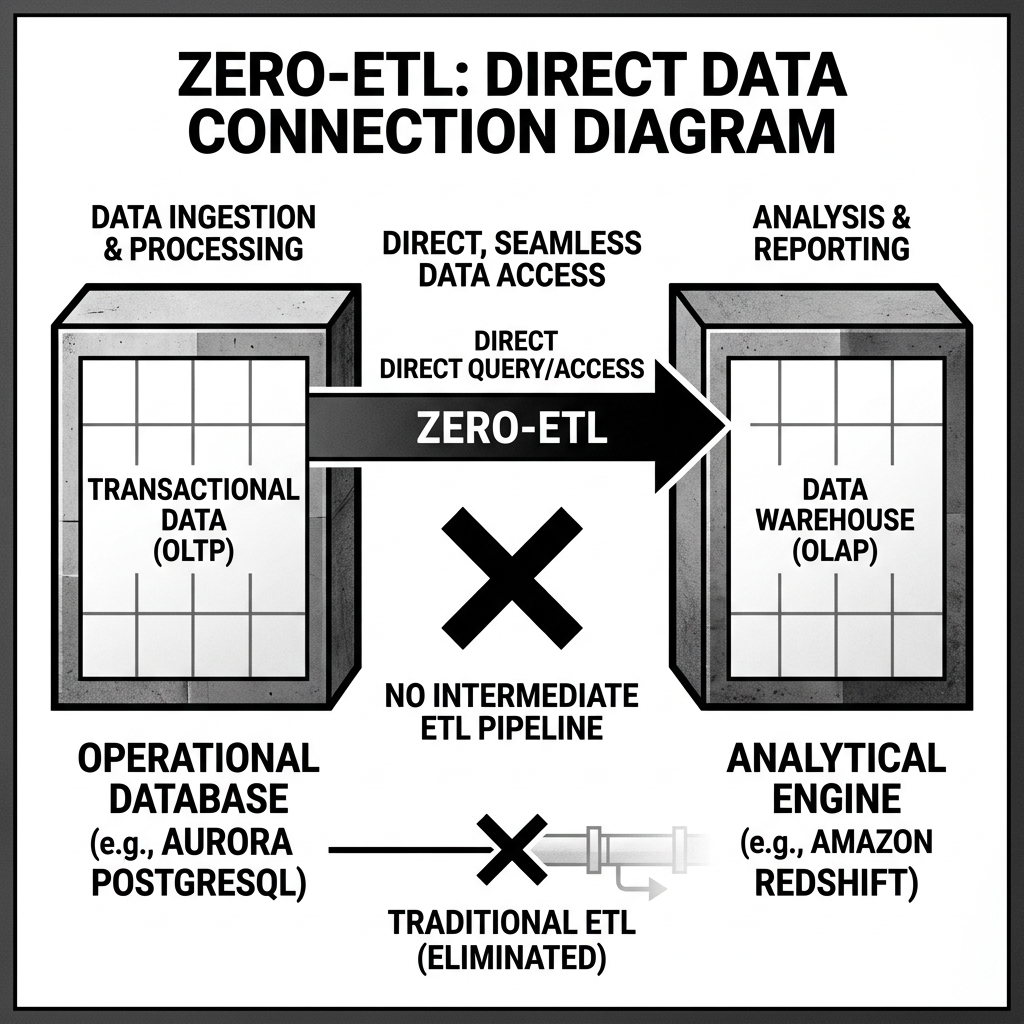
Zero-ETL is an architectural philosophy and a set of specific product capabilities that attempt to eliminate this operational burden. The core idea is straightforward: rather than building a pipeline that extracts data from a source system, transforms it in a staging environment, and loads it into a target analytical system, Zero-ETL establishes a direct, managed integration between the source and target that requires minimal or no custom engineering work to maintain.
The term gained significant momentum when Amazon Web Services introduced Zero-ETL integrations as a product feature in 2023, starting with a native integration between Aurora PostgreSQL and Amazon Redshift. This integration allowed changes in the operational Aurora database to be automatically reflected in Redshift within seconds, with no pipeline code required. AWS has since extended Zero-ETL to support additional source-target combinations, and other cloud providers have introduced similar native integration capabilities.
How Zero-ETL Works
Zero-ETL implementations vary depending on the specific technology, but they share a common architectural approach. Rather than an external agent reading from the source database and writing to the target, the source system itself participates in the data sharing process at the storage or log level.
In the AWS Aurora to Redshift implementation, the integration captures changes from Aurora’s transaction log (the binlog) and replicates them directly to Redshift. This is similar conceptually to Change Data Capture (CDC), but the key difference is that the replication mechanism is built into the platform by the cloud provider rather than implemented by the customer. There is no Debezium connector to configure, no Kafka cluster to manage, and no custom Spark streaming job to maintain. The customer simply enables the integration in the AWS console and grants the necessary permissions.
The replicated data lands in Redshift in a dedicated schema and is immediately queryable using standard SQL. The Redshift analytical engine can then run complex aggregations, joins, and window functions against this near-real-time operational data without the latency that a traditional batch ETL pipeline would introduce.
Diagram 1: Zero-ETL Architecture
Zero-ETL in the Context of Open Lakehouses
The Zero-ETL concept has also manifested differently in the context of open data lakehouses built on Apache Iceberg. Cloud providers and database vendors have begun offering Iceberg-native integrations that allow operational databases to write directly to Iceberg tables in object storage, bypassing traditional pipelines entirely.
Amazon Aurora Optimized Reads allows Aurora to directly query Iceberg tables in S3 without replication. Snowflake’s open catalog features allow external systems to read and write Iceberg tables registered in Snowflake’s catalog. These capabilities allow a broader ecosystem of tools to participate in what might be called a “federated Zero-ETL” model, where data is shared at the table format level rather than replicated at the database level.
