The Metadata Structure of Modern Table Formats

Read the complete Apache Iceberg Masterclass series:
- Part 1: What Are Table Formats and Why Were They Needed?
- Part 2: The Metadata Structure of Modern Table Formats
- Part 3: Performance and Apache Iceberg’s Metadata
- Part 4: Partition Evolution: Change Your Partitioning Without Rewriting Data
- Part 5: Hidden Partitioning: How Iceberg Eliminates Accidental Full Table Scans
- Part 6: Writing to an Apache Iceberg Table: How Commits and ACID Actually Work
- Part 7: What Are Lakehouse Catalogs? The Role of Catalogs in Apache Iceberg
- Part 8: When Catalogs Are Embedded in Storage
- Part 9: How Data Lake Table Storage Degrades Over Time
- Part 10: Maintaining Apache Iceberg Tables: Compaction, Expiry, and Cleanup
- Part 11: Apache Iceberg Metadata Tables: Querying the Internals
- Part 12: Using Apache Iceberg with Python and MPP Query Engines
- Part 13: Approaches to Streaming Data into Apache Iceberg Tables
- Part 14: Hands-On with Apache Iceberg Using Dremio Cloud
- Part 15: Migrating to Apache Iceberg: Strategies for Every Source System This is Part 2 of a 15-part Apache Iceberg Masterclass. Part 1 covered why table formats exist. This article breaks down exactly how each format organizes its metadata.
The metadata structure of a table format determines everything: how fast queries start planning, how efficiently concurrent writes are handled, how schema changes propagate, and how much overhead accumulates over time. Two formats can both claim “ACID support” and “time travel” while having fundamentally different mechanisms under the hood.
Apache Iceberg: The Metadata Tree
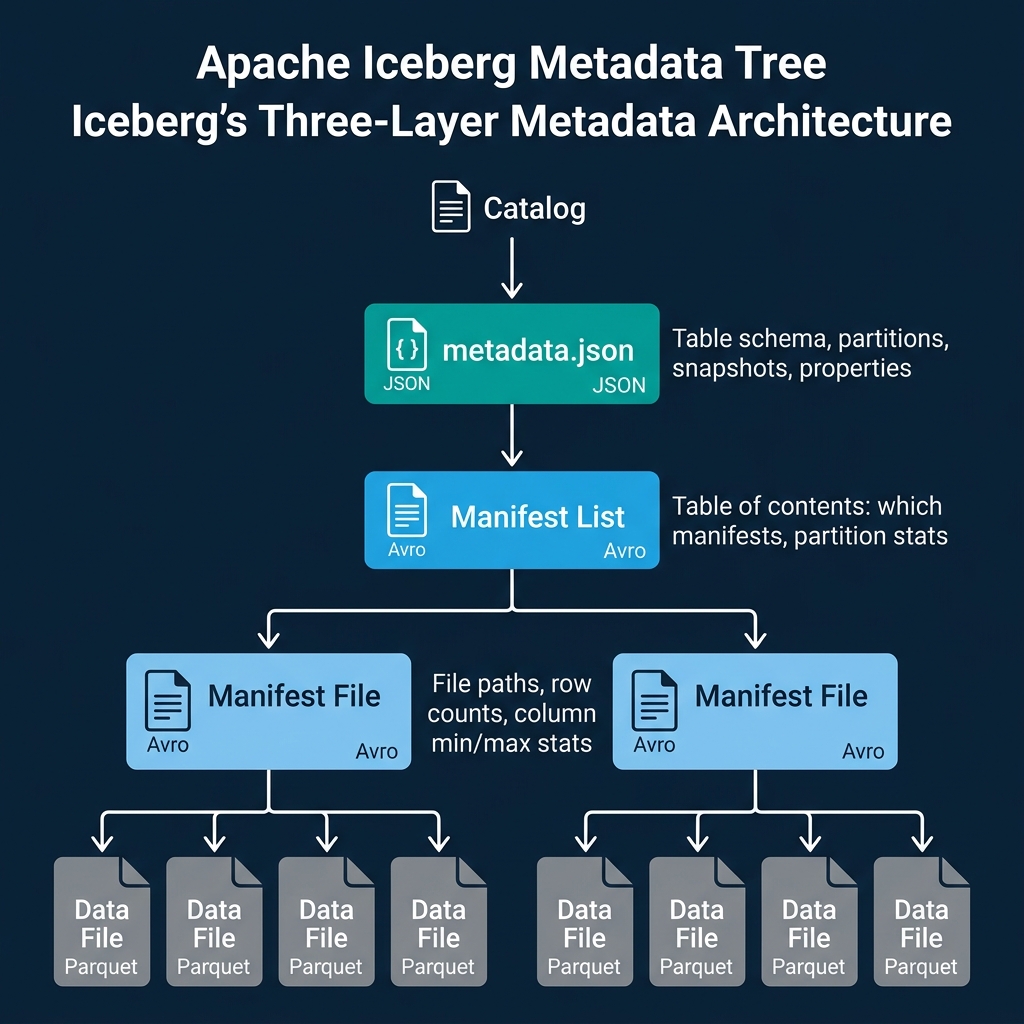
Iceberg organizes metadata into a tree with four levels. Each level adds specificity and enables pruning at query planning time.
