Zstandard (Zstd)
Core Definition
Zstandard, commonly abbreviated as Zstd, is a fast, lossless data compression algorithm developed by Yann Collet at Facebook (Meta). Introduced in 2015, Zstd represents a massive generational leap in compression technology. For decades, data engineers had to make a painful choice: use GZIP for good compression but terrible speed, or use Snappy/LZ4 for blistering speed but mediocre compression. Zstd effectively shatters this dichotomy, offering compression ratios comparable to (or better than) GZIP, while delivering decompression speeds closer to Snappy.
As a result, Zstandard is rapidly becoming the new gold standard for big data storage, increasingly replacing Snappy as the preferred default codec for open table formats and analytical engines.
Diagram 1: Conceptual Architecture
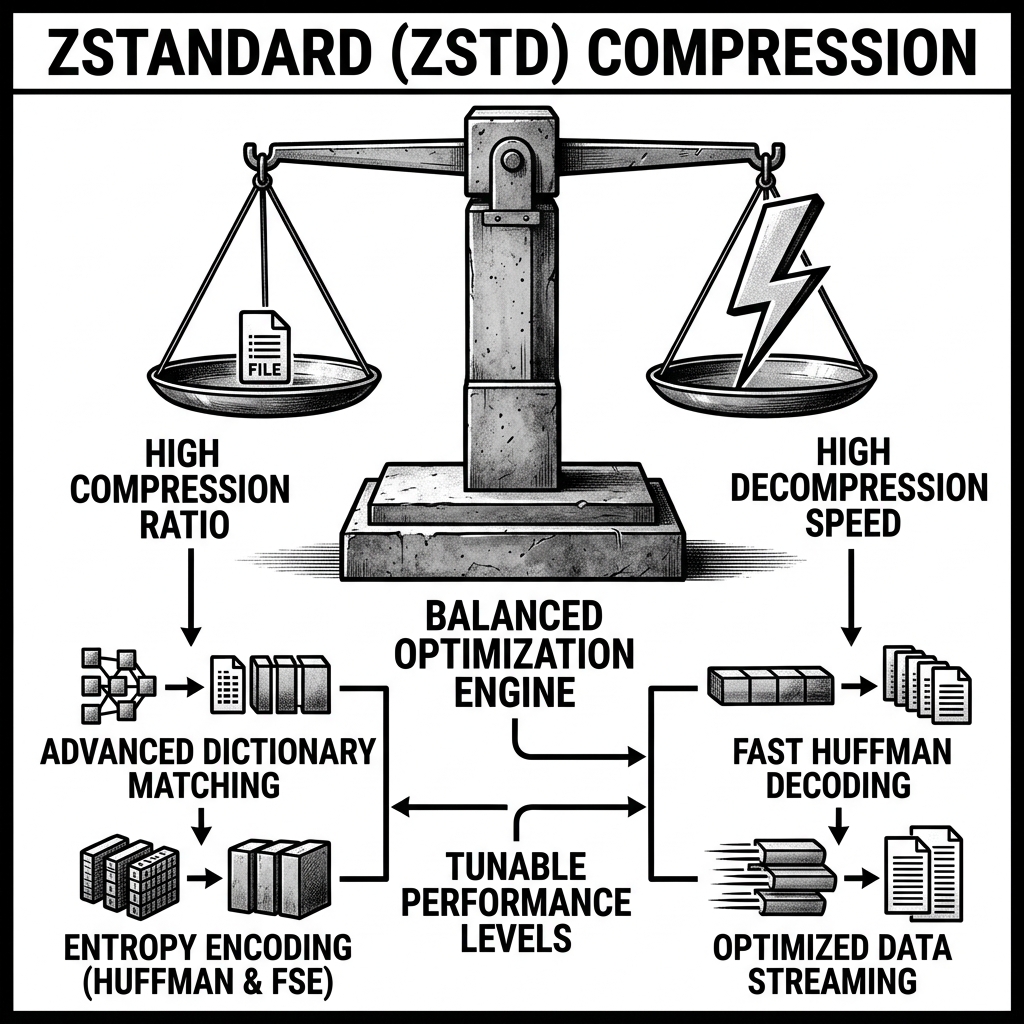
Implementation and Operations
The magic of Zstd lies in its highly tunable architecture and its use of Finite State Entropy (FSE) coding.
Unlike older algorithms that have a narrow operating window, Zstd offers a vast range of compression levels (from 1 to 22, plus negative levels for extreme speed).