This open, Iceberg-based approach to Zero-ETL is significantly more flexible than proprietary cloud-specific integrations. Because Iceberg is an open standard, any engine that supports the Iceberg spec can participate as either a reader or a writer. A Flink streaming job can write directly to an Iceberg table, and Dremio, Spark, Trino, and BigQuery can all read that same table simultaneously. The “ETL” step of moving data between these systems is replaced by a shared, open storage layer that all of them can access natively.
Diagram 2: Zero-ETL vs Traditional ETL Tradeoffs
The Tradeoffs and Limitations of Zero-ETL
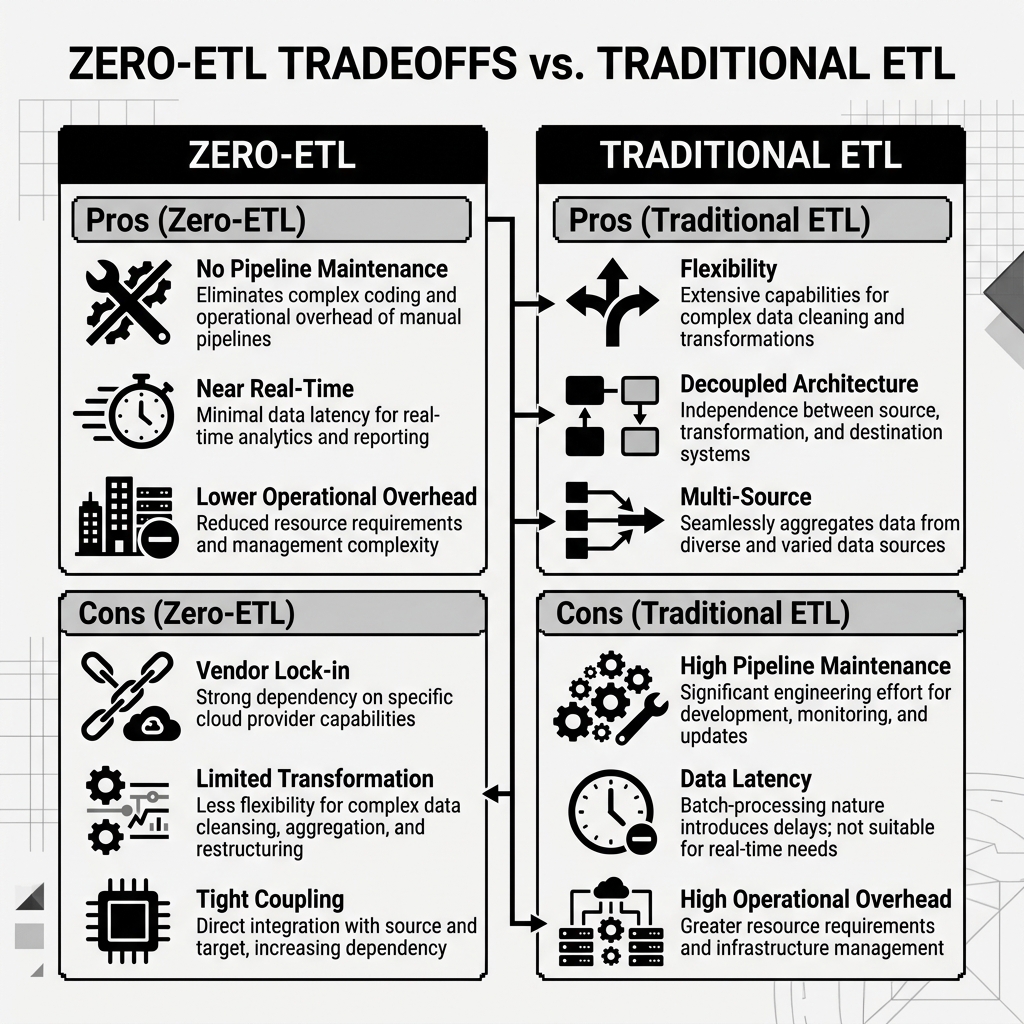
Zero-ETL is not a universal solution to the data integration problem, and organizations that adopt it without understanding its limitations often run into significant architectural challenges.
Vendor lock-in is the most significant concern. Proprietary Zero-ETL integrations, like AWS Aurora to Redshift, work only within a specific cloud provider’s ecosystem. If an organization builds its entire analytical platform around a proprietary Zero-ETL integration and later needs to migrate to a different platform, that integration must be replaced with a traditional pipeline. For organizations committed to open, vendor-neutral architectures, proprietary Zero-ETL integrations are a difficult fit.
Limited transformation capability is an inherent constraint. Because Zero-ETL moves data from source to target without a transformation step, any business logic that must be applied to the data before it can be used analytically must be applied after the data arrives in the target system. If the source database has messy, inconsistent data, that messiness lands directly in the analytical layer. Zero-ETL works best when the source data is already relatively clean, or when the target system is powerful enough to handle the transformation work via SQL views or materialized aggregations.
Schema coupling is a subtler problem. When a Zero-ETL integration directly replicates a source database schema to an analytical target, any change to the source schema, such as renaming a column or changing a data type, immediately propagates to the target and can break downstream reports and dashboards. Traditional ETL pipelines provide a layer of insulation: the pipeline’s transformation logic absorbs schema changes and presents a stable interface to downstream consumers.
Zero-ETL is most effective as a complement to, rather than a replacement for, thoughtful data architecture. For simple, low-volume, time-sensitive use cases where operational data needs to be immediately available for analysis, Zero-ETL dramatically reduces engineering effort. For complex, multi-source analytical workloads with significant transformation requirements, traditional or ELT-based pipelines remain necessary.