What Are Lakehouse Catalogs? The Role of Catalogs in Apache Iceberg

Read the complete Apache Iceberg Masterclass series:
- Part 1: What Are Table Formats and Why Were They Needed?
- Part 2: The Metadata Structure of Modern Table Formats
- Part 3: Performance and Apache Iceberg’s Metadata
- Part 4: Partition Evolution: Change Your Partitioning Without Rewriting Data
- Part 5: Hidden Partitioning: How Iceberg Eliminates Accidental Full Table Scans
- Part 6: Writing to an Apache Iceberg Table: How Commits and ACID Actually Work
- Part 7: What Are Lakehouse Catalogs? The Role of Catalogs in Apache Iceberg
- Part 8: When Catalogs Are Embedded in Storage
- Part 9: How Data Lake Table Storage Degrades Over Time
- Part 10: Maintaining Apache Iceberg Tables: Compaction, Expiry, and Cleanup
- Part 11: Apache Iceberg Metadata Tables: Querying the Internals
- Part 12: Using Apache Iceberg with Python and MPP Query Engines
- Part 13: Approaches to Streaming Data into Apache Iceberg Tables
- Part 14: Hands-On with Apache Iceberg Using Dremio Cloud
- Part 15: Migrating to Apache Iceberg: Strategies for Every Source System This is Part 7 of a 15-part Apache Iceberg Masterclass. Part 6 covered the write process and explained how the catalog enables atomic commits. This article covers what catalogs are, why they matter, and how to choose between the many options available in 2026.
A lakehouse catalog is the component that answers one question: “Where is the current metadata for this table?” Without a catalog, every engine would need to independently locate and track metadata files. With a catalog, there is a single source of truth that coordinates reads, writes, and access control across all engines.
What a Catalog Does
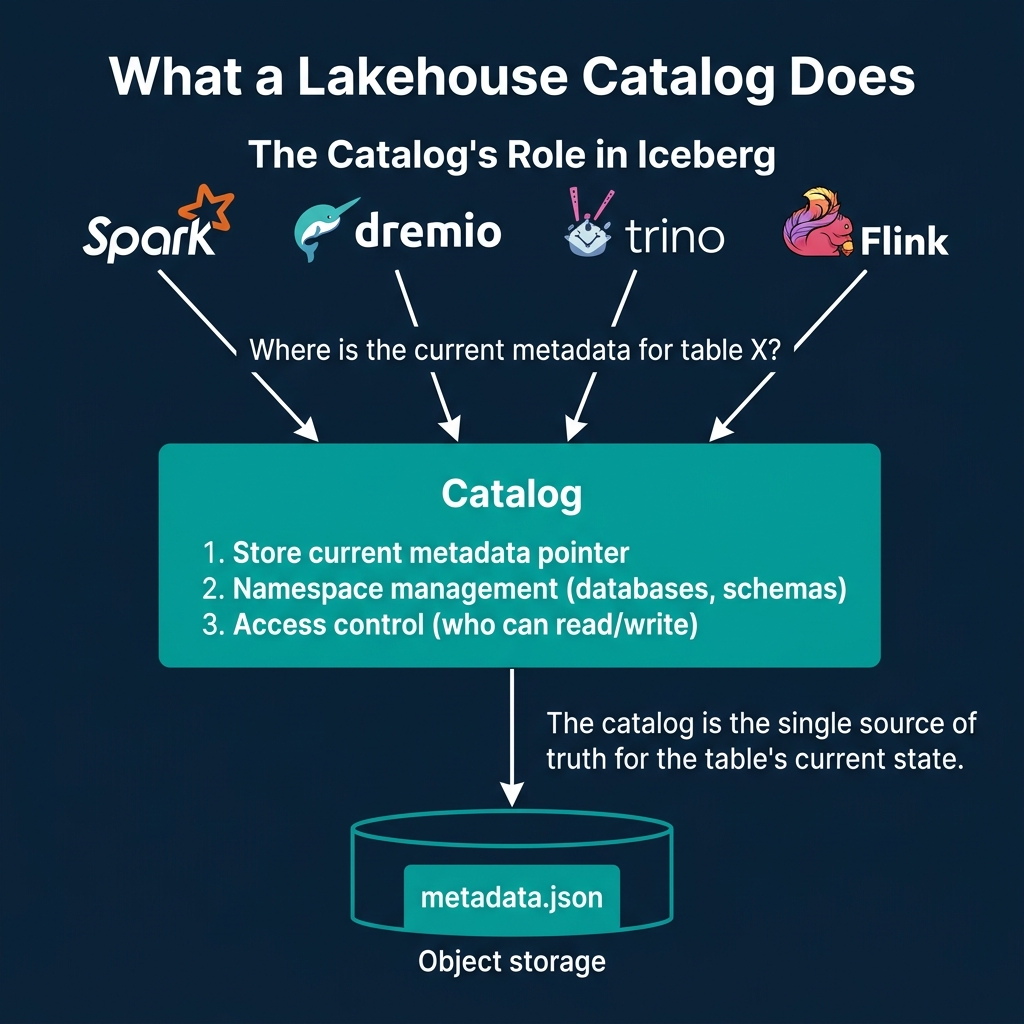
Every Iceberg catalog performs three functions:
Store the current metadata pointer. When a query engine asks for table analytics.orders, the catalog returns the location of the current metadata.json file (e.g., s3://warehouse/orders/metadata/v42.metadata.json). This is the most fundamental responsibility. As described in Part 6, the atomic update of this pointer is what makes ACID transactions possible.