- At lower levels (e.g., Level 1), Zstd acts like Snappy: it compresses and decompresses at gigabytes per second, making it perfect for real-time streaming pipelines (like Apache Kafka).
- At standard levels (e.g., Level 3), it offers the perfect “Lakehouse” balance: file sizes significantly smaller than Snappy, but with decompression speeds that do not bottleneck query engines like Trino or StarRocks.
- At maximum levels (Level 22), it achieves archival-grade compression, crushing data into the smallest possible footprint for long-term cold storage.
Another groundbreaking feature of Zstd is its support for Dictionary Compression. When compressing many small, similar files (like millions of small JSON log messages), standard algorithms struggle because they don’t have enough data in a single file to build a good compression map. Zstd allows engineers to pre-train a “dictionary” on sample data. This dictionary is then shared across all files, resulting in massive compression gains on micro-files.
Diagram 2: Operational Flow
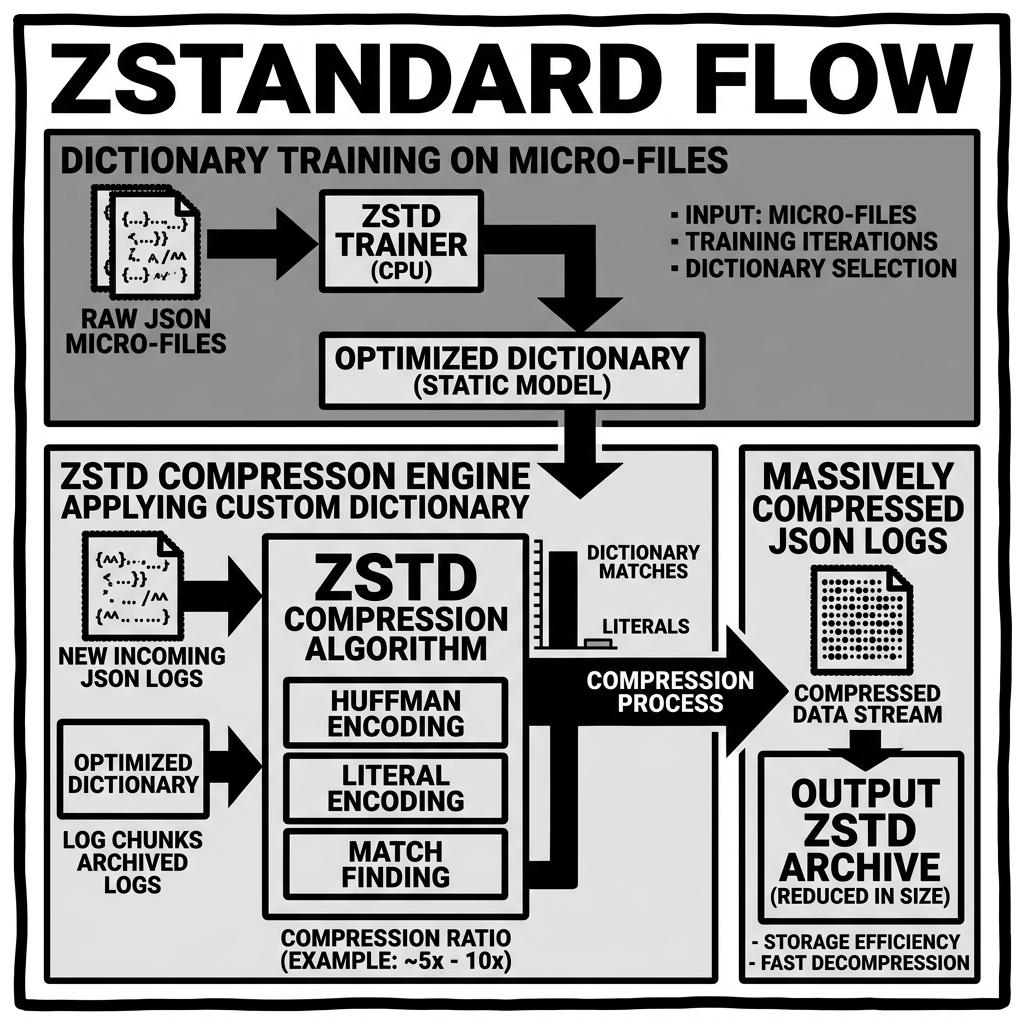
Summary and Tradeoffs
Zstandard is currently the ultimate “no-compromise” compression algorithm for the open data lakehouse. By migrating from Snappy to Zstd, organizations often see a 20-30% reduction in their total Amazon S3 storage bills and faster network transfer times, without suffering any noticeable CPU penalty during query execution. The only real tradeoff is that because it is newer, very legacy data systems might lack native libraries for Zstd, requiring minor infrastructure updates. However, in the modern stack (Iceberg, Delta, Spark, Trino), Zstd is natively and heavily supported.