Level 1: Catalog pointer. The catalog (a REST catalog, Dremio Open Catalog, AWS Glue, or Hive Metastore) stores a pointer to the current metadata.json file. This pointer is the single source of truth for the table’s current state.
Level 2: Metadata file (metadata.json). A JSON file containing the table’s schema (with column IDs), partition spec, sort order, table properties, and a list of snapshots. Each snapshot represents a complete, immutable version of the table. When the table is updated, a new metadata.json is created with the new snapshot appended to the list.
Level 3: Manifest list (Avro). Each snapshot points to exactly one manifest list. The manifest list is a table of contents: it lists all the manifest files that make up this snapshot and includes partition-level summary statistics for each manifest. These summaries let the query planner skip entire manifests that cannot contain data matching the query filter.
Level 4: Manifest files (Avro). Each manifest file tracks a set of data files and delete files. For each file, the manifest stores the file path, file size, row count, partition values, and column-level statistics (min value, max value, null count, NaN count, distinct count). These per-file statistics enable file-level pruning during query planning.
The key insight is that each level progressively narrows the search space. A query engine using Dremio or Spark reads the catalog pointer (1 request), loads the metadata file (1 read), checks the manifest list to skip irrelevant manifests (1 read, many skips), then reads only the relevant manifests to find the actual data files to scan. For a petabyte table, this can reduce planning from minutes of directory listing to milliseconds of metadata traversal.
Delta Lake: The Sequential Transaction Log
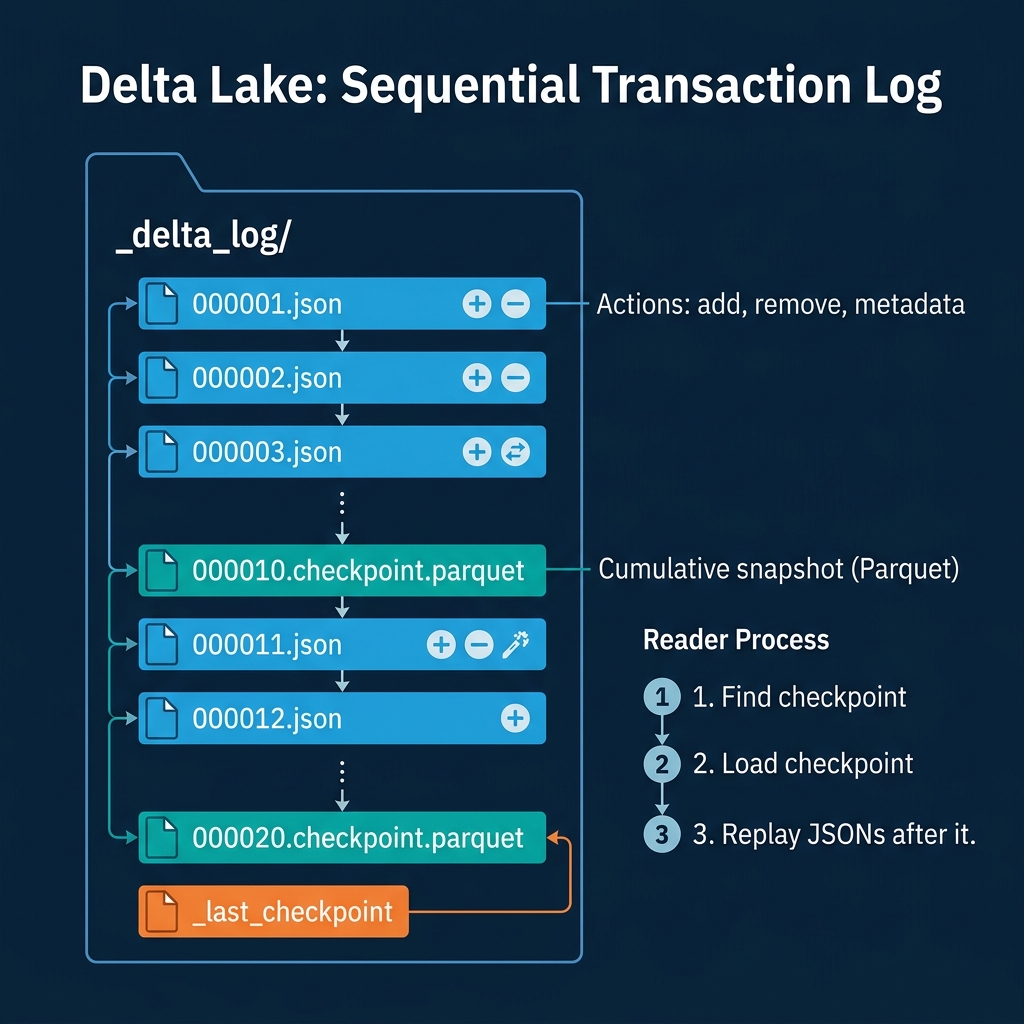
Delta Lake uses a simpler, linear structure. All metadata lives in the _delta_log/ directory alongside the data.