Manage namespaces. Catalogs organize tables into hierarchical namespaces (databases, schemas). This provides logical organization (production.analytics.orders vs staging.analytics.orders) and is the foundation for access control.
Enforce access control. Catalogs determine which users and engines can read, write, or manage specific tables and namespaces. This ranges from simple table-level permissions to fine-grained column-level and row-level security.
The REST Catalog Protocol
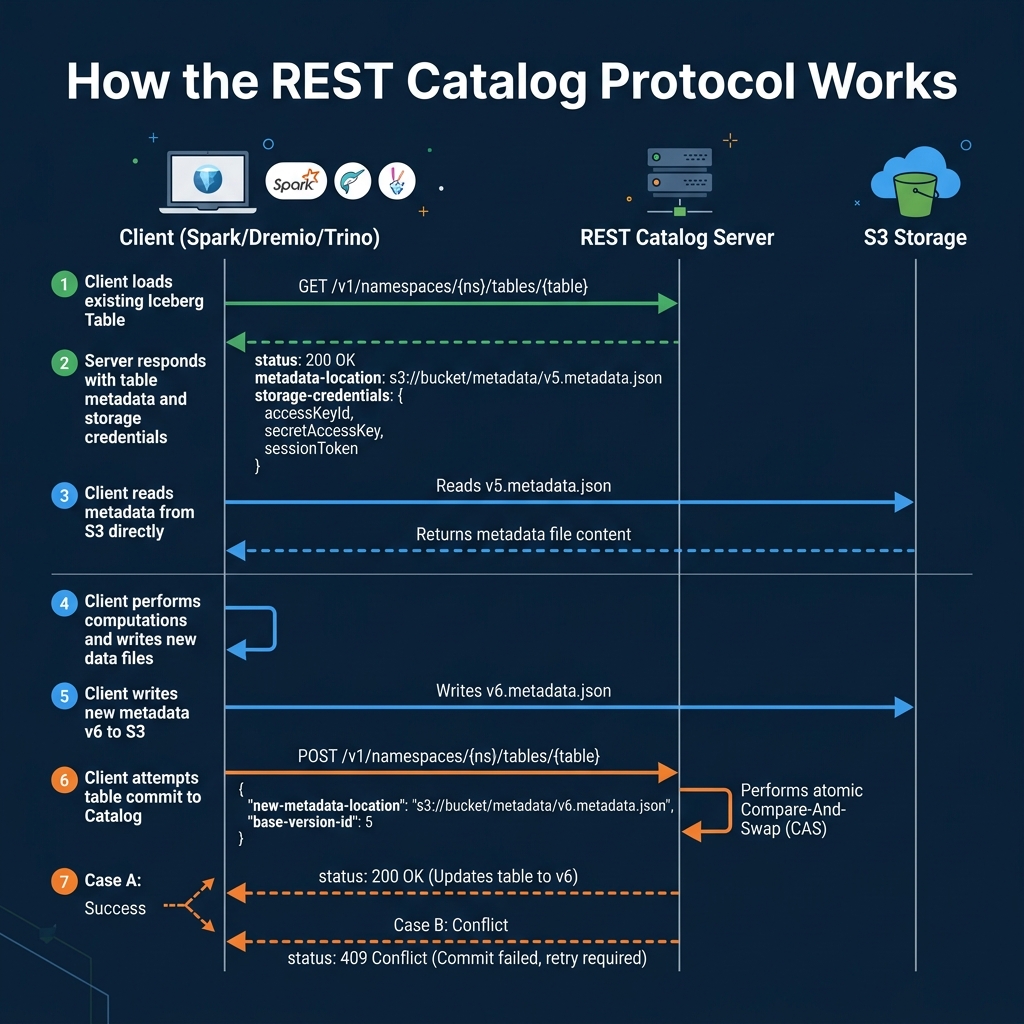
The Iceberg REST Catalog specification defines a standard HTTP API for catalog operations. This protocol has become the industry standard because it decouples the catalog implementation from the engine.