Extended Deep Dive: The Data Engineering Ecosystem
To truly understand this concept, it must be placed within the broader context of the modern data engineering ecosystem. The evolution from traditional, monolithic on-premises data warehouses to decoupled, cloud-native open data lakehouses represents one of the most significant paradigm shifts in software architecture over the last two decades.
The Problem with Legacy Data Warehouses
Historically, organizations relied on proprietary appliances from vendors like Teradata, Oracle, or IBM. These systems were characterized by a tight coupling of compute and storage. The data physically resided on the hard drives of the specific servers that executed the SQL queries. While incredibly fast for structured, relational data, this architecture suffered from fatal scalability flaws. If an organization needed more storage for historical logs, they were forced to purchase expensive, proprietary servers that included compute power they did not actually need. Furthermore, these systems struggled to ingest unstructured data (like raw JSON, images, or massive IoT streams), creating impenetrable data silos.
The Rise and Fall of the Data Lake (Hadoop)
To solve the volume and variety problem, the industry pivoted to the Data Lake, pioneered by Apache Hadoop. Organizations began dumping all raw data—structured, semi-structured, and unstructured—into the Hadoop Distributed File System (HDFS). Because HDFS ran on cheap commodity hardware, storage became essentially free. However, the data lake lacked the basic governance, transactional guarantees, and performance optimization of the data warehouse. Without ACID (Atomicity, Consistency, Isolation, Durability) transactions, concurrent reads and writes frequently corrupted data. Without schema enforcement, the data lake quickly devolved into an unmanageable, unqueryable “data swamp.”
The Open Data Lakehouse Paradigm
The open data lakehouse merges the best of both worlds. It utilizes the infinitely scalable, low-cost storage of the cloud (like Amazon S3 or Google Cloud Storage) but overlays the management and performance features of a traditional data warehouse.
This is achieved through a multi-layered architecture:
- The Storage Layer: Cloud object storage provides the infinite hard drive.
- The File Format Layer: Open columnar formats like Apache Parquet and ORC provide extreme compression and analytical read efficiency.
- The Table Format Layer: Technologies like Apache Iceberg, Delta Lake, and Apache Hudi sit on top of the physical files. They provide the metadata layer that enables ACID transactions, schema evolution, and time travel, bringing warehouse-level reliability to the raw object storage.
- The Compute Layer: Decoupled, highly elastic engines like Trino, Dremio, Apache Spark, and Snowflake sit at the top. They can be scaled up or down independently of the storage, providing massive parallel processing power only when queries are actively running.
Performance Optimization Strategies
In this decoupled architecture, network bandwidth between the compute engine and the object storage is the primary bottleneck. Data engineers employ a variety of advanced strategies to minimize this I/O:
- Partitioning: Organizing data into distinct directories based on a frequently queried column (e.g., separating data by
year/month/day). When an analyst queries a specific date, the engine simply ignores all directories that do not match, massively reducing data reads. - Z-Ordering and Space-Filling Curves: Advanced sorting techniques that cluster multi-dimensional data physically close together on the disk. This dramatically improves the effectiveness of file-skipping statistics (Min/Max filtering) in formats like Iceberg, allowing engines to read highly targeted, microscopic subsets of massive tables.
- Compaction: Over time, streaming ingestions create millions of tiny, inefficient files. Data engineers run scheduled compaction jobs (often utilizing bin-packing algorithms) to merge these tiny files into optimally sized, large columnar blocks (typically 128MB to 512MB), restoring query performance and reducing S3 API overhead.
Security and Governance
As data is democratized across the enterprise, governance becomes paramount. The open lakehouse relies on centralized metadata catalogs (like AWS Glue, Apache Polaris, or Unity Catalog) to manage access. Fine-Grained Access Control (FGAC) allows administrators to mask specific columns (like Social Security Numbers) or restrict specific rows based on the user’s role, ensuring that a single, unified dataset can be securely queried by marketing, finance, and engineering teams simultaneously without violating compliance regulations like GDPR or CCPA.