JSON commit files (000001.json, 000002.json, …) record each transaction as a set of actions: add (a new data file), remove (a file marked for deletion), metaData (schema or property change), and protocol (version requirements). Each commit file is sequentially numbered.
Parquet checkpoint files are created every 10 commits (by default). A checkpoint is a Parquet file that summarizes the cumulative state of the table at that version, essentially a snapshot of all currently-active add actions. This prevents readers from having to replay hundreds of small JSON files.
_last_checkpoint is a small file pointing to the most recent checkpoint. The read process is: find the latest checkpoint, load it, then replay any JSON commits after it.
The tradeoff: Delta’s log is simple and easy to reason about, but it does not have the multi-level pruning that Iceberg’s manifest tree provides. File-level statistics exist in the add actions but are not organized hierarchically. For very large tables (millions of files), the planning phase can be slower because there is no intermediate pruning layer equivalent to Iceberg’s manifest list.
Apache Hudi: The Timeline
Hudi stores metadata in the .hoodie/ directory as a sequence of “instants” on a timeline. Each instant represents an operation (commit, compaction, rollback, clean) and transitions through three states: REQUESTED, INFLIGHT, and COMPLETED.
The timeline is split into two parts:
Active timeline contains recent instants that are needed for current read and write operations. The file naming pattern is <timestamp>.<action_type>.<state>. For example, 20250429010500.commit.completed indicates a completed write operation.
Archived timeline contains older instants that have been moved to .hoodie/archived/ to keep the active timeline lean. Hudi 1.0 introduced an LSM-based timeline that compacts archived instants into Parquet files for efficient long-term storage.
Hudi’s timeline tracks more granular operation types than other formats: commit (COW write), delta_commit (MOR write), compaction, clean (garbage collection), rollback, savepoint, and replace (clustering). This granularity reflects Hudi’s focus on complex write patterns like CDC pipelines.
Apache Paimon: Snapshots and LSM Trees
Paimon’s metadata is organized around snapshots and buckets. Each partition is divided into a fixed number of buckets, and each bucket contains an independent LSM (Log-Structured Merge) tree.
The snapshot metadata tracks which data files and changelog files belong to each bucket at each point in time. Inside each bucket, the LSM tree structure contains multiple “sorted runs” (levels) of Parquet files. When data is written, it lands in level 0 as a small sorted file. Background compaction merges small files into larger ones at higher levels.
This is fundamentally different from the other formats because Paimon’s metadata structure is designed for continuous streaming writes rather than batch commits. The LSM tree handles high-frequency inserts and updates efficiently by buffering writes in memory and flushing them as sorted runs.
DuckLake: SQL Database as Metadata
DuckLake takes the most radical departure. Instead of storing metadata as files in object storage, all metadata lives in a traditional SQL database (PostgreSQL, MySQL, SQLite, or DuckDB itself).
The metadata database contains tables for: schemas, snapshots, data files, column statistics, and table properties. When a query engine needs to plan a query, it issues a single SQL query against the metadata database instead of reading multiple metadata files from object storage.
The tradeoff is a dependency on a running database process for metadata management. The benefit is dramatically simpler metadata access patterns and the ability to use SQL for metadata operations like listing snapshots, finding files, and checking statistics.