The key operations:
| Endpoint | Purpose |
|---|---|
GET /v1/namespaces/{ns}/tables/{table} | Load table metadata location |
POST /v1/namespaces/{ns}/tables | Create a new table |
POST /v1/namespaces/{ns}/tables/{table} | Commit a table update (CAS) |
GET /v1/namespaces | List available namespaces |
DELETE /v1/namespaces/{ns}/tables/{table} | Drop a table |
The protocol includes credential vending: the catalog returns short-lived storage credentials alongside the metadata location, so the engine can access the data files directly without needing permanent storage credentials. This is important for multi-tenant environments where Dremio and other engines need scoped access to specific tables.
Why the REST Protocol Matters
Before the REST catalog specification, every engine needed a custom integration for each catalog type. Spark had its own Hive Metastore connector, Trino had a different one, and adding a new catalog meant updating every engine. The REST protocol standardizes this: any engine that speaks REST can talk to any catalog that implements the specification.
This is what makes the Iceberg ecosystem genuinely multi-engine. You can use Spark for ETL, Dremio for interactive analytics, Trino for exploration, and Flink for streaming, all pointed at the same REST catalog. Each engine sees the same tables, the same schemas, and the same snapshots.
Multi-Engine Coordination
When multiple engines share a catalog, the catalog becomes the coordination point for concurrent access. The atomic compare-and-swap mechanism ensures that two engines writing to the same table cannot corrupt each other’s commits. This is fundamentally different from file-system-based metastores where coordination relies on file renames that may not be atomic on object storage.
Governance Portability
One of the biggest concerns in the catalog landscape is governance portability. Access control policies (who can query what) are defined in the catalog, but there is no industry standard for sharing these policies across catalogs. If you set up row-level security in one catalog, that policy does not automatically transfer to another.
This is why many architects recommend picking a catalog that will serve as the single governance boundary and having all engines connect through it, rather than having multiple catalogs with duplicate governance rules.
The Catalog Landscape
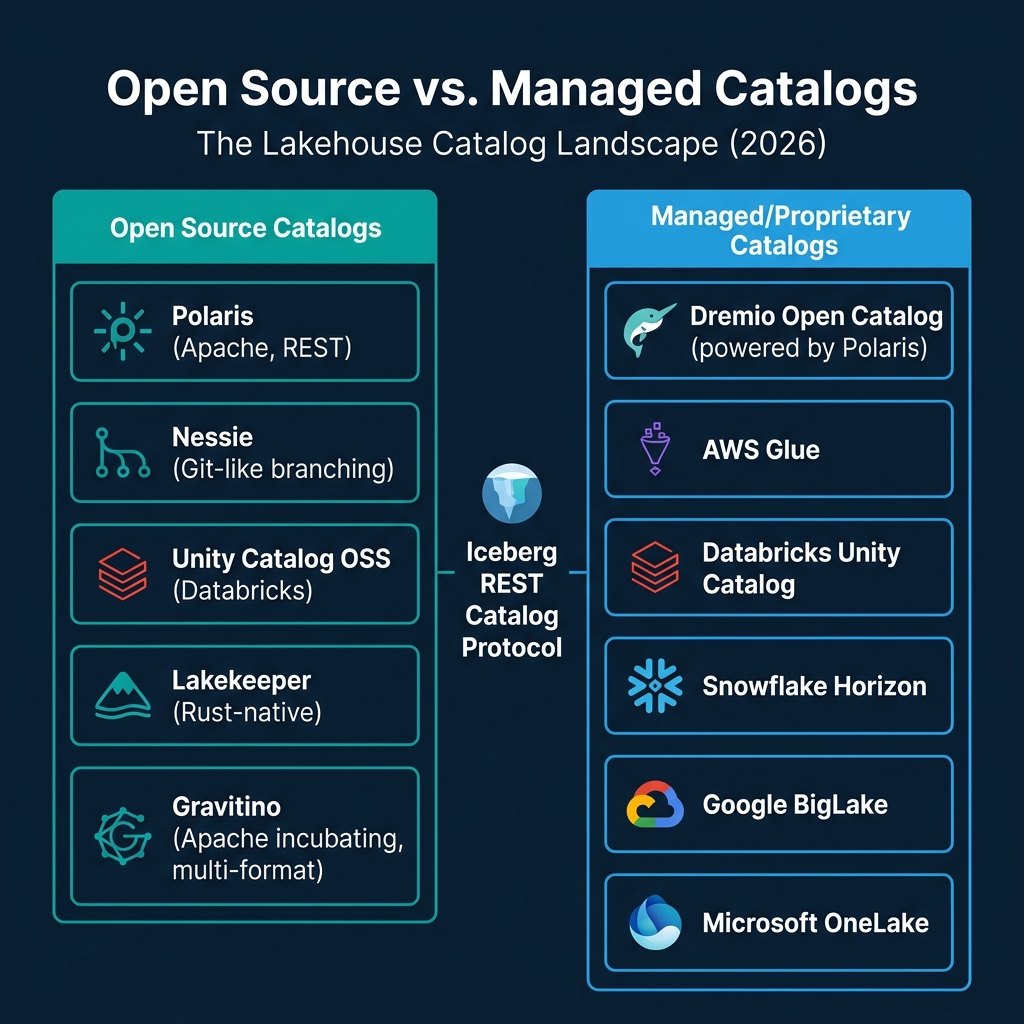
Open Source Catalogs
Apache Polaris (Apache Incubating). The leading vendor-neutral REST catalog implementation. Co-created by Snowflake and Dremio, Polaris is designed to be engine-agnostic and cloud-agnostic. It implements the full REST Catalog spec with fine-grained access control and credential vending. It is the foundation for Dremio’s Open Catalog.
Nessie. Differentiates itself with Git-like branching and merging for data. You can create branches, make changes to multiple tables, and merge them atomically. This is useful for testing pipeline changes or implementing multi-table transactions.