Conclusion
The architecture described above is not static. The industry is rapidly moving toward real-time streaming ingestion, automated “agentic” data modeling, and universal cross-engine compatibility via projects like Apache XTable. Understanding the foundational layers—how data is serialized, compressed, stored, and transported—is the absolute prerequisite for architecting systems that can handle the exabyte-scale analytics demands of the future.
Extended Deep Dive: The Data Engineering Ecosystem
To truly understand this concept, it must be placed within the broader context of the modern data engineering ecosystem. The evolution from traditional, monolithic on-premises data warehouses to decoupled, cloud-native open data lakehouses represents one of the most significant paradigm shifts in software architecture over the last two decades.
The Problem with Legacy Data Warehouses
Historically, organizations relied on proprietary appliances from vendors like Teradata, Oracle, or IBM. These systems were characterized by a tight coupling of compute and storage. The data physically resided on the hard drives of the specific servers that executed the SQL queries. While incredibly fast for structured, relational data, this architecture suffered from fatal scalability flaws. If an organization needed more storage for historical logs, they were forced to purchase expensive, proprietary servers that included compute power they did not actually need. Furthermore, these systems struggled to ingest unstructured data (like raw JSON, images, or massive IoT streams), creating impenetrable data silos.
The Rise and Fall of the Data Lake (Hadoop)
To solve the volume and variety problem, the industry pivoted to the Data Lake, pioneered by Apache Hadoop. Organizations began dumping all raw data—structured, semi-structured, and unstructured—into the Hadoop Distributed File System (HDFS). Because HDFS ran on cheap commodity hardware, storage became essentially free. However, the data lake lacked the basic governance, transactional guarantees, and performance optimization of the data warehouse. Without ACID (Atomicity, Consistency, Isolation, Durability) transactions, concurrent reads and writes frequently corrupted data. Without schema enforcement, the data lake quickly devolved into an unmanageable, unqueryable “data swamp.”
The Open Data Lakehouse Paradigm
The open data lakehouse merges the best of both worlds. It utilizes the infinitely scalable, low-cost storage of the cloud (like Amazon S3 or Google Cloud Storage) but overlays the management and performance features of a traditional data warehouse.
This is achieved through a multi-layered architecture:
- The Storage Layer: Cloud object storage provides the infinite hard drive.
- The File Format Layer: Open columnar formats like Apache Parquet and ORC provide extreme compression and analytical read efficiency.
- The Table Format Layer: Technologies like Apache Iceberg, Delta Lake, and Apache Hudi sit on top of the physical files. They provide the metadata layer that enables ACID transactions, schema evolution, and time travel, bringing warehouse-level reliability to the raw object storage.
- The Compute Layer: Decoupled, highly elastic engines like Trino, Dremio, Apache Spark, and Snowflake sit at the top. They can be scaled up or down independently of the storage, providing massive parallel processing power only when queries are actively running.
Performance Optimization Strategies
In this decoupled architecture, network bandwidth between the compute engine and the object storage is the primary bottleneck. Data engineers employ a variety of advanced strategies to minimize this I/O:
- Partitioning: Organizing data into distinct directories based on a frequently queried column (e.g., separating data by
year/month/day). When an analyst queries a specific date, the engine simply ignores all directories that do not match, massively reducing data reads. - Z-Ordering and Space-Filling Curves: Advanced sorting techniques that cluster multi-dimensional data physically close together on the disk. This dramatically improves the effectiveness of file-skipping statistics (Min/Max filtering) in formats like Iceberg, allowing engines to read highly targeted, microscopic subsets of massive tables.
- Compaction: Over time, streaming ingestions create millions of tiny, inefficient files. Data engineers run scheduled compaction jobs (often utilizing bin-packing algorithms) to merge these tiny files into optimally sized, large columnar blocks (typically 128MB to 512MB), restoring query performance and reducing S3 API overhead.
Security and Governance
As data is democratized across the enterprise, governance becomes paramount. The open lakehouse relies on centralized metadata catalogs (like AWS Glue, Apache Polaris, or Unity Catalog) to manage access. Fine-Grained Access Control (FGAC) allows administrators to mask specific columns (like Social Security Numbers) or restrict specific rows based on the user’s role, ensuring that a single, unified dataset can be securely queried by marketing, finance, and engineering teams simultaneously without violating compliance regulations like GDPR or CCPA.