Side-by-Side Comparison
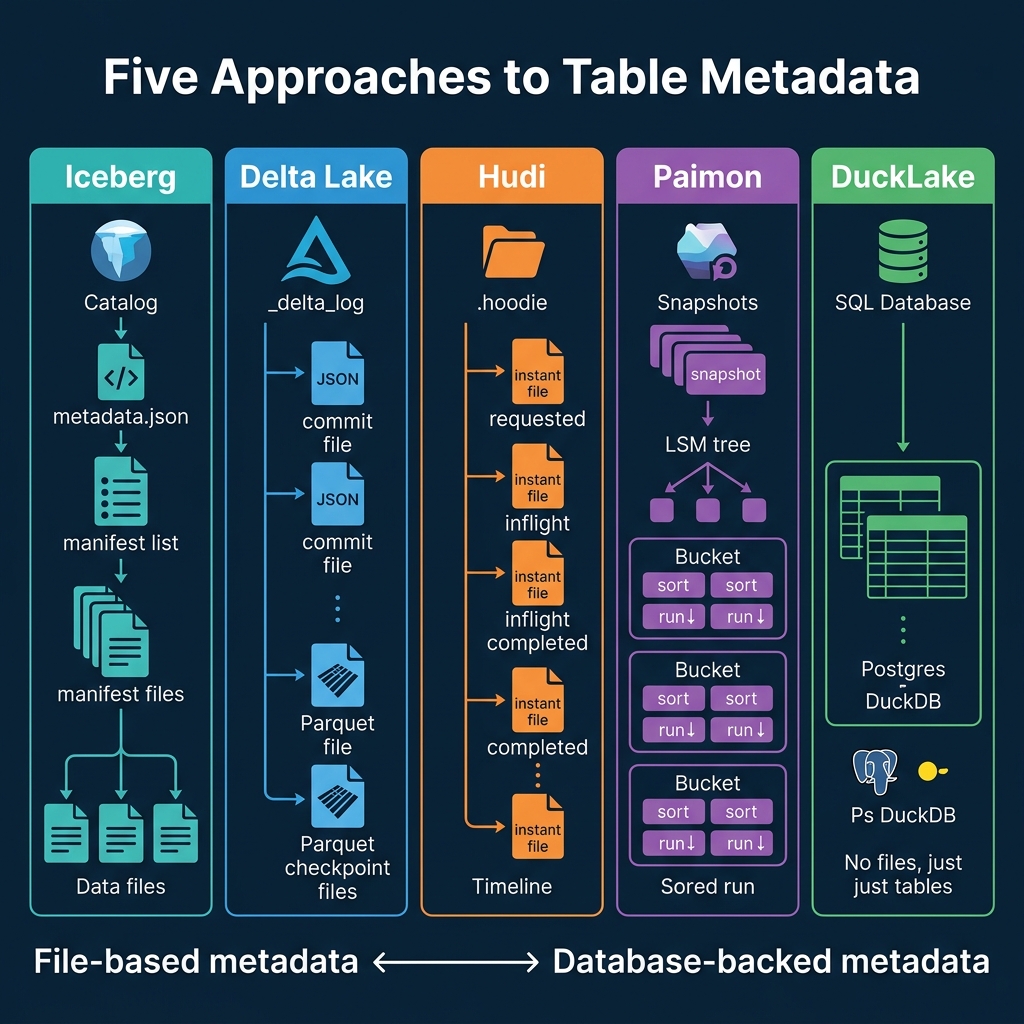
| Dimension | Iceberg | Delta Lake | Hudi | Paimon | DuckLake |
|---|---|---|---|---|---|
| Metadata format | JSON + Avro files | JSON + Parquet files | Avro instant files | Snapshot + LSM files | SQL database tables |
| Metadata location | Object storage | _delta_log/ directory | .hoodie/ directory | Table directory | External database |
| Multi-level pruning | Yes (manifest list + manifests) | No (flat file list) | Partial (index-based) | No (bucket-level) | Via SQL queries |
| Planning overhead | Low (tree traversal) | Moderate (checkpoint + replay) | Moderate (timeline scan) | Low (snapshot lookup) | Lowest (single SQL query) |
| Metadata growth | Controlled (manifest reuse) | Requires checkpointing | Requires archiving | Requires compaction | Database manages it |
| Engine independence | High (spec-defined) | Moderate (Spark-oriented) | Moderate | Low (Flink-oriented) | Low (DuckDB-oriented) |
For teams building on multiple engines, Iceberg’s metadata structure provides the best combination of planning efficiency and engine independence. Dremio uses Iceberg’s metadata tree to achieve fast query planning even on tables with millions of files, and its Columnar Cloud Cache caches frequently-accessed metadata locally to further reduce planning latency.
Part 3 covers how query engines use Iceberg’s metadata specifically for performance optimization.
Books to Go Deeper
- Architecting the Apache Iceberg Lakehouse by Alex Merced (Manning)
- Lakehouses with Apache Iceberg: Agentic Hands-on by Alex Merced
- Constructing Context: Semantics, Agents, and Embeddings by Alex Merced
- Apache Iceberg & Agentic AI: Connecting Structured Data by Alex Merced
- Open Source Lakehouse: Architecting Analytical Systems by Alex Merced