Unity Catalog OSS. Databricks’ open-source catalog offering. It provides multi-format support (Delta, Iceberg, Hudi) and includes AI/ML asset management (models, features). Closely tied to the Databricks ecosystem.
Lakekeeper. A lightweight, Rust-native REST catalog implementation focused on performance and minimal operational footprint. Good for teams that want a self-hosted catalog without the complexity of larger platforms.
Apache Gravitino (Incubating). A federation-focused catalog that can bridge multiple underlying catalogs and storage systems. Designed for organizations that need a unified metadata view across multiple Iceberg catalogs, Hive metastores, and other data sources.
Managed Catalogs
Dremio Open Catalog. A managed Polaris-based catalog that includes automatic table optimization (compaction, snapshot expiry, orphan cleanup) and integrates with Dremio’s query engine, semantic layer, and AI capabilities.
AWS Glue. Amazon’s managed metastore service. Widely used because it is integrated with the AWS ecosystem (Athena, EMR, Redshift Spectrum). Supports Iceberg tables natively and acts as both a Hive-compatible metastore and an Iceberg catalog.
Databricks Unity Catalog (managed). The enterprise version of Unity Catalog with additional governance features, lineage tracking, and AI asset management. Tightly integrated with the Databricks runtime.
Snowflake Horizon. Snowflake’s catalog and governance layer that supports Iceberg tables in Snowflake-managed storage.
Google BigLake. Google Cloud’s managed metadata service for Iceberg tables on GCS.
Microsoft OneLake. Microsoft’s unified storage and catalog layer within the Fabric ecosystem.
How to Choose a Catalog
The decision depends on three factors:
| Priority | Recommended Approach |
|---|---|
| Multi-engine, vendor-neutral | REST catalog (Polaris or Lakekeeper) |
| AWS-native, minimal ops | AWS Glue |
| Databricks ecosystem | Unity Catalog |
| Git-style data versioning | Nessie |
| Managed with auto-optimization | Dremio Open Catalog |
| Multi-catalog federation | Gravitino |
The safest long-term choice is a REST-catalog-compatible implementation because every major engine supports the protocol. If you start with a REST catalog, you can swap implementations later without changing your engine configurations.
Catalogs Are Not Optional
Some teams try to use Iceberg without a proper catalog, relying on Hadoop-style file system catalogs that use file renames for atomicity. This works on HDFS but is unreliable on object storage (S3 does not support atomic renames). For production lakehouses on cloud storage, a proper catalog with server-side compare-and-swap is essential.
Part 8 covers a newer approach where the catalog is embedded directly in the storage layer.
Books to Go Deeper
- Architecting the Apache Iceberg Lakehouse by Alex Merced (Manning)
- Lakehouses with Apache Iceberg: Agentic Hands-on by Alex Merced
- Constructing Context: Semantics, Agents, and Embeddings by Alex Merced
- Apache Iceberg & Agentic AI: Connecting Structured Data by Alex Merced
- Open Source Lakehouse: Architecting Analytical Systems by Alex Merced