Conclusion
The architecture described above is not static. The industry is rapidly moving toward real-time streaming ingestion, automated “agentic” data modeling, and universal cross-engine compatibility via projects like Apache XTable. Understanding the foundational layers—how data is serialized, compressed, stored, and transported—is the absolute prerequisite for architecting systems that can handle the exabyte-scale analytics demands of the future.
Extended Deep Dive: The Data Engineering Ecosystem
To truly understand this concept, it must be placed within the broader context of the modern data engineering ecosystem. The evolution from traditional, monolithic on-premises data warehouses to decoupled, cloud-native open data lakehouses represents one of the most significant paradigm shifts in software architecture over the last two decades.
The Problem with Legacy Data Warehouses
Historically, organizations relied on proprietary appliances from vendors like Teradata, Oracle, or IBM. These systems were characterized by a tight coupling of compute and storage. The data physically resided on the hard drives of the specific servers that executed the SQL queries. While incredibly fast for structured, relational data, this architecture suffered from fatal scalability flaws. If an organization needed more storage for historical logs, they were forced to purchase expensive, proprietary servers that included compute power they did not actually need. Furthermore, these systems struggled to ingest unstructured data (like raw JSON, images, or massive IoT streams), creating impenetrable data silos.
The Rise and Fall of the Data Lake (Hadoop)
To solve the volume and variety problem, the industry pivoted to the Data Lake, pioneered by Apache Hadoop. Organizations began dumping all raw data—structured, semi-structured, and unstructured—into the Hadoop Distributed File System (HDFS). Because HDFS ran on cheap commodity hardware, storage became essentially free. However, the data lake lacked the basic governance, transactional guarantees, and performance optimization of the data warehouse. Without ACID (Atomicity, Consistency, Isolation, Durability) transactions, concurrent reads and writes frequently corrupted data. Without schema enforcement, the data lake quickly devolved into an unmanageable, unqueryable “data swamp.”
The Open Data Lakehouse Paradigm
The open data lakehouse merges the best of both worlds. It utilizes the infinitely scalable, low-cost storage of the cloud (like Amazon S3 or Google Cloud Storage) but overlays the management and performance features of a traditional data warehouse.
This is achieved through a multi-layered architecture:
- The Storage Layer: Cloud object storage provides the infinite hard drive.
- The File Format Layer: Open columnar formats like Apache Parquet and ORC provide extreme compression and analytical read efficiency.
- The Table Format Layer: Technologies like Apache Iceberg, Delta Lake, and Apache Hudi sit on top of the physical files. They provide the metadata layer that enables ACID transactions, schema evolution, and time travel, bringing warehouse-level reliability to the raw object storage.
- The Compute Layer: Decoupled, highly elastic engines like Trino, Dremio, Apache Spark, and Snowflake sit at the top. They can be scaled up or down independently of the storage, providing massive parallel processing power only when queries are actively running.
Performance Optimization Strategies
In this decoupled architecture, network bandwidth between the compute engine and the object storage is the primary bottleneck. Data engineers employ a variety of advanced strategies to minimize this I/O:
- Partitioning: Organizing data into distinct directories based on a frequently queried column (e.g., separating data by
year/month/day). When an analyst queries a specific date, the engine simply ignores all directories that do not match, massively reducing data reads. - Z-Ordering and Space-Filling Curves: Advanced sorting techniques that cluster multi-dimensional data physically close together on the disk. This dramatically improves the effectiveness of file-skipping statistics (Min/Max filtering) in formats like Iceberg, allowing engines to read highly targeted, microscopic subsets of massive tables.
- Compaction: Over time, streaming ingestions create millions of tiny, inefficient files. Data engineers run scheduled compaction jobs (often utilizing bin-packing algorithms) to merge these tiny files into optimally sized, large columnar blocks (typically 128MB to 512MB), restoring query performance and reducing S3 API overhead.
Security and Governance
As data is democratized across the enterprise, governance becomes paramount. The open lakehouse relies on centralized metadata catalogs (like AWS Glue, Apache Polaris, or Unity Catalog) to manage access. Fine-Grained Access Control (FGAC) allows administrators to mask specific columns (like Social Security Numbers) or restrict specific rows based on the user’s role, ensuring that a single, unified dataset can be securely queried by marketing, finance, and engineering teams simultaneously without violating compliance regulations like GDPR or CCPA.
Conclusion
The architecture described above is not static. The industry is rapidly moving toward real-time streaming ingestion, automated “agentic” data modeling, and universal cross-engine compatibility via projects like Apache XTable. Understanding the foundational layers—how data is serialized, compressed, stored, and transported—is the absolute prerequisite for architecting systems that can handle the exabyte-scale analytics demands of the future.
Extended Deep Dive: The Data Engineering Ecosystem
To truly understand this concept, it must be placed within the broader context of the modern data engineering ecosystem. The evolution from traditional, monolithic on-premises data warehouses to decoupled, cloud-native open data lakehouses represents one of the most significant paradigm shifts in software architecture over the last two decades.
The Problem with Legacy Data Warehouses
Historically, organizations relied on proprietary appliances from vendors like Teradata, Oracle, or IBM. These systems were characterized by a tight coupling of compute and storage. The data physically resided on the hard drives of the specific servers that executed the SQL queries. While incredibly fast for structured, relational data, this architecture suffered from fatal scalability flaws. If an organization needed more storage for historical logs, they were forced to purchase expensive, proprietary servers that included compute power they did not actually need. Furthermore, these systems struggled to ingest unstructured data (like raw JSON, images, or massive IoT streams), creating impenetrable data silos.
The Rise and Fall of the Data Lake (Hadoop)
To solve the volume and variety problem, the industry pivoted to the Data Lake, pioneered by Apache Hadoop. Organizations began dumping all raw data—structured, semi-structured, and unstructured—into the Hadoop Distributed File System (HDFS). Because HDFS ran on cheap commodity hardware, storage became essentially free. However, the data lake lacked the basic governance, transactional guarantees, and performance optimization of the data warehouse. Without ACID (Atomicity, Consistency, Isolation, Durability) transactions, concurrent reads and writes frequently corrupted data. Without schema enforcement, the data lake quickly devolved into an unmanageable, unqueryable “data swamp.”
The Open Data Lakehouse Paradigm
The open data lakehouse merges the best of both worlds. It utilizes the infinitely scalable, low-cost storage of the cloud (like Amazon S3 or Google Cloud Storage) but overlays the management and performance features of a traditional data warehouse.
This is achieved through a multi-layered architecture:
- The Storage Layer: Cloud object storage provides the infinite hard drive.
- The File Format Layer: Open columnar formats like Apache Parquet and ORC provide extreme compression and analytical read efficiency.
- The Table Format Layer: Technologies like Apache Iceberg, Delta Lake, and Apache Hudi sit on top of the physical files. They provide the metadata layer that enables ACID transactions, schema evolution, and time travel, bringing warehouse-level reliability to the raw object storage.
- The Compute Layer: Decoupled, highly elastic engines like Trino, Dremio, Apache Spark, and Snowflake sit at the top. They can be scaled up or down independently of the storage, providing massive parallel processing power only when queries are actively running.
Performance Optimization Strategies
In this decoupled architecture, network bandwidth between the compute engine and the object storage is the primary bottleneck. Data engineers employ a variety of advanced strategies to minimize this I/O:
- Partitioning: Organizing data into distinct directories based on a frequently queried column (e.g., separating data by
year/month/day). When an analyst queries a specific date, the engine simply ignores all directories that do not match, massively reducing data reads. - Z-Ordering and Space-Filling Curves: Advanced sorting techniques that cluster multi-dimensional data physically close together on the disk. This dramatically improves the effectiveness of file-skipping statistics (Min/Max filtering) in formats like Iceberg, allowing engines to read highly targeted, microscopic subsets of massive tables.
- Compaction: Over time, streaming ingestions create millions of tiny, inefficient files. Data engineers run scheduled compaction jobs (often utilizing bin-packing algorithms) to merge these tiny files into optimally sized, large columnar blocks (typically 128MB to 512MB), restoring query performance and reducing S3 API overhead.
Security and Governance
As data is democratized across the enterprise, governance becomes paramount. The open lakehouse relies on centralized metadata catalogs (like AWS Glue, Apache Polaris, or Unity Catalog) to manage access. Fine-Grained Access Control (FGAC) allows administrators to mask specific columns (like Social Security Numbers) or restrict specific rows based on the user’s role, ensuring that a single, unified dataset can be securely queried by marketing, finance, and engineering teams simultaneously without violating compliance regulations like GDPR or CCPA.
Conclusion
The architecture described above is not static. The industry is rapidly moving toward real-time streaming ingestion, automated “agentic” data modeling, and universal cross-engine compatibility via projects like Apache XTable. Understanding the foundational layers—how data is serialized, compressed, stored, and transported—is the absolute prerequisite for architecting systems that can handle the exabyte-scale analytics demands of the future.
Visual Architecture